springboot继承efk实现日志收集1.安装es和kibana
我使用的云服务器centos7,2核+4G内存,跑起来内存使用率50%左右
建议使用最低配置和我一样,1+2的配置kibana应该跑不起来,安装过程使用了尚硅谷的springcloud的课程资料,也!!!!!!!!可以不用,自己pull,我附了pull的方法
资料包:链接:https://pan.baidu.com/s/1GW1qUUwya6mUAacFokpZUw?pwd=eses
提取码:eses
参考资料:https://blog.csdn.net/liurui_wuhan/article/details/115480511
1.1安装es
使用的版本都是7.12.1
使用的安装方式是docker
1.创建互联网络
创建kibana和es可以在docker中互联的网络
docker network create es-net2.加载镜像
将资料包中的es.tar上传到服务器
# 导入数据2docker load -i es.tarps:也可以自己pull ,只要最后的docker里有镜像就好了
#pull的方法docker pull docker.elastic.co/elasticsearch/elasticsearch:7.12.1docker pull kibana:7.12.13.运行
docker run -d \--name es \ -e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \ -e "http.host=0.0.0.0"\ -e "discovery.type=single-node" \ -v es-data:/usr/share/elasticsearch/data \ -v es-plugins:/usr/share/elasticsearch/plugins \ --privileged \ --network es-net \ -p 9200:9200 \ -p 9300:9300 \elasticsearch:7.12.1命令解释:
--name es:给启动的容器别名,查看的时候可以直接使用es代替所有需要填写容器名称的地方,比如docker logs -f es-e "cluster.name=es-docker-cluster":设置集群名称-e "http.host=0.0.0.0":监听的地址,可以外网访问-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":内存大小-e "discovery.type=single-node":非集群模式-v es-data:/usr/share/elasticsearch/data:挂载逻辑卷,绑定es的数据目录-v es-logs:/usr/share/elasticsearch/logs:挂载逻辑卷,绑定es的日志目录-v es-plugins:/usr/share/elasticsearch/plugins:挂载逻辑卷,绑定es的插件目录--privileged:授予逻辑卷访问权--network es-net:加入一个名为es-net的网络中-p 9200:9200:端口映射配置
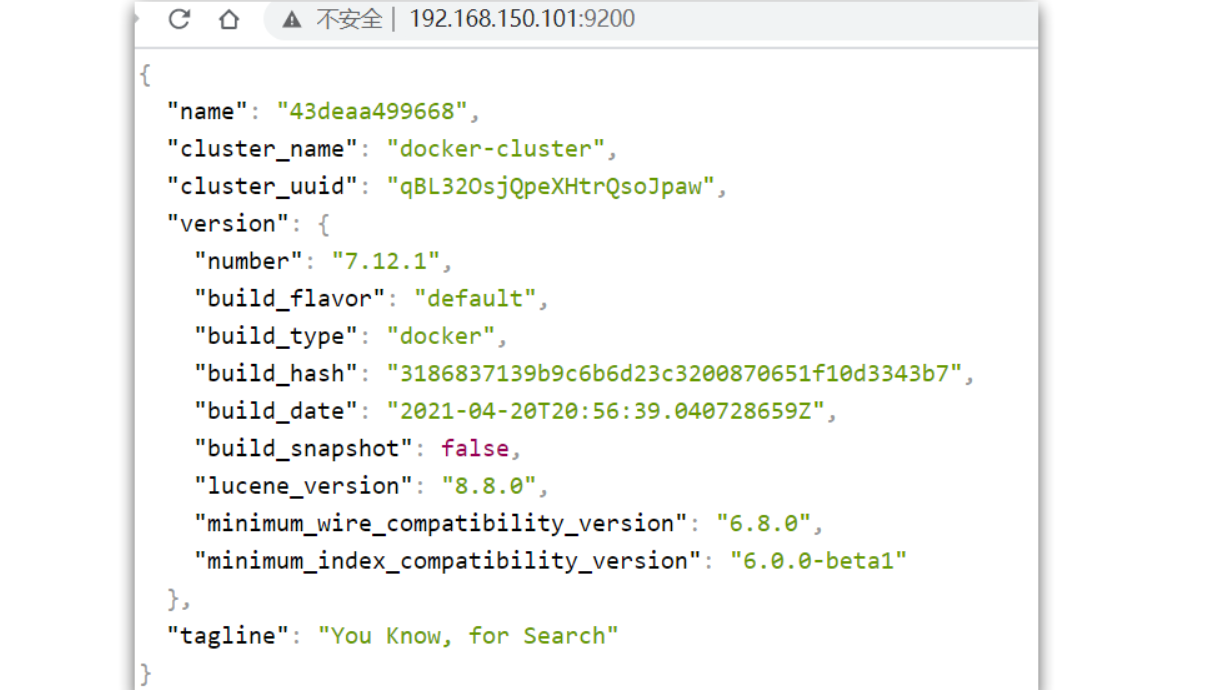
在浏览器中输入:http://服务器地址:9200 即可看到elasticsearch的响应结果:
1.2安装kibana
kibana提供了可视化的界面
1.加载镜像
跟es一样,上传到服务器,再加载
2.运行
docker run -d \--name kibana \-e ELASTICSEARCH_HOSTS=http://es:9200 \--network=es-net \-p 5601:5601 \kibana:7.12.1--network es-net:加入一个名为es-net的网络中,与elasticsearch在同一个网络中-e ELASTICSEARCH_HOSTS=http://es:9200":设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,因此可以用容器名直接访问elasticsearch-p 5601:5601:端口映射配置
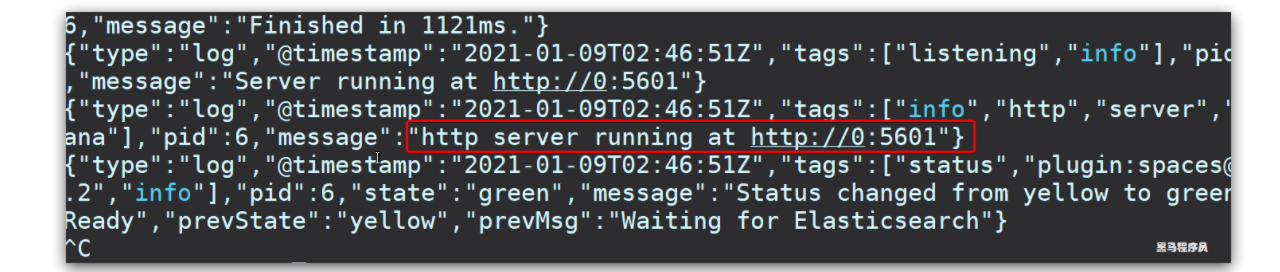
kibana启动一般比较慢,需要多等待一会,可以通过命令:
docker logs -f kibana查看运行日志,当查看到下面的日志,说明成功:
此时,在浏览器输入地址访问:http://服务器地址:5601,即可看到结果
2.安装filebeat
filebeat要安装在你需要采集数据的计算机上,不一定要和es安装在一台机器上
比如我的项目是在本地跑,filebeat就要安在我的本机也就是windows下
1.下载filebeat
https://www.elastic.co/cn/downloads/past-releases/filebeat-7-12-1
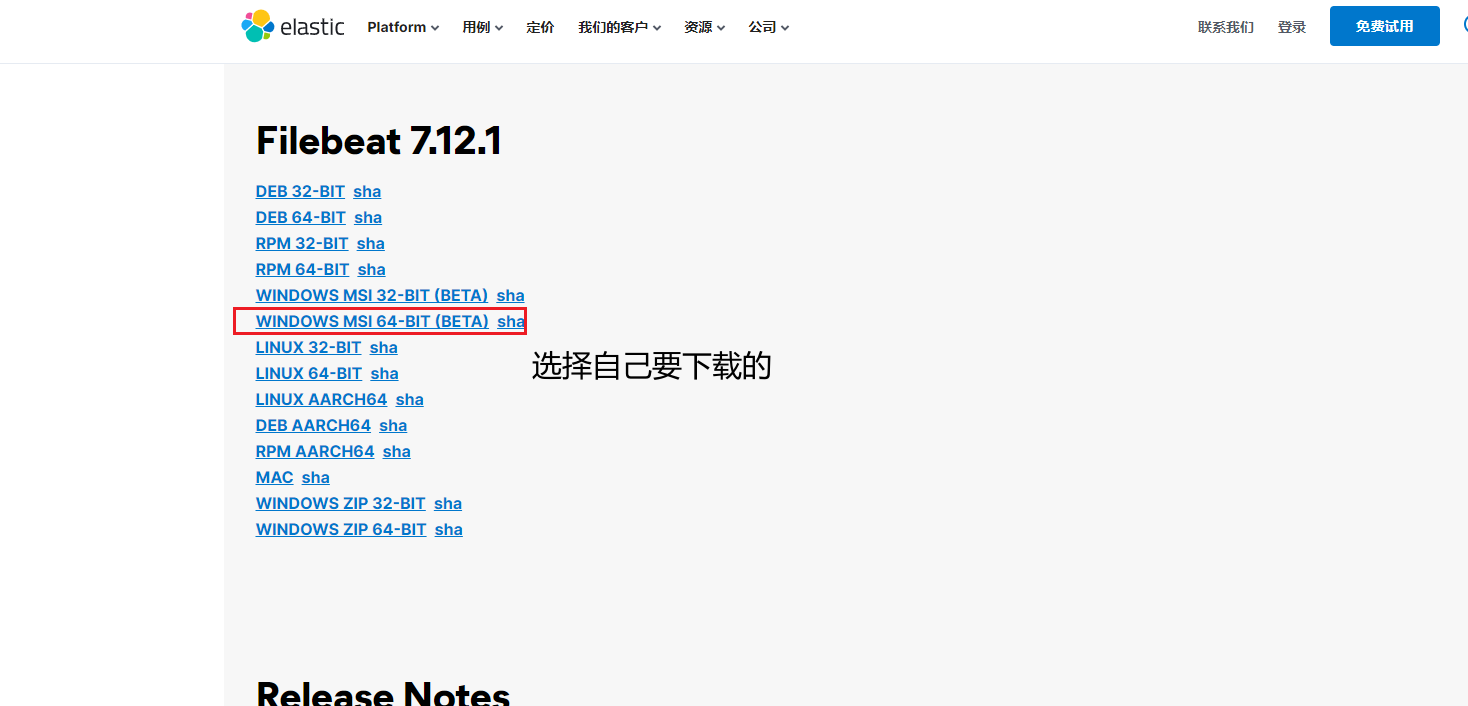
2.编写filebeat.yml
# ============================== Filebeat inputs ===============================filebeat.inputs:- type: log enabled: true encoding: UTF-8 paths: #你需要采集数据的地址,比如这个是我的项目生成log文件的地址 - D:\socialManeger\test1\logs\oper\*.log# ---------------------------- Elasticsearch Output ----------------------------output.elasticsearch:# es 地址 hosts: ["1.14.120.65:9200"] ps:这是最简单的yml,如果要实现过滤或者其他的功能,可以去看看他的配置文件详解
3.运行
进入filebeat的安装目录
filebeat.exe -e -c filebeat.yml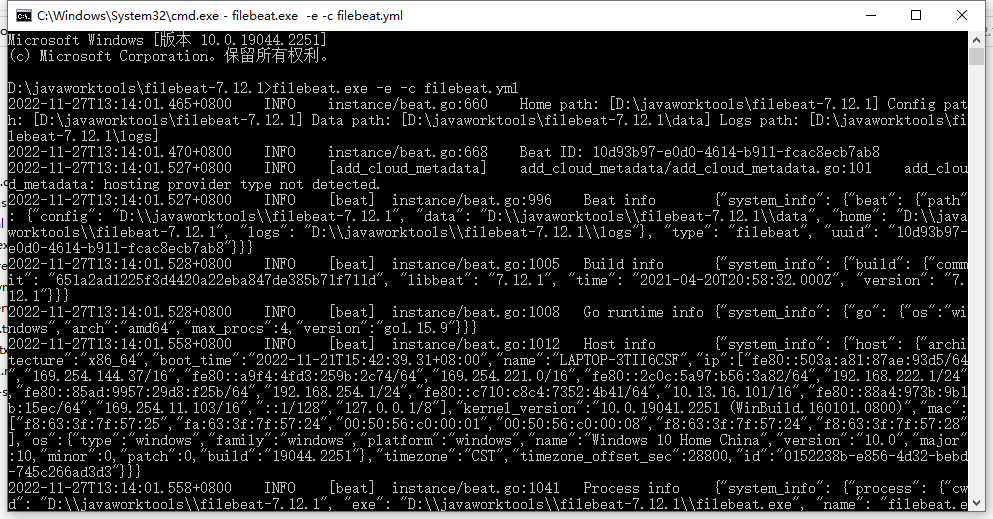
3.整合springboot
1.pom.xml 新增logstash-logback-encoder依赖,logstash-logback-encoder可以将日志以json的方式输出,也不用我们单独处理多行记录问题
net.logstash.logback logstash-logback-encoder 5.32.配置logback-spring.xml
logback debug ${CONSOLE_LOG_PATTERN} UTF-8 ${log.path}/oper/oper.log %msg%n UTF-8 ${log.path}/oper/oper -%d{yyyy-MM-dd}.%i.log 100MB 30 1GB Asia/Shanghai {"message": "%message"} info ACCEPT DENY ${log.path}/error/error.log %d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n UTF-8 ${log.path}/error/error-%d{yyyy-MM-dd}.%i.log 100MB 30 1GB ERROR ACCEPT DENY 启动springboot服务,生成的日志会自动被filebeat采集并推送到es,可以查询
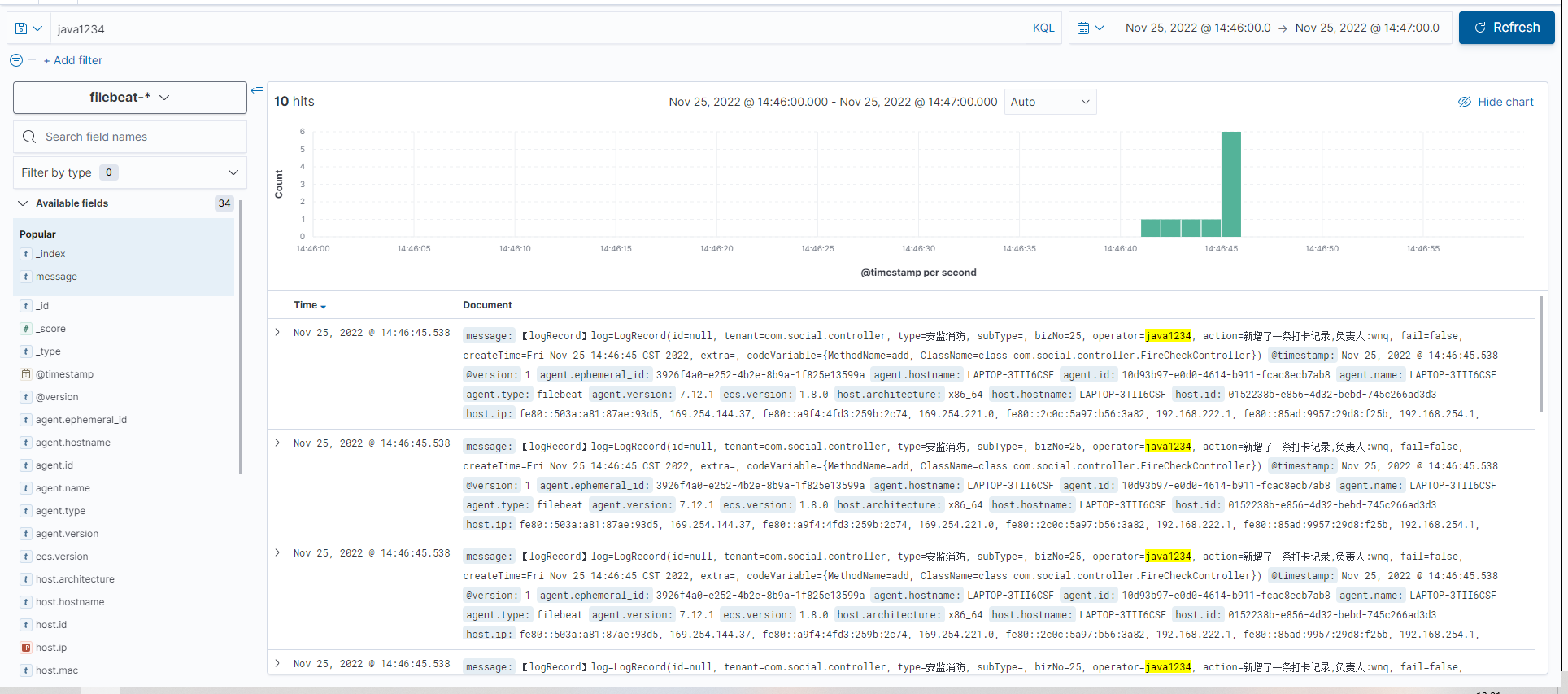
如果想定制fielbeat.yml和logback.xml,可以去找参考资料
logback.xml详解:
logback中文文档:https://www.docs4dev.com/docs/zh/logback/1.3.0-alpha4/reference/architecture.html