本文转载自简书https://www.jianshu.com/p/22c50ded4cf7
写在前面
在训练神经网络的时候,我们难免会看到Batch、Epoch和Iteration这几个概念。曾对这几个概念感到模糊,看了网上的一些文章后,在这里做几个小小的总结。
名词解释:

【 图片来源:https://zhuanlan.zhihu.com/p/29409502 】
- Epoch(时期):
当一个完整的数据集通过了神经网络一次并且返回了一次,这个过程称为一次>epoch。(也就是说,所有训练样本在神经网络中都 进行了一次正向传播 和一次反向传播 )
再通俗一点,一个Epoch就是将所有训练样本训练一次的过程。
然而,当一个Epoch的样本(也就是所有的训练样本)数量可能太过庞大(对于计算机而言),就需要把它分成多个小块,也就是就是分成多个Batch 来进行训练。
- Batch(批 / 一批样本):
将整个训练样本分成若干个Batch。
- Batch_Size(批大小):
每批样本的大小。
- Iteration(一次迭代):
训练一个Batch就是一次Iteration(这个概念跟程序语言中的迭代器相似)。
- 为什么要使用多于一个epoch?
在神经网络中传递完整的数据集一次是不够的,而且我们需要将完整的数据集在同样的神经网络中传递多次。但请记住,我们使用的是有限的数据集,并且我们使用一个迭代过程即梯度下降来优化学习过程。如下图所示。因此仅仅更新一次或者说使用一个epoch是不够的。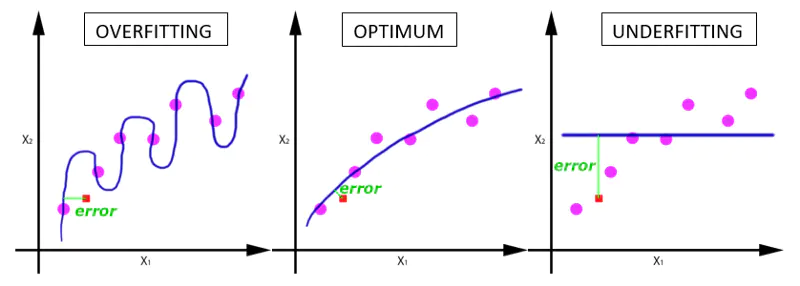
随着epoch数量增加,神经网络中的权重的更新次数也在增加,曲线从欠拟合变得过拟合。
- 那么,问题来了,几个epoch才是合适的呢?
不幸的是,这个问题并没有正确的答案。对于不同的数据集,答案是不一样的。但是数据的多样性会影响合适的epoch的数量。比如,只有黑色的猫的数据集,以及有各种颜色的猫的数据集。
【 来源:https://blog.csdn.net/qq_39521554/article/details/84480429 】
换算关系:
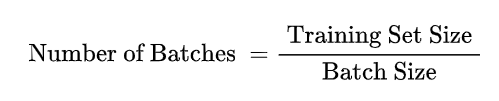
实际上,梯度下降的几种方式的根本区别就在于上面公式中的 Batch_Size 不同。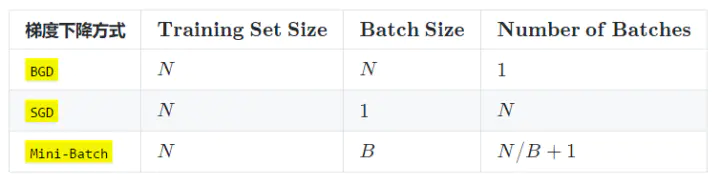
【 图片来源:https://zhuanlan.zhihu.com/p/29409502 】
举个例子:
mnist 数据集有60000张图片作为训练数据,10000张图片作为测试数据。假设现在选择 Batch_Size = 100对模型进行训练。迭代30000次。
- 每个 Epoch 要训练的图片数量:60000(训练集上的所有图像)
- 训练集具有的 Batch 个数: 60000/100=600
- 每个 Epoch 需要完成的 Batch 个数:600
- 每个 Epoch 具有的 Iteration 个数:600(完成一个Batch训练,相当于参数迭代一次)
- 每个 Epoch 中发生模型权重更新的次数:600
- 训练 10 个Epoch后,模型权重更新的次数: 600*10=6000
- 不同Epoch的训练,其实用的是同一个训练集的数据。第1个Epoch和第10个Epoch虽然用的都是训练集的60000图片,但是对模型的权重更新值却是完全不同的。因为不同Epoch的模型处于代价函数空间上的不同位置,模型的训练代越靠后,越接近谷底,其代价越小。
- 总共完成30000次迭代,相当于完成了30000/600=50个Epoch
【 来源:https://blog.csdn.net/xiaohuihui1994/article/details/80624593 】【 来源:https://blog.csdn.net/xiaohuihui1994/article/details/80624593 】
本文来自博客园,作者:阿儒さん,转载请注明原文链接:https://www.cnblogs.com/changziru/p/17278542.html