data analysis什么是数据分析
- 是把隐藏在一些看似杂乱无章的数据背后的信息提炼出来,总结出所研究对象的内在规律
- 使得数据的价值最大化
- 分析用户的消费行为
- 制定促销活动的方案
- 制定促销时间和粒度
- 计算用户的活跃度
- 分析产品的回购力度
- 分析广告点击率
- 决定投放时间
- 制定广告定向人群方案
- 决定相关平台的投放
- ……
- 分析用户的消费行为
- 使得数据的价值最大化
- 数据分析是用适当的方法对收集来的大量数据进行分析,帮助人们做出判断,以便采取适当的行动
- 保险公司从大量赔付申请数据中判断哪些为骗保的可能
- 支付宝通过从大量的用户消费记录和行为自动调整花呗的额度
- 短视频平台通过用户的点击和观看行为数据针对性的给用户推送喜欢的视频
数据分析实现流程
- 提出问题
- 准备数据
- 分析数据
- 获得结论
- 成果可视化
开发环境介绍
- anaconda
- 官网:https://www.anaconda.com/
- 集成环境:集成好了数据分析和机器学习中所需要的全部环境
- 注意:
- 安装目录不可以有中文和特殊符号
- 注意:
- jupyter
- jupyter就是anaconda提供的一个基于浏览器的可视化开发工具
- jupyter的基本使用
- 启动:在终端中录入:jupyter notebook的指令,按下回车
- 新建:
- python3:anaconda中的一个源文件
- cell有两种模式:
- code:编写代码
- markdown:编写笔记
- 快捷键:
- 添加cell:a或者b
- 删除:x
- 修改cell的模式:
- m:修改成markdown模式
- y:修改成code模式
- 执行cell:
- shift+enter
- tab:自动补全
- 代开帮助文档:shift+tab
数据分析三剑客
- numpy
- pandas(重点)
- matplotlib
numpy
- NumPy(Numerical Python) 是 Python 语言中做科学计算的基础库。重在于数值计算,也是大部分Python科学计算库的基础,多用于在大型、多维数组上执行的数值运算。
numpy的创建
- 使用np.array()创建
- 使用plt创建
- 使用np的routines函数创建
使用numpy创建一位数组
>>> import numpy as np>>> arr = np.array([1,2,3])>>> arrarray([1, 2, 3])使用numpy创建二维数组
>>> arr = np.array([[1,2,3],[4,5,6]])>>> arrarray([[1, 2, 3], [4, 5, 6]])
数组和列表的区别是什么?
>>> arr = np.array([1,1.27,'regina'])>>> arrarray(['1', '1.27', 'regina'], dtype='<U32')
- 数组中存储的数据元素类型必须是统一类型
- 优先级:
- 字符串 > 浮点型 > 整数
将外部的一张图片读取加载到numpy数组中,然后尝试改变数组元素的数值查看对原始图片的影响
import matplotlib.pyplot as pltimg_arr = plt.imread('/Users/ivanlee/Desktop/女明星/IMG_1473.JPG')plt.imshow(img_arr) #将numpy数组进行可视化展示

如果每一个像素块的值减100

运用函数创建数组
- zero()
- ones()
- linspace()
- arange()
- random系列
ones
np.ones(shape(3,4))array([[1., 1., 1., 1.], [1., 1., 1., 1.], [1., 1., 1., 1.]])Linspace(): 一维的等差数列的数组
>>> np.linspace(0,100,num=20)array([ 0. , 5.26315789, 10.52631579, 15.78947368, 21.05263158, 26.31578947, 31.57894737, 36.84210526, 42.10526316, 47.36842105, 52.63157895, 57.89473684, 63.15789474, 68.42105263, 73.68421053, 78.94736842, 84.21052632, 89.47368421, 94.73684211, 100. ])arange():一维的等差数列
>>> np.arange(0,50,step=3)array([ 0, 3, 6, 9, 12, 15, 18, 21, 24, 27, 30, 33, 36, 39, 42, 45, 48])Random():返回由size决定的形状数组
>>> np.random.randint(0,100,size=(3,5))array([[88, 56, 60, 56, 9], [ 9, 0, 32, 31, 32], [78, 10, 21, 78, 98]])
numpy的常用属性
- shape 形状
- ndim 维度
- size 总共个数
- dtype 元素类型

numpy的数据类型
- array(dtype=?):可以设定数据类型
- arr.dtype = ‘?’:可以修改数据类型
| 名称 | 描述 |
|---|---|
| bool_ | 布尔型数据类型(True 或者 False) |
| int_ | 默认的整数类型(类似于 C 语言中的 long,int32 或 int64) |
| intc | 与 C 的 int 类型一样,一般是 int32 或 int 64 |
| intp | 用于索引的整数类型(类似于 C 的 ssize_t,一般情况下仍然是 int32 或 int64) |
| int8 | 字节(-128 to 127) |
| int16 | 整数(-32768 to 32767) |
| int32 | 整数(-2147483648 to 2147483647) |
| int64 | 整数(-9223372036854775808 to 9223372036854775807) |
| uint8 | 无符号整数(0 to 255) |
| uint16 | 无符号整数(0 to 65535) |
| uint32 | 无符号整数(0 to 4294967295) |
| uint64 | 无符号整数(0 to 18446744073709551615) |
| float_ | float64 类型的简写 |
| float16 | 半精度浮点数,包括:1 个符号位,5 个指数位,10 个尾数位 |
| float32 | 单精度浮点数,包括:1 个符号位,8 个指数位,23 个尾数位 |
| float64 | 双精度浮点数,包括:1 个符号位,11 个指数位,52 个尾数位 |
| complex_ | complex128 类型的简写,即 128 位复数 |
| complex64 | 复数,表示双 32 位浮点数(实数部分和虚数部分) |
| complex128 | 复数,表示双 64 位浮点数(实数部分和虚数部分) |
numpy 的数值类型实际上是 dtype 对象的实例,并对应唯一的字符,包括 np.bool_,np.int32,np.float32,等等。

numpy的索引和切片操作(重点)
索引操作和列表同理
>>> arr = np.random.randint(1,100,size=(5,6))>>> arrarray([[49, 26, 2, 75, 91, 93], [68, 49, 40, 40, 51, 54], [39, 49, 16, 93, 45, 2], [13, 43, 67, 52, 2, 46], [74, 20, 9, 73, 91, 21]])>>> arr[1]array([68, 49, 40, 40, 51, 54])>>> arr[[1,3,4]]array([[68, 49, 40, 40, 51, 54], [13, 43, 67, 52, 2, 46], [74, 20, 9, 73, 91, 21]])切片操作
切出前两行数据
>>> arr[0:2]array([[49, 26, 2, 75, 91, 93], [68, 49, 40, 40, 51, 54]])切出前两列数据
>>> arr[:,0:2]array([[49, 26], [68, 49], [39, 49], [13, 43], [74, 20]])切出前两行的前两列的数据
>>> arr[0:2,0:2]array([[49, 26], [68, 49]])数组行翻转
>>> arr[::-1]array([[74, 20, 9, 73, 91, 21], [13, 43, 67, 52, 2, 46], [39, 49, 16, 93, 45, 2], [68, 49, 40, 40, 51, 54], [49, 26, 2, 75, 91, 93]])数组列翻转
>>> arr[::,::-1]array([[93, 91, 75, 2, 26, 49], [54, 51, 40, 40, 49, 68], [ 2, 45, 93, 16, 49, 39], [46, 2, 52, 67, 43, 13], [21, 91, 73, 9, 20, 74]])练习:将一张图片上下左右进行翻转操作
import matplotlib.pyplot as pltimg_arr = plt.imread('/Users/ivanlee/Desktop/女明星/IMG_1473.JPG')plt.imshow(img_arr) #将numpy数组进行可视化展示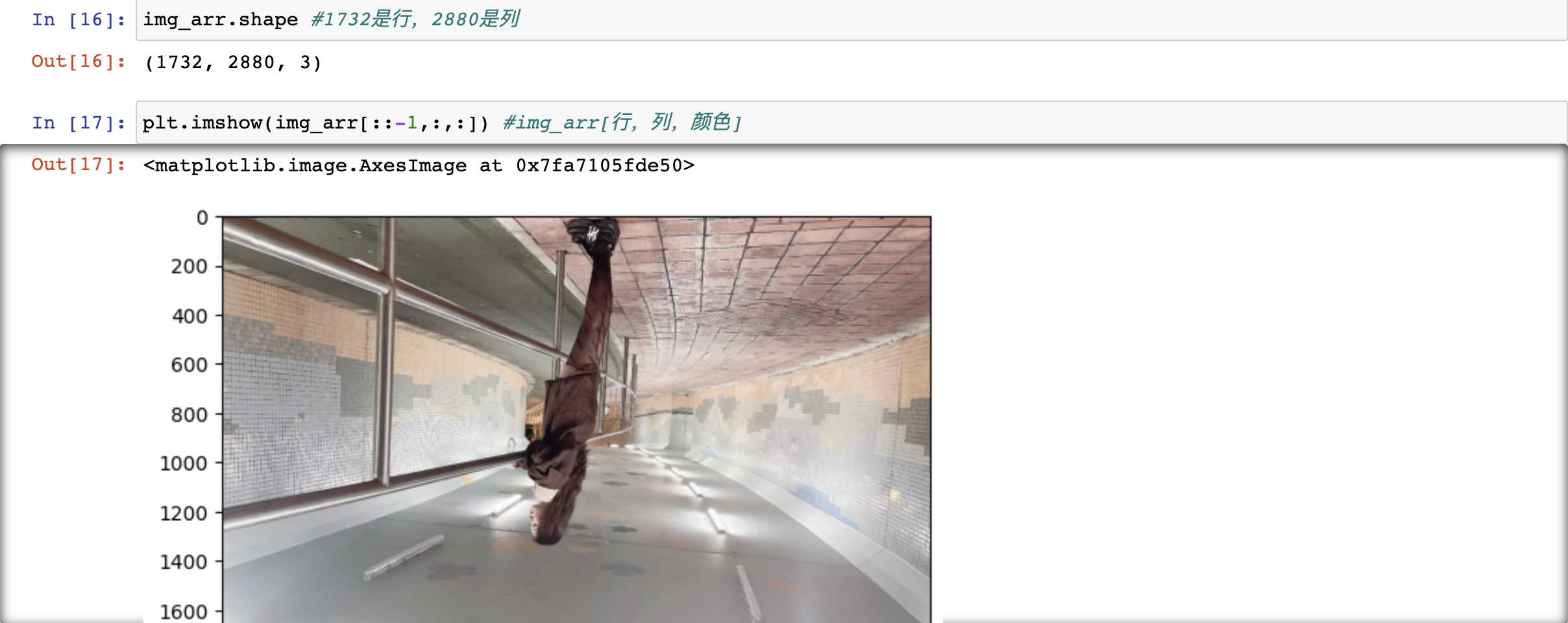

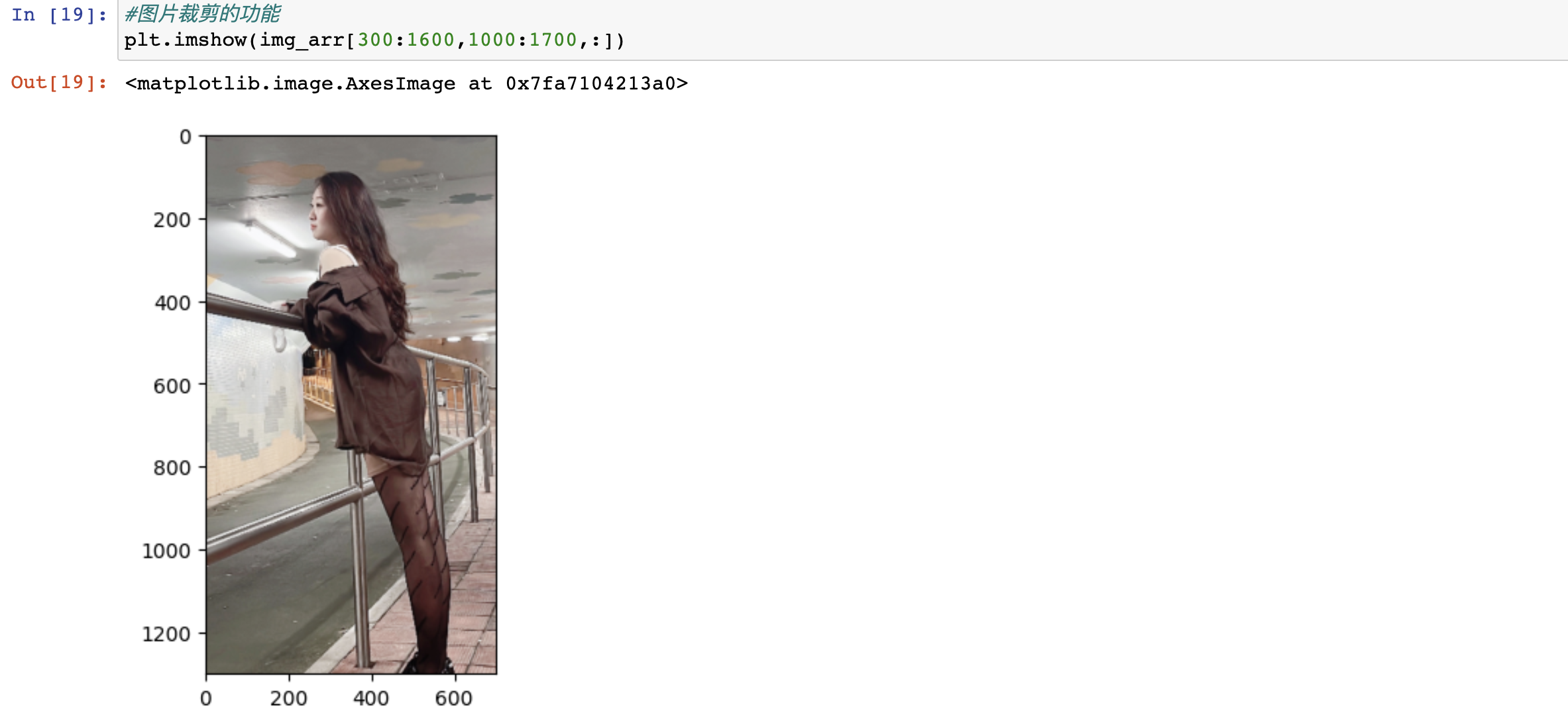
练习:将图片进行指定区域的裁剪
numpy变形
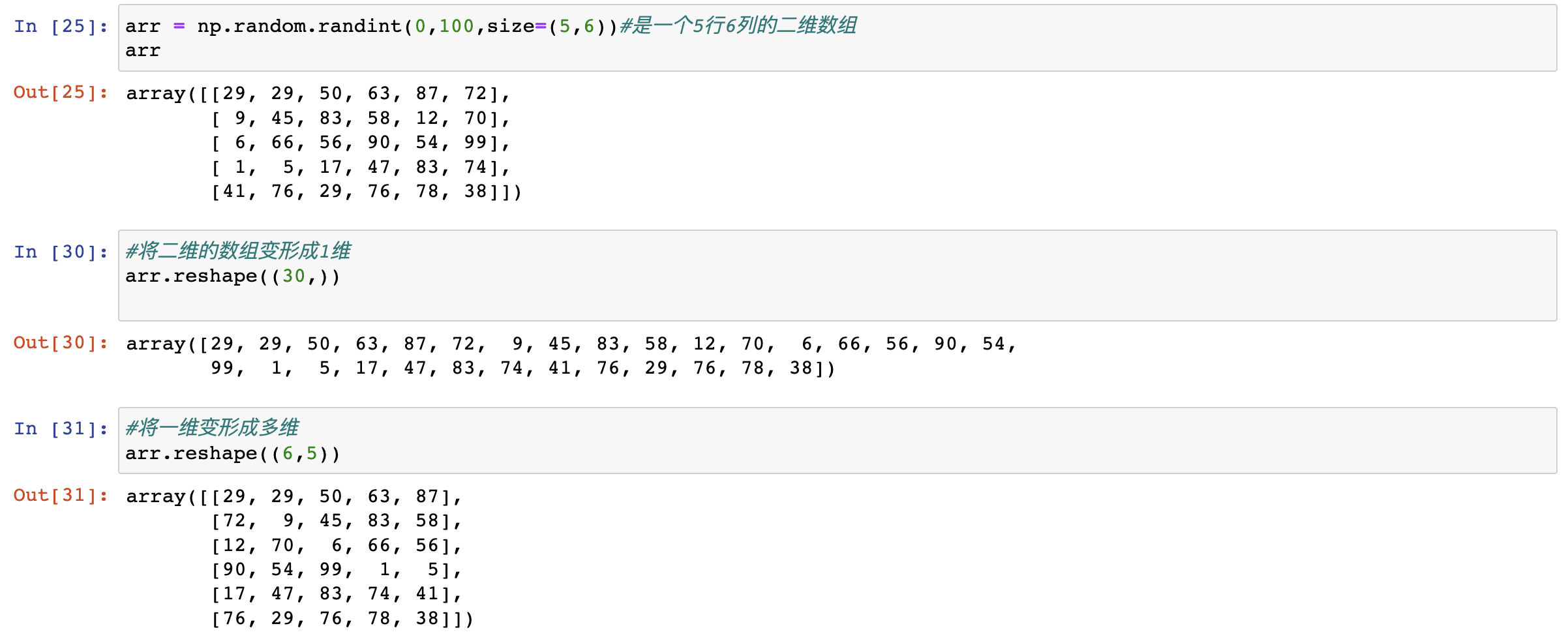
reshape操作
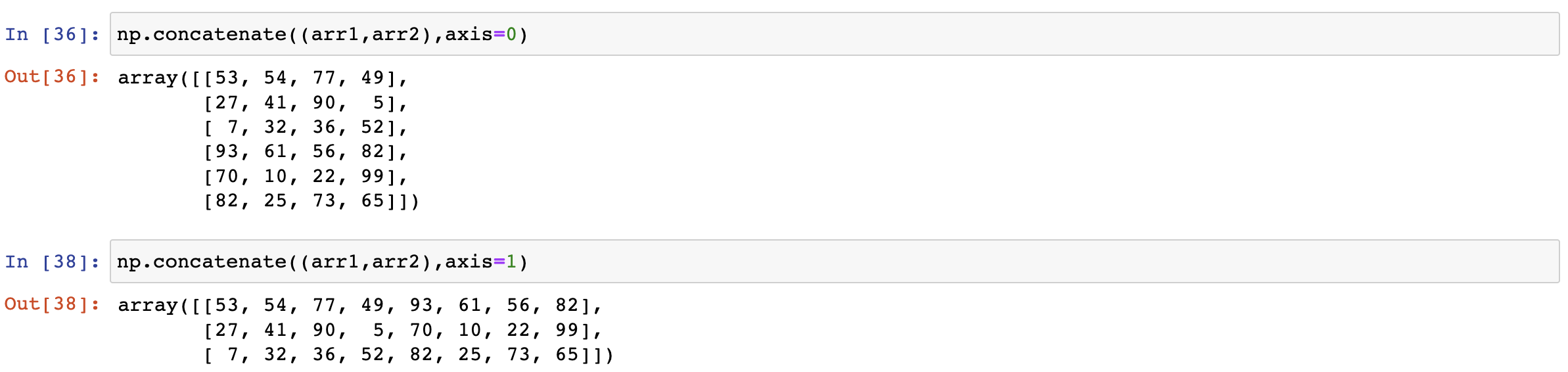
级联操作
- 将多个numpy数组进行横向或者纵向的拼接axis轴向的理解
- 0:列
- 1:行
问题:
级联的两个数组维度一样,但是行列个数不一样会如何?
答:不一样就无法拼接
对图进行拼接
arr_3 = np.concatenate((img_arr,img_arr,img_arr),axis=0)plt.imshow(arr_3)
arr_3 = np.concatenate((img_arr,img_arr,img_arr),axis=1)plt.imshow(arr_3)
常用的聚合操作
sum,max,min,mean

常用的数学函数
- NumPy 提供了标准的三角函数:sin()、cos()、tan()
- numpy.around(a,decimals) 函数返回指定数字的四舍五入值。
- 参数说明:
- a: 数组
- decimals: 舍入的小数位数。 默认值为0。 如果为负,整数将四舍五入到小数点左侧的位置
- 参数说明:
常用的统计函数
- numpy.amin() 和 numpy.amax(),用于计算数组中的元素沿指定轴的最小、最大值。
- numpy.ptp():计算数组中元素最大值与最小值的差(最大值 – 最小值)。
- numpy.median() 函数用于计算数组 a 中元素的中位数(中值)
- 标准差std():标准差是一组数据平均值分散程度的一种度量。
- 公式:
std = sqrt(mean((x - x.mean())**2)) - 如果数组是 [1,2,3,4],则其平均值为 2.5。 因此,差的平方是 [2.25,0.25,0.25,2.25],并且其平均值的平方根除以 4,即 sqrt(5/4) ,结果为 1.1180339887498949。
- 公式:
- 方差var():统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数,即 mean((x – x.mean())** 2)。换句话说,标准差是方差的平方根

矩阵相关
NumPy 中包含了一个矩阵库 numpy.matlib,该模块中的函数返回的是一个矩阵,而不是 ndarray 对象。一个 的矩阵是一个由行(row)列(column)元素排列成的矩形阵列。
numpy.matlib.identity() 函数返回给定大小的单位矩阵。单位矩阵是个方阵,从左上角到右下角的对角线(称为主对角线)上的元素均为 1,除此以外全都为 0。
eye返回一个标准的单位矩阵
np.eye(6)

T 转置

矩阵相乘
- numpy.dot(a, b, out=None)
- a : ndarray 数组
- b : ndarray 数组

本文来自博客园,作者:ivanlee717,转载请注明原文链接:https://www.cnblogs.com/ivanlee717/p/16985422.html