摘要:本文介绍将TensorFlow网络模型迁移到昇腾AI平台,并执行训练的全流程。然后以TensorFlow 1.15训练脚本为例,详细介绍了自动迁移、手工迁移以及模型训练的操作步骤。
本文分享自华为云社区《将TensorFlow模型快速迁移到昇腾平台》,作者:昇腾CANN。
当前业界很多训练脚本是基于TensorFlow的Python API进行开发的,默认运行在CPU/GPU/TPU上,为了使这些脚本能够利用昇腾AI处理器的强大算力执行训练,需要对TensorFlow的训练脚本进行迁移。
首先,我们了解下模型迁移的全流程:
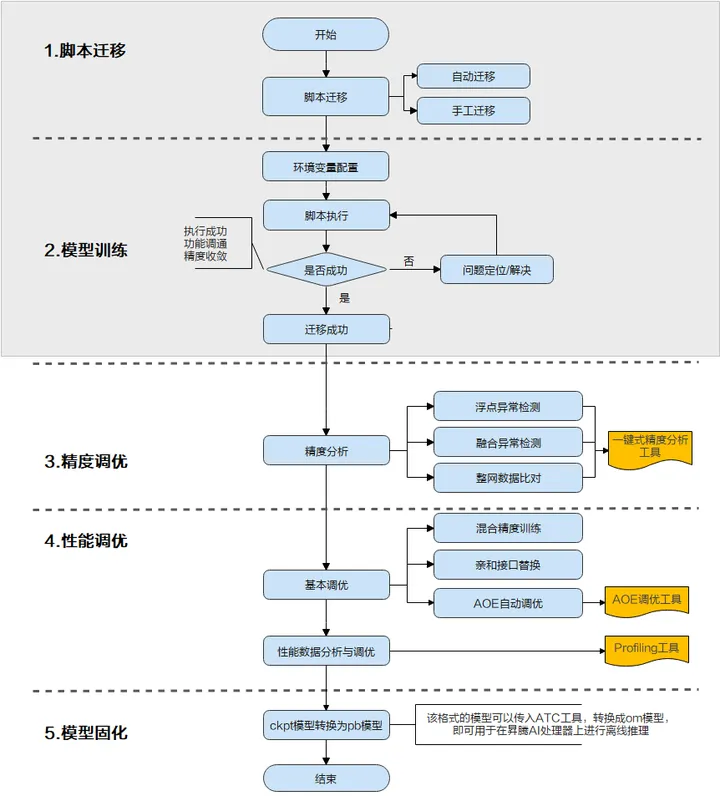
通过上图可以看出,模型迁移包括“脚本迁移 –> 模型训练 –> 精度调优 –> 性能调优 –> 模型固化”几个流程,其中:
- “脚本迁移”是将TensorFlow训练脚本经过少量修改,可以运行在昇腾AI处理器上。
- “模型训练”是根据模型参数进行多轮次的训练迭代,并在训练过程中评估模型准确度,达到一定阈值后停止训练,并保存训练好的模型。
- “精度调优”与“性能调优”是在用户对精度或性能有要求时需要执行的操作。
- “模型固化”是将训练好的、精度性能达标的模型固化为pb模型。
下面我们针对“脚本迁移”和“模型训练”两个阶段进行详细的介绍。
脚本迁移
将TensorFlow训练脚本迁移到昇腾平台有自动迁移和手工迁移两种方式。
- 自动迁移:算法工程师通过迁移工具,可自动分析出原生的TensorFlow Python API在昇腾AI处理器上的支持度情况,同时将原生的TensorFlow训练脚本自动迁移成昇腾AI处理器支持的脚本,对于少量无法自动迁移的API,可以参考工具输出的迁移报告,对训练脚本进行相应的适配修改。
- 手工迁移:算法工程师需要参考文档人工分析TensorFlow训练脚本的API支持度,并进行相应API的修改,以支持在昇腾AI处理器上执行训练,该种方式相对复杂,建议优先使用自动迁移方式。
下面以TensorFlow 1.15的训练脚本为例,讲述训练脚本的详细迁移操作,TensorFlow 2.6的迁移操作类似,详细的迁移点可参见“昇腾文档中心[1]”。
自动迁移
自动迁移的流程示意图如下所示:
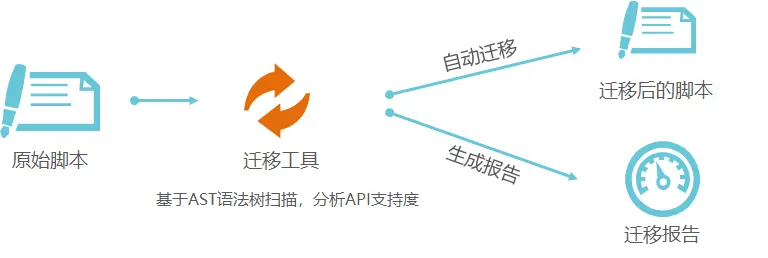
详细步骤如下;
1. 安装迁移工具依赖。
pip3 install pandaspip3 install xlrd==1.2.0pip3 install openpyxlpip3 install tkintertablepip3 install google_pasta
2. 执行自动迁移命令。
进入迁移工具所在目录,例如“tfplugin安装目录/tfplugin/latest/python/site-packages/npu_bridge/convert_tf2npu/”,执行类似如下命令可同时完成脚本扫描和自动迁移:
python3 main.py -i /root/models/official/resnet -r /root/models/official/
其中main.py是迁移工具入口脚本,-i指定待迁移原始脚本路径,-r指定迁移报告存储路径。
3. 查看迁移报告。
在/root/models/official/output_npu_*下查看迁移后的脚本,在root/models/official/report_npu_*下查看迁移报告。
迁移报告示例如下:
 手工迁移
手工迁移
手工迁移训练脚本主要包括如下迁移点:
1. 导入NPU库文件。
from npu_bridge.npu_init import *2. 将部分TensorFlow接口迁移成NPU接口。
例如,修改基于Horovod开发的分布式训练脚本,使能昇腾AI处理器的分布式训练。
# Add Horovod Distributed Optimizeropt = hvd.DistributedOptimizer(opt)# Add hook to broadcast variables from rank 0 to all other processes during# initialization.hooks = [hvd.BroadcastGlobalVariablesHook(0)]
修改后:
# NPU allreduce# 将hvd.DistributedOptimizer修改为npu_distributed_optimizer_wrapper"opt = npu_distributed_optimizer_wrapper(opt) # Add hook to broadcast variables from rank 0 to all other processes during initialization.hooks = [NPUBroadcastGlobalVariablesHook(0)]
3. 通过配置关闭TensorFlow与NPU冲突的功能。
关闭TensorFlow中的remapping、xla等功能,避免与NPU中相关功能冲突。例如:
config = tf.ConfigProto(allow_soft_placement=True)# 显式关闭remapping功能config.graph_options.rewrite_options.remapping = RewriterConfig.OFF# 显示关闭memory_optimization功能config.graph_options.rewrite_options.memory_optimization = RewriterConfig.OFF
4. 配置NPU相关参数
Ascend平台提供了功能调试、性能/精度调优等功能,用户可通过配置使能相关功能,例如enable_dump_debug配置,支持以下取值:
- True:开启溢出检测功能。
- False:关闭溢出检测功能。
配置示例:
custom_op.parameter_map["enable_dump_debug"].b = True
模型训练
迁移成功后的脚本可在昇腾AI处理器上执行单Device训练,也可以在多个Device上执行分布式训练。
单Device训练
1)配置训练进程启动依赖的环境变量。
# 配置昇腾软件栈的基础环境变量,包括CANN、TF Adapter依赖的内容。source /home/HwHiAiUser/Ascend/nnae/set_env.sh source /home/HwHiAiUser/Ascend/tfplugin/set_env.sh# 添加当前脚本所在路径到PYTHONPATH,例如:export PYTHONPATH="$PYTHONPATH:/root/models"# 训练任务ID,用户自定义,不建议使用以0开始的纯数字export JOB_ID=10066 # 指定昇腾AI处理器逻辑ID,单P训练也可不配置,默认为0,在0卡执行训练 export ASCEND_DEVICE_ID=0
2)执行训练脚本拉起训练进程。
python3 /home/xxx.py
分布式训练
分布式训练需要先配置参与训练的昇腾AI处理器的资源信息,然后再拉起训练进程。当前有两种配置资源信息的方式:通过配置文件(即ranktable文件)或者通过环境变量的方式。下面以配置文件的方式介绍分布式训练的操作。
1)准备配置文件。
配置文件(即ranktable文件)为json格式,示例如下:
{"server_count":"1", //AI server数目"server_list":[ { "device":[ // server中的device列表 { "device_id":"0", "device_ip":"192.168.1.8", // 处理器真实网卡IP "rank_id":"0" // rank的标识,rankID从0开始 }, { "device_id":"1", "device_ip":"192.168.1.9", "rank_id":"1" } ], "server_id":"10.0.0.10" //server标识,以点分十进制表示IP字符串 }],"status":"completed", // ranktable可用标识,completed为可用"version":"1.0" // ranktable模板版本信息,当前必须为"1.0"}
2)执行分布式训练。
依次设置环境变量配置集群参数,并拉起训练进程。
拉起训练进程0:
# 配置昇腾软件栈的基础环境变量,包括CANN、TF Adapter依赖的内容。source /home/HwHiAiUser/Ascend/nnae/set_env.sh source /home/HwHiAiUser/Ascend/tfplugin/set_env.shexport PYTHONPATH=/home/test:$PYTHONPATHexport JOB_ID=10086export ASCEND_DEVICE_ID=0# 当前Device在集群中的唯一索引,与资源配置文件中的索引一致export RANK_ID=0# 参与分布式训练的Device数量export RANK_SIZE=2export RANK_TABLE_FILE=/home/test/rank_table_2p.jsonpython3 /home/xxx.py
拉起训练进程1:
# 配置昇腾软件栈的基础环境变量,包括CANN、TF Adapter依赖的内容。source /home/HwHiAiUser/Ascend/nnae/set_env.sh source /home/HwHiAiUser/Ascend/tfplugin/set_env.shexport PYTHONPATH=/home/test:$PYTHONPATHexport JOB_ID=10086export ASCEND_DEVICE_ID=1# 当前Device在集群中的唯一索引,与资源配置文件中的索引一致export RANK_ID=1# 参与分布式训练的Device数量export RANK_SIZE=2export RANK_TABLE_FILE=/home/test/rank_table_2p.jsonpython3 /home/xxx.py
以上就是TensorFlow模型迁移训练的相关知识点,您也可以在“昇腾社区在线课程[2]”板块学习视频课程,学习过程中的任何疑问,都可以在“昇腾论坛[3]”互动交流!
相关参考:
[1]昇腾文档中心:https://www.hiascend.com/zh/document
[2]昇腾社区在线课程:https://www.hiascend.com/zh/edu/courses
[3]昇腾论坛:https://www.hiascend.com/forum
点击关注,第一时间了解华为云新鲜技术~