目录
- 前言
- 任务的描述
- FutureTask的设计与实现
- FutureTask状态机
- FutureTask几个关键方法
- ThreadPoolExecutor的设计与实现
- 简介
- 类的描述与状态
- ThreadPoolExecutor字段描述
- ThreadPoolExecutor状态描述
- Worker字段描述
- Worker状态描述
- 任务的提交与调度
- 工作线程的创建与执行
- 工作线程的创建
- 工作线程的执行
- 服务的关闭,任务的取消与线程的回收
- 服务的关闭
- 线程的回收
- 线程的中断
- 线程池的使用
- 1 核心线程数与最大线程数
- 1.1 工作线程的大小设置
- 1.2 工作线程的回收
- 2 任务队列
- 3 任务拒绝策略
- 4 工作线程工厂类
- JDK平台提供的默认线程池
- 实际业务中的使用
- 1 核心线程数与最大线程数
- 总结
- 参考资料
前言
在我们实际工作过程中,往往会将大的任务划分成几个小的子任务,待所有子任务完成之后,再整合出大任务的结果.(例如: 新增直播课的场景),任务的性质通常是多种多样的,这里列举一些任务的常见性质.
从资源使用的角度:
- CPU密集型 (枚举素数)
- I/O密集型 (文件上传下载)
从执行过程的角度:
- 依赖其他有限资源(数据库连接池,文件描述符)/不依赖其他有限资源
- 没有返回值(写日志,logService,MesageService)
- 有返回值(计算结果)
- 处理过程中可能抛异常(异常要如何处理)
- 可取消的任务/不可取消的任务
从执行时间的角度:
- 执行时间短(枚举100以内的素数)
- 执行时间长(数据库调用)
- 永远无法结束(爬虫任务)
- 限时任务,需要尽快响应(H5端接口,GUI点击事件)
- 定时任务(Job)
任务是对现实问题的抽象,其对应程序中的某些方法,而方法的执行需要调用栈.
从Java内存模型图中可以看出,Java线程为任务的执行提供了所需的方法调用栈,其中包括本地方法调用栈和Java方法调用栈,在32位系统中通常占0.5M,而在64位系统中通常占1M+10几KB的内核数据结构.
而且有的操作系统也会对一个进程能创建的线程数量进行限制. 因此我们并不能无限制的创建线程,线程是一种共享资源,需要统一维护和调度,以便使资源利用率更加高效,这便有了线程池的概念.
Java内存模型图: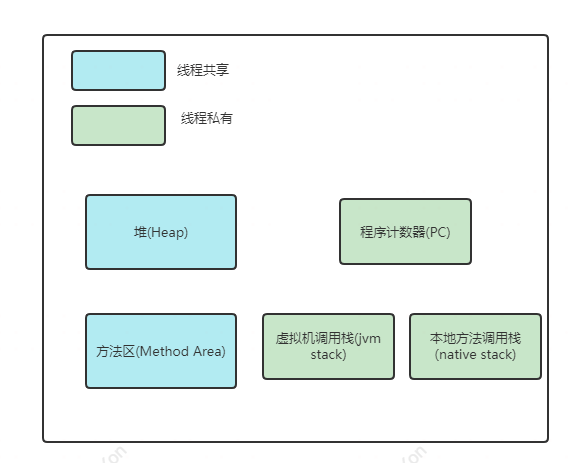
注: 很多服务端的应用程序比如MySQL,Web服务器都使用了线程池技术.
然而也有例外,对于耗时较短的任务,比如仅有内存操作,导致线程的维护时间/任务的执行时间比值偏大,这类任务就不适合使用多线程技术,例如Redis服务.
或者对于需要确保线程安全性的,比如GUI开发包,也是使用单线程,例如Swing开发包,JavaScript等.
对于任务的执行,我们往往会有许多需求,例如观察任务的执行状态,获取任务的执行结果或者执行过程中抛出的异常信息,而对于长时间执行的任务,可能还会需要暂停任务,取消任务,限时等
jdk中有许多执行时间长的任务,例如,Thread.join, Object.wait, BlockingQueue.poll,Future.get,这些任务的接口设计也体现了这些需求例如lock接口:
public void lock(); //基于状态的接口,当无法获取锁时,挂起当前线程public void lockInterruptibly() throws InterruptedException; // 通过抛出中断异常来响应中断public boolean tryLock();//用于快速判断释放可加锁,用于轮询public boolean tryLock(long timeout, TimeUnit unit) throws InterruptedException; //可限时的操作下面列举一些任务的执行需要考虑的问题.
任务的执行策略:
- 任务在什么线程中执行
- 任务的执行顺序,FIFO还是按优先级
- 多少个任务可以并发执行
- 任务过多导致系统过载,选择拒绝哪个任务,即任务的拒绝策略
- 如何通知应用程序有任务被拒绝
- 如何通知应用程序任务的执行结果,包括成功的结果和失败的结果
为了应对这些繁杂的现实需求,jdk为我们提供了Executor框架.通过这个中间人,将任务的提交和实际执行策略解耦,并且提供了对生命周期的支持(ExecutorService),客户端只需要关注任务的构建和任务的提交,由中间人来关注实际的执行策略。从而封装了任务执行的复杂性。
本文主要介绍Java平台提供的Executor执行框架,其中Runable表示任务,FutureTask表示任务的执行结果,ThreadPoolExecutor表示具体的任务执行策略.
任务的描述
Executor框架中,Runable接口表示任务,但是这个任务没有返回值且不能抛出异常,而Callable接口却可以.所以Executors工具类提供了RunableAdapter适配器,通过callalbe(Runable)方法,将 runable转为 callable.
| 任务 | 描述 |
|---|---|
| Runnable | 可执行的任务,无返回值,不可抛出异常 |
| Callable | 可执行的任务,有返回值,可以抛出异常 |
| FutureTask | 可执行的任务,可以管理任务的执行状态和读取任务的执行结果 |
为了对任务维护任务的运行状态以及异步获取任务的运行结果,Executor框架提供了Future类,该类表示一个异步任务的计算结果.提供了一些方法:
- 获取任务执行结果 get(), get(long,TimeUnit)
- 取消任务 cancel(boolean)
- 判断任务是否取消,判断任务是否完成 isCancelled(),isDone()
同时也提供了内存一致性保证: Future.get()之前的操作, happen-before Future.get()之后的操作
FutureTask实现了Future接口和Runable接口,表示一个可取消的任务,AbstractExecutorService正是通过将Runable封装成FutureTask,来管理和维护任务的状态以及获取任务的执行结果,下面介绍jdk1.8中FutureTask的实现.
AbstractExecutorService:protected RunnableFuture newTaskFor(Runnable runnable, T value) { return new FutureTask(runnable, value); }public Future submit(Runnable task) { if (task == null) throw new NullPointerException(); RunnableFuture ftask = newTaskFor(task, null); execute(ftask); return ftask; }FutureTask的设计与实现
在jdk1.8之前的版本中为了简介,依赖AQS来实现FutureTask,但在jdk1.8后,则放弃使用,通过WaitNode链表,来维护等待结果的线程.
FutureTask源码
public class FutureTask implements RunnableFuture { /* * FutureTask是一个并发安全类,有并发控制机制 * 先前版本为了简洁,使用AQS来实现,jdk1.8后的并发控制使用 一个state 域,通过CAS操作state,同时通过一个简单的stack来维护 waiting threads*/ private volatile int state; // 实际的任务 private Callable callable; // 任务的执行结果或者抛出的异常,通过get()获取这个字段 // 不需要 volatile,不会有并发读写该字段的情况 private Object outcome; // 在run()的时候 会set runner private volatile Thread runner; // 一个简单的等待队列,为什么不用AQS了? AQS太重了 private volatile WaitNode waiters; static final class WaitNode { volatile Thread thread; volatile WaitNode next; WaitNode() { thread = Thread.currentThread(); } }}FutureTask状态机
了解了一个类的状态机,也就大致了解了类的工作过程,FutureTask的状态机如下所示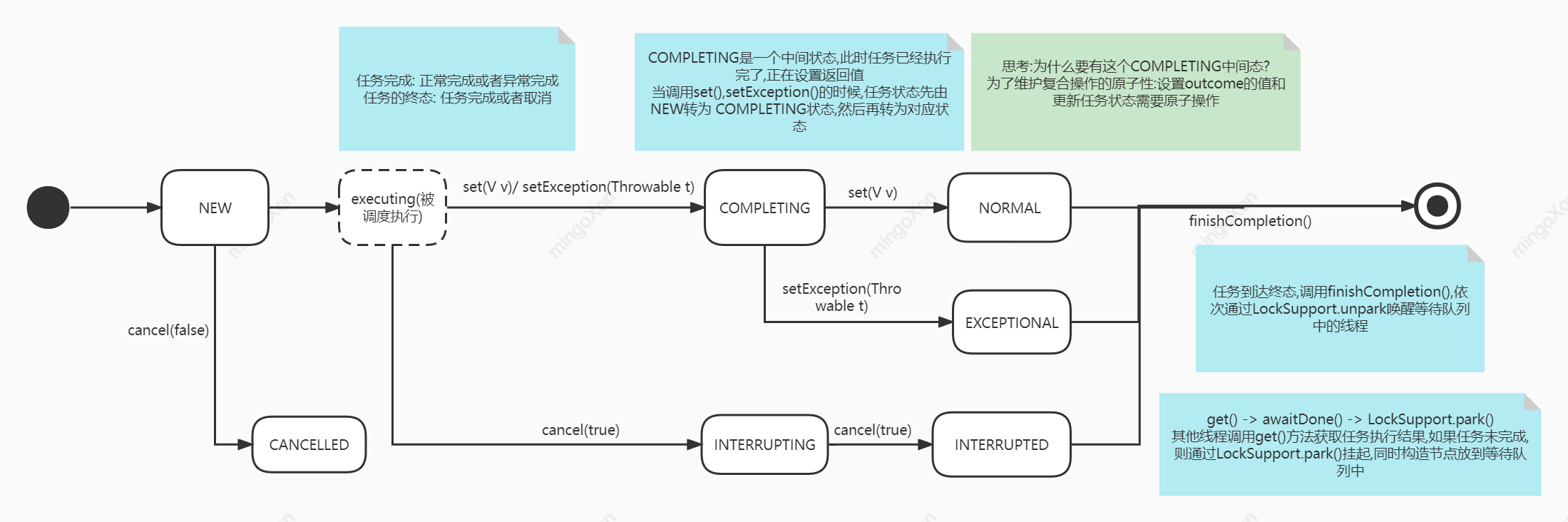
| 状态 | 描述 |
|---|---|
| NEW | 初始任务状态 |
| COMPLETING | 任务已执行完,正在设置outcome |
| NORMAL | 任务正常执行完成 |
| EXCEPTIONAL | 任务执行过程中抛出异常,工作线程终止 |
| INTERRUPTED | 执行任务的工作线程收到中断请求 |
思考一个问题,为什么要有一个COMLETING中间态?
为了维护复合操作的原子性:设置outcome的值和更新任务状态需要原子操作 protected void set(V v) { // 通过CAS先check下,确保状态转换是原子op,同时也确保outcome=v 和设置状态的值这一对复合操作的原子性 if (UNSAFE.compareAndSwapInt(this, stateOffset, NEW, COMPLETING)) { // 进来后就是单线程环境了 outcome = v; UNSAFE.putOrderedInt(this, stateOffset, NORMAL); // final state finishCompletion(); } }FutureTask几个关键方法
run(),cancel(),awaiDone()
public void run() { // 先验条件 if (state != NEW || // set runner !UNSAFE.compareAndSwapObject(this, runnerOffset, null, Thread.currentThread())) return; try { Callable c = callable; if (c != null && state == NEW) { V result; boolean ran; try { result = c.call(); ran = true; } catch (Throwable ex) { // 任务执行出错 result = null; ran = false; setException(ex); } if (ran) // 执行成功 set outcome set(result); } } finally { // runner must be non-null until state is settled to // prevent concurrent calls to run() runner = null; // state must be re-read after nulling runner to prevent // 确保不会丢失中断信号 // leaked interrupts int s = state; if (s >= INTERRUPTING) handlePossibleCancellationInterrupt(s); } } public boolean cancel(boolean mayInterruptIfRunning) { // cancel: new -> interrupting->interrupted,或者 new -> cancelled if (!(state == NEW && UNSAFE.compareAndSwapInt(this, stateOffset, NEW, mayInterruptIfRunning ? INTERRUPTING : CANCELLED))) // check then action, 复合操作, 如果失败则说明此时任务的状态不是 new了,返回false,即取消失败 return false; try { // in case call to interrupt throws exception if (mayInterruptIfRunning) { try { Thread t = runner; // 通过给 执行该任务的线程 发送中断信号来取消任务 if (t != null) t.interrupt(); } finally { // final state // 发送完后默认置为 interrupted, 表示 信号已发过去了,但任务不一定能停下来,需要任务自己判断这个信号 UNSAFE.putOrderedInt(this, stateOffset, INTERRUPTED); } } } finally { finishCompletion(); } return true; } public V get() throws InterruptedException, ExecutionException { int s = state; if (s = CANCELLED) throw new CancellationException(); throw new ExecutionException((Throwable) x); } /** * 可中断的方法 * Awaits completion or aborts on interrupt or timeout. * * @param timed true if use timed waits * @param nanos time to wait, if timed * @return state upon completion */ private int awaitDone(boolean timed, long nanos) throws InterruptedException { final long deadline = timed ? System.nanoTime() + nanos : 0L; WaitNode q = null; boolean queued = false; for (;;) { // 可中断方法的大部分实现,都是通过抛InterruptedException()来响应中断,注意Thread.interrupted()会清除中断信号 if (Thread.interrupted()) { removeWaiter(q); throw new InterruptedException(); } int s = state; // 如果任务 达到了终态,即isDone()了, 即 S>COMPLETIOG,返回 isDone() => s>competing if (s > COMPLETING) { if (q != null) q.thread = null; return s; // 正在写结果, 马上就结束了 } else if (s == COMPLETING) // cannot time out yet Thread.yield(); else if (q == null) // 任务还未开始, 即 s=NEW 时,此时创建 等待线程节点,再过一次前面的操作 到下一步 q = new WaitNode(); else if (!queued) // 新增的节点未入队,将节点入队,入队成功后再过一次前面的操作 到下一步 queued = UNSAFE.compareAndSwapObject(this, waitersOffset, q.next = waiters, q); else if (timed) { // 如果过了等待时间了,不等了, 把前面构建的节点从等待队列中删除,返回 state nanos = deadline - System.nanoTime(); if (nanos <= 0L) { removeWaiter(q); return state; } // 否则 限时阻塞当前线程,等待任务完成时被唤醒 LockSupport.parkNanos(this, nanos); } else // timed=false时, 永远阻塞当前线程,等待任务完成时被唤醒 LockSupport.park(this); } }ThreadPoolExecutor的设计与实现简介
ThreadPoolExecutor = ThreadPool + Executor
Executor: 其中仅有一个execute(Runable) 方法,工作模式为生产者-消费者模式,提交(submit)任务的客户端相当于生成者,执行任务的线程(worker)则相当于消费者。
ThreadPool: 从字面意思来看是一个线程的容器,用于管理和维护工作者线程。线程池的工作与任务队列(work queue)密切相关的,其中任务队列保存了所有等待执行的任务。
ThreadPoolExecutor即以生产者-消费者为工作模型,基于线程池实现的执行器。
由简介我们可以了解到,一般线程池的实现涉及两个关键组件:work queue,workers。而在ThreadPoolExecutor的设计和实现中,其分别对应BlockingQueue接口,Worker类。
| 线程池的实现所需关键组件 | ThreadPoolExecutor |
|---|---|
| work queue | BlockingQueue |
| worker | final class Worker extends AbstractQueuedSynchronizer implements Runnable{} |
接下来将从四个方面入手,介绍ThreadPoolExecutor的设计与实现,体会大师们(Doug Lea与JCP Expert Group)是如何思考和解决线程池问题的。
- 类的结构与状态
- 任务的提交与调度
- 线程的创建与执行
- 服务的关闭,任务的取消,线程的回收
类的描述与状态
在开始介绍ThreadPoolExecutor前,有必要先了解下Executor框架的其他组成部分。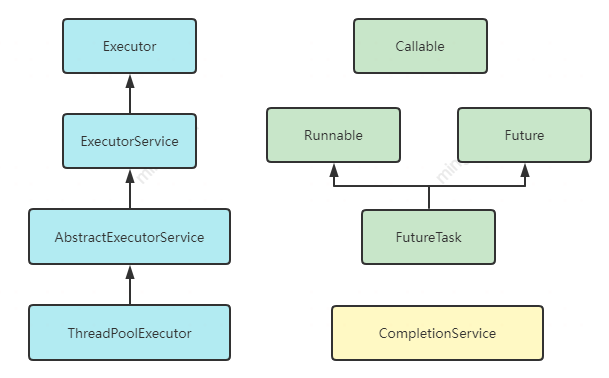
Executor接口:框架的核心接口,其中只包含一个execute方法
public interface Executor { /** * @throws RejectedExecutionException if this task cannot be accepted for execution * @throws NullPointerException if command is null */ void execute(Runnable command);}ExecutorService接口:线程池作为一个服务需要有服务的状态维护等操作,这些操作被放到了这个接口,例如shutdown(),shutdownNow(),awaitTermination(),这里也给出了服务关闭方法。
public static void shutdownAndAwaitTermination(ExecutorService pool) { pool.shutdown(); // Disable new tasks from being submitted try { // Wait a while for existing tasks to terminate if (!pool.awaitTermination(60, TimeUnit.SECONDS)) { pool.shutdownNow(); // Cancel currently executing tasks // Wait a while for tasks to respond to being cancelled if (!pool.awaitTermination(60, TimeUnit.SECONDS)) System.err.println("Pool did not terminate"); } } catch (InterruptedException ie) { pool.shutdownNow(); // Preserve interrupt status Thread.currentThread().interrupt(); } }AbstractExecutorService类: 提供ExecutorService的基本实现。例如:通过将任务封装成FutureTask,实现submit方法。任务的批量执行方法:invokeAll,invokeAny的通用实现等。
protected RunnableFuture newTaskFor(Callable callable) { return new FutureTask(callable); } /** 注意这里已经说明了该接口可能会抛出此异常,但我们常常会忘记处理此异常而导致报错,但我们却记得NPE的处理 * @throws RejectedExecutionException * @throws NullPointerException */ public Future submit(Runnable task) { if (task == null) throw new NullPointerException(); RunnableFuture ftask = newTaskFor(task, null); execute(ftask); return ftask; }ThreadPoolExecutor字段描述
ThreadPoolExecutor字段
“`public class ThreadPoolExecutor extends AbstractExecutorService { /** * ctl(the main pool control state):用于维护了以下两个字段的值 * workCount: 存活着的线程数 低29位,大概5亿 * runState: 高3位 线程池服务的状态: RUNNING(-1),SHUTDOWN(0),STOP(1),TIDYING(2),TERMINATED(3) */ private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0)); private static final int COUNT_BITS = Integer.SIZE – 3; //如何快速获取n个1? [(1 << n) – 1],CPACITY=29个1 private static final int CAPACITY = (1 < rs | wc; 加法换成位运算,更快一点 :) private static int ctlOf(int rs, int wc) { return rs | wc; } private volatile int corePoolSize; private volatile int maximumPoolSize; private volatile boolean allowCoreThreadTimeOut; /** * idle thread的定义: waiting for work * Timeout in nanoseconds for idle threads waiting for work. * 如果线程池中运行的线程比corePoolSize大,多余的线程会在没有任务的时候的等待keep-alive times,如果在这个时间段内还是没有任务执行,会回收这个线程直到corePoolSize数量(如何回收的? go processWorkerExit), * 注:(这个字段只有当maximumPoolSize大于corePoolSize时有效) */ private volatile long keepAliveTime; // 任务队列 private final BlockingQueue workQueue; /** *新的线程 是通过 ThreadFactory创建的,默认的创建方式是通过Executors.defaultThreadFactory来创建,我们可以使用guava提供的ThreadFactoryBuilder()来创建自定义的线程工厂类 */ private volatile ThreadFactory threadFactory; // 饱和策略 private volatile RejectedExecutionHandler handler; /** * 默认的拒绝策略是在execute()的时候直接抛出异常,使用的时候要记得处理这个异常 */ private static final RejectedExecutionHandler defaultHandler = new AbortPolicy(); /** * 保护worker的锁,为什么不用 concurrent包中的集合,而是使用 HashSet + * Lock呢?在shutdown的时候会发中断信号给idle work, * 如果shutdown被并发执行,那么idle的线程就不停地接受到中断信号(intrrupt storms), * 但是如果使用lock + hashSet的时候,shutdown会先获取锁,然后再发中断信号, * 这样即使shutdown方法被并发调用,后来的调用由于无法获取锁无法发送中断信号,从而避免了中断风暴. * 注:(主要为了确保稳定,而不是性能,所以选择使用HashSet+Lock,而不是 concurrentSet, * workerSet并发访问的场景并不多,除了shutdown,shutdownNow,以及一些统计方法比如 * largestPoolSize外可能并发访问workerSet) */ private final ReentrantLock mainLock = new ReentrantLock(); /** * 维护工作者线程, 只有再获取到mainLock的时候才允许访问(为了线程安全) * @ThreadSafe(mainLock) * 注:([临界区问题](os层面),[data race, race condition](现象分析层面),[不变性条件,先验条件,后验条件,线程安全](类设计层面),[可见性,顺序性,原子性](纯理论层面),复合操作描述的都是同一个事情,即并发程序执行的正确性) */ private final HashSet workers = new HashSet(); /** * awaitTermination的实现,将等待线程放到 condition中维护 */ private final Condition termination = mainLock.newCondition();}“`
ThreadPoolExecutor状态描述
该类主要包含下面几个状态:
| 状态 | 描述 |
|---|---|
| RUNNING | Accept new tasks and process queued tasks |
| SHUTDOWN | Don’t accept new tasks, but process queued tasks |
| STOP | Don’t accept new tasks, don’t process queued tasks |
| TIDYING | All tasks have terminated, workerCount is zero,the thread transitioning to state TIDYING will run the terminated() hook method |
| TERMINATED | terminated() has completed |
ThreadPoolExecutor状态机:
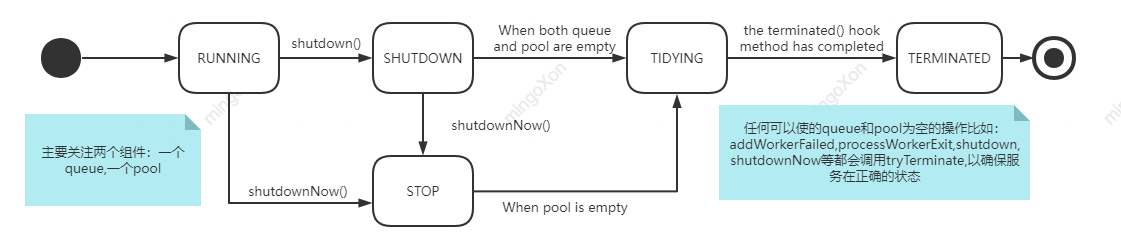
状态间的操作:
| 操作 | 描述 |
|---|---|
| shutdown() | 仅会给idle Worker发送中断信号,会缓慢的结束线程池服务:将queue中的任务都执行完 |
| shutdownNow() | 会给所有Worker发送中断信号,会快速的结束线程池服务(不安全): 尝试中断正在执行任务的线程,同时返回queue中的任务列表 |
| awaitTermination() | 是一个基于状态的方法,将在状态达到TERMINATED时返回,可以用在需要同步判断线程池关闭的场景 |
| 其余方法 | 从图可以看出,任何可以使的queue和pool为空的操作比如:addWorkerFailed,processWorkerExit,shutdown,shutdownNow等都有可能使得状态转为TERMINATE,所以这些方法都会调用tryTerminate(),以确保服务在正确的状态 |
Worker字段描述
点击查看代码
** * 实际的工作者线程,主要维护线程的中断状态 * 这个类为了简化在运行任务的时候对锁的获取和释放,设计成了 extends AQS * 当shutdown的时候,会通过tryLock判断线程是否正在执行任务,如果为false,表示线程不在执行任务,而是在等待新的任务,通过发送中断信号,中断这些线程的等待,这些线程被中断后会判断是由于什么原因唤醒的,如果这个时候线程池状态为SHUTDOWN,那么这些线程就会被回收. * 注:(线程被唤醒的原因可能是被中断了,也有可能是有任务了,也有可能是时间到了,唤醒后需要二次判断go getTask()) * 注:(线程由于没有任务挂起(poll()), 挂起期间可能有新的任务过来了(offer())被唤醒,也有可能被中断信号通知关闭而被唤醒.) */ private final class Worker extends AbstractQueuedSynchronizer implements Runnable { /** * Worker继承了AQS,也就是说Worker还有一个state属性字段,这个字段是有必要分析下的: * -1: 刚初始化 * 0: 刚调用runWorker或者没任务了 * 1: 正在执行任务,正是通过这个state字段,来判断线程是否正在执行任务(tryLock) */ final Thread thread; // 在Worker初始化时,firstTask可能有值 Runnable firstTask; // 每个工作者线程完成的任务数,任务性质可以不同,即线程是可以复用的 volatile long completedTasks; Worker(Runnable firstTask) { // 只有在worker线程已开始的时候中断才有意义,所以在初始化worker的时候state=-1,这个时候不会被中断go isLocked() setState(-1); this.firstTask = firstTask; // 初始化Workder的时候 通过 threadFactory创建线程,最终通过系统调用,由OS创建内核线程 this.thread = getThreadFactory().newThread(this); } // runWorker实际实现主执行循环,接下来就是重点了,任务线程初始化时,拿到了firstTask(有的话),以及一个新的线程,接下来就开始真正地执行任务了 public void run() { runWorker(this); } // 设计worker类的主要目的,用来中断线程 void interruptIfStarted() { Thread t; // 只有在worker线程已开始的时候中断才有意义, 所以在初始化worker的时候state=-1,这个时候不会被中断 if (getState() >= 0 && (t = thread) != null && !t.isInterrupted()) { try { t.interrupt(); } catch (SecurityException ignore) { } } } }Worker状态描述
Worker主要有3个状态
| 状态 | 描述 |
|---|---|
| INIT(-1) | 初始Worker状态 |
| WAINTING TASK(0) | 等待任务到达 |
| RUNING | 正在执行任务 |
Worker状态机如图

任务的提交与调度
在介绍完具体的ThreadPoolExecutor与Worker的描述以及状态机后,我们先来大致看下ThreadPoolExecutor的工作流程,有助于理解后续的操作步骤.

从图中我们可以看出,一个正常执行完成的任务其主要经过submit() -> addWorker()->worker.thread.start()->worker.run()->runWorker()→task.run()等步骤,下面我们具体介绍下这些步骤.
任务调度方法主要在execute,具体源码注释如下:
点击查看代码
public void execute(Runnable command) { if (command == null) throw new NullPointerException(); int c = ctl.get(); // 线程池小于core if (workerCountOf(c) < corePoolSize) { if (addWorker(command, true)) return; c = ctl.get(); } // 新增任务失败,可能在addWorker的时候线程数达到了corePoolSize的水平,此时放到workQueue if (isRunning(c) && workQueue.offer(command)) { int recheck = ctl.get(); // 判断如果线程池正在shutdown,拒绝任务 if (!isRunning(recheck) && remove(command)) reject(command); // 确保任务队列中的任务可以被线程执行 else if (workerCountOf(recheck) == 0) addWorker(null, false); // 工作队列满了,再尝试增加worker,线程个数判断使用 maxvalue } else if (!addWorker(command, false)) reject(command); }工作线程的创建与执行
工作线程的创建主要根据线程池状态,core和maximum参数判断是否可以新增工作线程,如果新增成功,则开始执行任务.
工作线程的创建
点击查看代码
private boolean addWorker(Runnable firstTask, boolean core) { retry: for (;;) { int c = ctl.get(); int rs = runStateOf(c); // Check if queue empty only if necessary. if (rs >= SHUTDOWN && !(rs == SHUTDOWN && firstTask == null && !workQueue.isEmpty())) // 当shutdown且 队列是空的时候就没必要加worker了 return false; for (;;) { int wc = workerCountOf(c); // 达到限制数量了也返回false if (wc >= CAPACITY || wc >= (core ? corePoolSize : maximumPoolSize)) return false; if (compareAndIncrementWorkerCount(c)) break retry; c = ctl.get(); // Re-read ctl if (runStateOf(c) != rs) continue retry; // else CAS failed due to workerCount change; retry inner loop } } boolean workerStarted = false; boolean workerAdded = false; Worker w = null; try { w = new Worker(firstTask); final Thread t = w.thread; if (t != null) { final ReentrantLock mainLock = this.mainLock; mainLock.lock(); try { // Recheck while holding lock. // Back out on ThreadFactory failure or if // shut down before lock acquired. int rs = runStateOf(ctl.get()); if (rs largestPoolSize) largestPoolSize = s; workerAdded = true; } } finally { mainLock.unlock(); } if (workerAdded) { // start() -> runWorker()->task.run() // 新增成功后 调用start(),如果start()失败了,比如ntive stack申请失败,也返回false t.start(); workerStarted = true; } } } finally { if (!workerStarted) addWorkerFailed(w); } return workerStarted; }工作线程的执行
工作者线程的执行原理上比较简单,既不断从任务队列中取出任务,执行任务,然后返回线程池并等待下一个任务。
// 典型的线程池工作者线程结构public void run() { Throwable thrown = null; try { while(!isInterrupted()) runTask(getTaskFromWorkQueue()); }catch(Throwable e) { throw = e; }finaly { threadExited(this,thrown); } }}下面是ThreadPoolExecutor实际的工作者线程的任务执行,其中会涉及到线程的回收,任务的取消等实现.
点击查看代码
final void runWorker(Worker w) { Thread wt = Thread.currentThread(); Runnable task = w.firstTask; w.firstTask = null; // state: -1 => 0 , unlock -> release -> tryRelease -> state=0 // 这个时候任务线程开始工作,可以被中断 w.unlock(); // allow interrupts boolean completedAbruptly = true; try { // getTask从队列中拿任务 while (task != null || (task = getTask()) != null) { // 工作的时候将state置为1,表示正在工作,这个操作一定会成功(正常来说lock是一个基于状态的方法,可能会阻塞调用线程),因为不会有其他地方调用w.lock // 注:(state: 0 => 1 lock -> acquire -> tryAcquire -> state=1) w.lock(); // 线程当且仅当池子stopping(shutdown,shutdownNow的时候)的时候才会interrupted,且一定要interrupted // 注:(worker线程是由线程池服务来维护的,只有线程池服务有权对worker线程进行中断操作) if ((runStateAtLeast(ctl.get(), STOP) || // 注:(Thread.interrupted会清除interrupted标记) // 这里表明worker线程只能在STOPING(STOP,TIDING,TERMINATED)时中断信号有效,其他形式的中断信号(例如在任务中中断)会被清除 (Thread.interrupted() &&runStateAtLeast(ctl.get(), STOP))) && !wt.isInterrupted()) wt.interrupt(); try { // hooc 函数 beforeExecute(wt, task); Throwable thrown = null; try { task.run(); } catch (RuntimeException x) { // 保存异常 thrown 到1326处理(给客户端提供的钩子函数,afterExecute,使客户端可以感知到任务失败并进行特定的处理),同时抛出异常到 // 1330 处理(线程池自身对任务异常的处理) thrown = x; throw x; } catch (Error x) { thrown = x; throw x; } catch (Throwable x) { thrown = x; throw new Error(x); } finally { // 将任务执行过程中的异常传入到hooc函数 afterExecute(task, thrown); } } finally { // beforeExecutehooc函数出错或者任务出错了的话,task=null,从而跳到1336,completedAbruptly=true,从而回收线程,即使线程并没有完成任何工作 task = null; w.completedTasks++; w.unlock(); } } completedAbruptly = false; } finally { // 处理task=null的场景或者任务抛处异常时的场景,释放线程,什么时候task会为null ,go getTask processWorkerExit(w, completedAbruptly); } }服务的关闭,任务的取消与线程的回收服务的关闭
通过调用shutdown或者shutdownNow给工作线程发送中断信号尝试取消任务,并回收线程,继而关闭服务
public void shutdown() { final ReentrantLock mainLock = this.mainLock; mainLock.lock(); try { checkShutdownAccess(); // 状态至为SHUTDOWN advanceRunState(SHUTDOWN); // 给每个idle工作线程(已启动且没任务的)线程发送中断信号 interruptIdleWorkers(); onShutdown(); // hook for ScheduledThreadPoolExecutor } finally { mainLock.unlock(); } tryTerminate(); }public List shutdownNow() { List tasks; final ReentrantLock mainLock = this.mainLock; mainLock.lock(); try { checkShutdownAccess(); // 状态置为 STOP advanceRunState(STOP); // 给每个工作线程发送中断信号 interruptWorkers(); tasks = drainQueue(); } finally { mainLock.unlock(); } tryTerminate(); return tasks; }线程的回收
线程回收流程图:
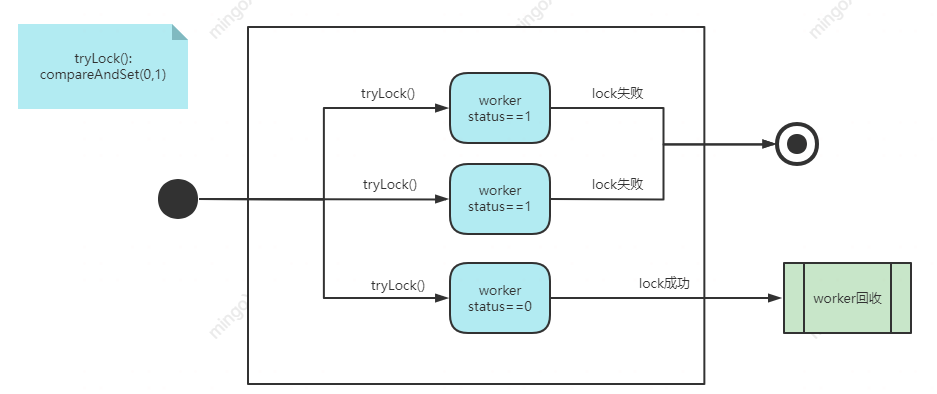
触发线程的回收主要有下面几种情况
- 由于setMaximumPoolSize,导致currentSize > maximumPoolSize时,getTask()返回null
- 线程池状态为stop时,即调用shutdownNow()时,getTask()返回null
- 线程池状态为shutdown,即调用shutdown(),线程池给idle线程发送中断信号,如果此时任务队列为空时,getTask()返回null
- 线程等待任务超时,getTask()返回null
- 任务执行失败,抛出运行时异常,导致task=null
当getTask()返回null或者task=null时,runWorker()跳到processWorkExit()处理线程回收,此时会新增线程来替换由于任务异常而被终止的线程
点击查看代码
private Runnable getTask() { boolean timedOut = false; // Did the last poll() time out? for (;;) { int c = ctl.get(); int rs = runStateOf(c); // Check if queue empty only if necessary. // stopped 或者 shutdown 且 workQueue.isEmpty 返回null 2,3 if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) { decrementWorkerCount(); return null; } int wc = workerCountOf(c); // Are workers subject to culling? // allowCoreThreadTimeOut等价于 wc> corePooSize // allowCoreThreadTimeOut, wc>corePoolSize, 一起表示 当任务线程获取任务超时时,被要求中断(subject to termination) boolean timed = allowCoreThreadTimeOut || wc > corePoolSize; // 1 wc > maxPoolSize 或者 4 获取任务超时且 要求获取任务超时的进程被中断(timed && timedOut) if ((wc > maximumPoolSize || (timed && timedOut)) && (wc > 1 || workQueue.isEmpty())) { if (compareAndDecrementWorkerCount(c)) return null; continue; } try { // 如果没有任务,则阻塞在这里, workQueue.offer后继续运行 Runnable r = timed ? workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) : workQueue.take(); if (r != null) return r; // r==null,poll返回null,表示timedOut,下次 go 1210 timedOut = true; } catch (InterruptedException retry) { // 忽略中断信号 timedOut = false; } } }线程池通过workers.remove()操作来释放worker的引用,从而由垃圾回收器回收线程,如果线程是由于任务执行异常而导致的终止,则会新增工作线程来替换它.
点击查看代码
private void processWorkerExit(Worker w, boolean completedAbruptly) { if (completedAbruptly) // If abrupt, then workerCount wasn't adjusted // getTask时会decrementWorkerCount decrementWorkerCount(); final ReentrantLock mainLock = this.mainLock; mainLock.lock(); try { // 回收线程前先将线程执行的任务数加一下 completedTaskCount += w.completedTasks; // 通过释放worker引用来释放线程 workers.remove(w); } finally { mainLock.unlock(); } tryTerminate(); int c = ctl.get(); if (runStateLessThan(c, STOP)) { if (!completedAbruptly) { int min = allowCoreThreadTimeOut ? 0 : corePoolSize; if (min == 0 && !workQueue.isEmpty()) min = 1; // 如果不是由于任务忽然中断且线程数符合最小值的要求,那么无需addWorker替换 if (workerCountOf(c) >= min) return; // replacement not needed } // 如果任务线程是由于任务执行异常退出的 或者 线程池中的数量小于min,addWorker addWorker(null, false); } }由上文我们了解到,无论是任务的取消,还是线程池服务的关闭,其中都是通过线程的中断来实现的,理解了线程中断我们就能够理解任务的取消以及服务关闭的具体含义。
线程的中断
中断机制是一种Java线程间的通信机制,每个Java线程都有一个boolean类型的中断状态。当调用Thread.interrupt(),并不意味着立即停止目标线程正在执行的任务,只是传递一个中断请求,将中断状态置为true。至于什么时候读这个状态,以及基于这个状态做什么操作,则完全由任务自身去控制。(早期的jdk库提供了Thread.stop(),Thread.suspend(),Thread.resume()来允许用户暴力终止,暂停,恢复一个线程,在jdk1.2后这些方法就被置为deprecated了,因为这样操作是不安全的,stop()会强制释放掉线程持有的锁,抛出ThreadDeathException,导致数据处于不一致的状态,从而造成未知的后果)例如:
public class Factorizer { private BigInteger lastNumber; private BigInteger[] lastFactors; public synchronized BigInteger[] cal(BigInteger number) { if(Objects.equal(number,lastNumber)) { return lastFactors; }else { //这两步是复合操作,需要原子性,我们不会在这两步之间判断Thread.currentThread().isInterrupted() lastFactors = factor(i); lastNmuber=i; return lastFactors; } }}jdk中有许多长时任务都是通过中断机制取消任务的。它们对中断的响应通常是:清除中断状态(Thread.interrupted()),然后抛出一个异常(InterruptedException),表示长时任务操作由于中断而提前结束。(wait,join,sleep,FutureTask.get(),CoundownLatch.await,lockInterrrupted(),BlockQueue.poll()等)
在编写任务的时候,基于这个状态做什么请求或者不做请求,例如重试或者忽略,都是可以的,只要满足自身任务的需要即可。但设计糟糕的任务可能会屏蔽中断请求,从而导致其他方法调用该任务的时候无法对中断进行响应,例如:
不安全的中断示例
public static void main(String[] args) { Thread calPrimeTask = new Thread(InterruptedTest::calPrime); calPrimeTask.start(); ThreadUtil.sleep(1000); // 尝试终止calPrimeTask calPrimeTask.interrupt(); } public static void calPrime() { while(!Thread.currentThread().isInterrupted()) { ThreadUtil.sleep(50); log(); System.out.println("一个耗时50ms的任务完成!"); } } public static void log() { /** * 假设有一段代码调用了jdk中的某个可能抛出InterruptedException的接口,这段代码捕获到这个异常后本意是不会处理这个异常,但是如果它没有再 * Thread.currentThread().interrupt(),就会影响其他使用到这个方法的函数,例如calPrime(); */ ArrayBlockingQueue que = new ArrayBlockingQueue(12); try { System.out.println("do other thing"); que.poll(30, TimeUnit.MILLISECONDS); }catch (InterruptedException e) { e.printStackTrace(); // poll抛出 InterruptedException后,会清空 interrupted标记,这里返回false System.out.println(Thread.currentThread().isInterrupted()); // 如果这里不重新设置interrupted标记的话,这回使得calPrimary任务无法取消,我们不知道调用栈的其他地方是否会用到中断信号,所以必须把中断信号设置回去 Thread.currentThread().interrupt(); } }// 不支持取消但仍可以调用可中断阻塞方法,忽略中断信号并重试public Task getNextTask(BlockingQueue queue) { boolean interrupted = false; try { while(true) { try { return queue.take(); }catch(InterruptedException e) { interrupted = true; // 忽略并重试 // 如果我们在这里调用Thread.currentThread().interrupt()的话会引起死循环 } }finally { if(interrupted) { // 避免屏蔽中断信号,其他方法可能需要 Thread.currentThread().interrupt(); } } }}线程池的使用
在实际生产生活中,由于任务性质的多种多样,我们往往会自定义符合各自应用场景的线程池来执行任务,不同的线程池参数设置意味着不同的任务执行策略(避免鸡蛋放在一个篮子里)。
// 不自定义线程池的危害:可能造成无法预知的死锁情况,次要的任务的执行影响重要的任务 public void deadLock() throws Exception{ CountDownLatch countDownLatch = new CountDownLatch(1); Callable task1 = () -> { ThreadUtil.sleep(2000); countDownLatch.countDown(); return "task1 finished"; }; // task2 依赖 task1 Callable task2 = () -> { countDownLatch.await(); ThreadUtil.sleep(1000); return "task2 finished"; }; ExecutorService executorService = Executors.newFixedThreadPool(1); // 假如 task2先于task1调度,就会发生死锁,因为只有一个线程,task1在任务队列里依赖task2的完成 Future result2 = executorService.submit(task2); Future result1 = executorService.submit(task1); System.out.println(result2.get() + result1.get()); };那么,线程池参数的选择就显得尤为重要。以下是一些ThreadPoolExecutor参数的介绍以及使用建议。
1 核心线程数与最大线程数
从上文的任务执行流程我们大致可以了解到,线程池主要通过这两个参数控制工作线程的数量。在设置这两个参数的时候需要注意以下两个问题。
1.1 工作线程的大小设置
大小设置主要影响系统的吞吐量。如果设置过小造成资源利用率低,人为地降低了系统的吞吐量,如果设置过大会造成线程竞争加剧,使得消耗更多的的计算资源在线程上下文切换上而不是执行任务上,最终也会导致系统的吞吐量降低。
设置线程池大小主要以下几种策略:
策略一
coreSize = 2×Ncpu,maxSize = 25×Ncpu
实际使用中我们往往会定义许多线程池,如果每个线程池的大小会导致核心线程越来越多,会使得竞争加剧,甚至达到操作系统限制的线程池数量
策略二
W/C: wait time/ compute time
Ucpu: 目标CPU利用率
Ncpu: Runtime.getRuntime().availableProcessors()
Nthreads = Ncpu * Ucpu * (1 + W/C)
I/O任务大部分时间都在等待I/O完成,这个值会比较大,上线前不好估计此值,而且线程池中的任务类型不一定都是一致的
策略三
QPS:每秒任务数 999线:单个任务的花销
1s内一个线程能够执行的任务数: 1/999线
1s内n个线程能执行的任务数:n * 1/999线
即 QPS=n/999线 ==> n = QPS*999线
核心线程:corePoolSize = QPS * 999线(单位:s)
timeout: 能容忍接口的最大响应时间
队列大小:queueCapacity = corePoolSize/999线 * timeout = QPS * timeout
最大线程:maxPoolSize = (QPS峰值- queueCapacity) * 999线
此策略考虑了实际生产环境的任务使用情况,也是假定线程池中的任务是同类型的。
如果线程池中的任务不是服务间调用而是单独的函数或者sql调用,那么QPS和999线就不好估计了。
策略四
使用动态线程池,可以动态调整线程池参数,以应对不同的使用场景变化,且可以通过cat监控线程池的使用情况。
实际生产业务使用中建议使用动态线程池,动态调整任务执行策略,同时为避免线程资源浪费,搭配下文提到的allowCoreThreadTimeOut一起使用。
public static ThreadPoolExecutor getExecutor(String name,boolean allowCoreThreadTimeOut) { ThreadPoolExecutor result = null; try { result = DynamicThreadPoolManager.getInstance().getThreadPoolExecutor(name); }catch (PoseidonException e) { log.error("ExecutorCase.getExecutor Error:",e); } if(Objects.isNull(result)) { return ExecutorUtil.getExecutor(name,Runtime.getRuntime().availableProcessors()); } // 任务完成后不需要留有核心线程可关闭 result.allowCoreThreadTimeOut(allowCoreThreadTimeOut); return result; }1.2 工作线程的回收
线程本质上是两个方法调用栈,是一个共享资源。当一个线程池处理QPS较低的任务时(eg:boss后台的接口,或者执行周期长的定时任务),我们往往会想当无任务执行的时候线程池可以自动回收线程资源,于是将coreSize设置成0。
假如我们将coreSize=0,但却使用的是有界队列,比如new ArrayBlockingQueue()。按照上文的执行流程,那么只有当任务塞满任务队列的时候,线程池才会正式开始执行任务。
为了解决这个问题,jdk1.6版本后的ThreadPoolExecutor提供了allowCoreThreadTimeOut字段。将这个字段置为ture后,我们不用设置coreSize=0,就可以让线程在无任务的时候等待keepAliveTime时间,将coreThread回收。具体实现可以查看:getTask,processWorkerExit方法。
2 任务队列
ThreadPoolExecutor使用的是BlockingQueue作为任务队列,即任何阻塞队列都可以用于任务的存储和转发。下面介绍3种常见任务队列的选择策略
策略一
无界队列(Unbounded queues)
例如LinkedBlockingQueue。使用无界队列主要适用于任务执行时间很短且确定的任务,例如找出某个自然数的因数。这种任务一定能够快速执行完成。但是实际业务场景中的任务执行时间通常是不确定的,需要远程调用接口,有许多I/O操作,这样就找出了任务消费很慢,如果此时有任务提交过来会找出OOM,从而影响整个服务的稳定。所以不建议使用。
策略二
有界队列(Bounded queues)
例如ArrayBlockingQueue。用于限制资源的使用量,避免出现OOM。
调整任务队列长度时往往也要调整最大线程数(maxmiumSize)。
| case | 问题 |
|---|---|
| 很大的queue.size,很小的maxmiumSize | 一方面降低CPU了使用率和线程切换频率,避免过度竞争,从而导致人为的降低了吞吐量(可以是优点也可以是缺点) |
| 很小的queue.size,很大的maxmiumSize | 会导致CPU使用率增高,这也会导致吞吐量降低 |
实际使用的时候大部分任务都是i/o密集型的,所以其实可以并发执行比我们想的更多的任务,适用于不紧急但希望尽可能快的任务,例如定时job任务或者导出任务。这种任务的执行我们希望在不影响其他服务的情况下尽可能快的执行。
策略三
直接处理任务(Direct handoffs)
例如:synchoronousQueue。当客户端提交任务时,在有合适的线程执行此任务才返回,否则阻塞客户端。
使用这个队列少了入队和出队操作,效率更好,适用于需要尽快响应的任务,例如h5端的接口。
这种方式通常需要 unbounded maxmiumPoolSize, 即无限制的线程数,但是如果当客户端不停地提交任务且消费不过来地时候,会有线程数疯狂飙升,造成系统不稳定的风险。所以实际使用中还是会限制 maxmiumSize的值,可以通过使用下文中提到的CallerRunRejectPolicy来缓慢降低客户端提交任务的速度。从而将异步降级为同步执行。
3 任务拒绝策略
在线程池关闭(shutdown()),或者任务队列满了,工作线程也满了的时候会执行RejectedExecutionHandler.rejectedExecution(),来拒绝任务,jdk为我们提供了以下四种拒绝策略,我们也可以自己定义合适的拒绝策略.
| 拒绝策略 | 描述 |
|---|---|
| ThreadPoolExecutor.AbortPolify | 默认拒绝策略,抛出RejectedExecutionException异常来通知客户端有任务被拒绝,客户端经常会忽略这个异常的处理导致发生线上问题 |
| ThreadPoolExecutor.DiscardPolify | 丢弃最新提交的任务。一般没有哪个任务是可以丢弃的,不建议使用。 |
| ThreadPoolExecutor.DiscardOldestPolify | 丢弃最先提交的任务。这里注意如果使用的是优先级队列的话,会抛弃最高优先级的任务,随意得谨慎使用 |
| ThreadPoolExecutor.CallerRunPolify | 由客户端线程执行任务,即 客户端代码 -> submit() -> task.run() ->客户端代码,可以降低任务的提交速度,使得由异步执行降级为同步执行 |
4 工作线程工厂类
线程池使用线程工厂类来生成工作线程,我们可以自定义或者使用guava提供的ThreadFactoryBuilder()来创建线程工厂类
public class DefaultThreadFactory implements ThreadFactory { private static final AtomicInteger poolNumber = new AtomicInteger(1); private final ThreadGroup group; private final AtomicInteger threadNumber = new AtomicInteger(1); private final String namePrefix; DefaultThreadFactory(String threadPoolName) { SecurityManager s = System.getSecurityManager(); group = (s != null) ? s.getThreadGroup() : Thread.currentThread().getThreadGroup(); namePrefix = threadPoolName + "-" + poolNumber.getAndIncrement() + "-thread-"; } public Thread newThread(Runnable r) { Thread t = new Thread(group, r, namePrefix + threadNumber.getAndIncrement(), 0); if (t.isDaemon()) { t.setDaemon(false); } if (t.getPriority() != Thread.NORM_PRIORITY) { t.setPriority(Thread.NORM_PRIORITY); } return t; }}// guavaThreadFactory namedThreadFactory = new ThreadFactoryBuilder() .setNameFormat(name + "-pool-%d").build();JDK平台提供的默认线程池
Executors作为Executor接口的伴生类,提供了一些默认的线程池供我们使用.当实际很少使用他们,因为Executors创建的线程池,要么是无界线程池(CachedThreadPoolExecutor), 要么是无界任务队列(FixedThreadPoolExecutor),两者都有资源耗尽的风险,会影响到整个服务器.SingletonThreadPoolExecutor又不适合需要多个任务并发执行的场景,所以最好是自定义适合各自业务场景的线程池.
Executors.newSingleThreadExecutor:new ThreadPoolExecutor(1, 1,0L,TimeUnit.MILLISECONDS,new LinkedBlockingQueue());仅有一个工作线程的线程池,使用无界队列,主要用于任务按顺序执行;Executors.newCachedThreadPool:new ThreadPoolExecutor(0, Integer.MAX_VALUE,60L, TimeUnit.SECONDS,new SynchronousQueue());无界线程池,任务无入队和出队操作,效率更好,适用于任务执行时间短且确定的场景,但当消费不过来时,有资源耗尽的风险;Executors.newFixedThreadPool():new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue());有界线程池,但是使用的是无界队列,避免由于线程过多而造成的资源耗尽风险,但当消费不过来时,由于使用的无界队列,也会有OOM的风险;Executors.ScheduledThreadPoolExecutor(): public ScheduledThreadPoolExecutor(int corePoolSize) { super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS, new DelayedWorkQueue()); };使用延迟队列实现,用于执行定时任务;实际业务中的使用
ThreadPoolExecutor仅是Executor接口的实现,在实际业务中我们可能会有批量任务执行的需求,虽然AbstractExecutorSerivice提供了invokeAll方法用于批量执行任务,当我们往往会使用ExecutorCompletionService来实现这个目的,因为后者相比前者,客户端可以更快地拿到批量任务的执行结果(无论是异常还是正常执行),而前者只是按照任务的提交顺序返回任务执行结果.(考虑假如第一个任务就执行时间很长,第二个任务执行时间很短,使用ExecutorCompletionService可以先拿到第二个任务地执行结果)
// 实际使用中通过poseidon平台提供的动态线程池来维护线程池参数.public static ThreadPoolExecutor getExecutor(String name,boolean allowCoreThreadTimeOut) { ThreadPoolExecutor result = null; try { result = DynamicThreadPoolManager.getInstance().getThreadPoolExecutor(name); }catch (PoseidonException e) { log.error("ExecutorCase.getExecutor Error:",e); } if(Objects.isNull(result)) { return ExecutorUtil.getExecutor(name,Runtime.getRuntime().availableProcessors()); } // 任务完成后不需要留有核心线程可关闭 result.allowCoreThreadTimeOut(allowCoreThreadTimeOut); return result; }// 基于ExecutorCompletionService实现的invokeAll public static boolean invokeAll(CompletionService executorService, List<Callable> taskList) { if (Objects.isNull(executorService) || CollectionUtil.isNullOrEmpty(taskList)) { return true; } List results = batchExecutor(executorService, taskList, false); return results.stream().allMatch(e -> Objects.equals(e, Boolean.TRUE)); } public static List batchExecutor(CompletionService completionService, List<Callable> taskList, boolean allowError) { List resultList = Lists.newArrayList(); taskList.forEach(completionService::submit); for (int i = 0; i < taskList.size(); i++) { Future resultFuture = null; try { resultFuture = completionService.take(); T result = resultFuture.get(); resultList.add(result); } catch (InterruptedException e) { Thread.currentThread().interrupt(); } catch (ExecutionException e) { // 原始异常 Throwable cause = e.getCause(); log.error("batchExecutor执行异常: ", cause); if (!allowError) { // 重新抛出可处理的异常 throw new BizException(BizErrorCodeEnum.OPERATION_FAILED, cause.getMessage()); } } finally { if (Objects.nonNull(resultFuture)) { resultFuture.cancel(true); } } } return resultList; }// boss后台接口,数据导出,同步,定时等任务,此类任务一般执行频率较低,所以可以在任务的时候回收核心线程,同时为避免客户端忘记处理RejectedExecutionException异常,使用CallerRunsPolicy拒绝策略,当任务队列满了的时候,通过使用调用者线程执行,来减慢任务提交的速度,这样并发执行就自然降级为同步执行ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(corePoolSize, 8, 20, // 默认callerRunsPolicy,队列满后,降为串行执行 TimeUnit.MILLISECONDS, new ArrayBlockingQueue(200), namedThreadFactory, new ThreadPoolExecutor.CallerRunsPolicy()); // 任务完成后不需要留有核心线程可关闭threadPoolExecutor.allowCoreThreadTimeOut(true);// h5端接口,此类任务一般执行频率较高,可以不用回收核心线程,同时希望任务尽可能快的处理,所以任务队列可以选择使用SynchronizeQueue(),避免任务的入队和出队消耗,最大线程数可以设置地相对大点,这样有利于更多任务并发执行,拒绝策略同样选择使用CallerRunsPolicyThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(corePoolSize, 15, 20, // 默认callerRunsPolicy,队列满后,降为串行执行 TimeUnit.MILLISECONDS, new SynchronousQueue(), namedThreadFactory, new ThreadPoolExecutor.CallerRunsPolicy());// 使用信号量限制任务提交速度public class BoundedExecutor { private final Executor exec; private final Semaphore semaphore; public BoundedExecutor(Executor exec, int bound) { this.exec = exec; this.semaphore = new Semaphore(bound); } public void submitTask(final Runnable command) throw InterruptedException{ semaphore.acquire(); try { exec.execute(new Runnable() { public void run() { try { command.run(); }finally { semaphore.release(); } } }); }catch(RejectedExecutionException e) { semaphore.release(); } }}总结
本篇文章介绍了Executor框架的大体实现思路和在实际业务中的主要使用场景,项目中引入了线程池使用的好的话可以提高服务的响应速率,增大资源的利用率,但同时也引入了不稳定的因素,例如使用不当造成OOM或者抛出RejectedExecuteException等,所以对于线程池的监控就显地尤为重要,本篇文章并没有涉及线程地监控方面地知识。
参考资料
- [1]《Java并发编程实践》
- [2] JDK 1.8源码
- [3]Java线程池实现原理及其在美团业务中的实践
- [4] Thread.interrupt()相关源码分析