闲言少叙,本文记录了如何零基础通过 BCC 框架,入门 eBPF 程序的开发,并实现几个简易的程序。
有关 eBPF 的介绍,网络上的资料有很多,本文暂且先不深入讨论,后面会再出一篇文章详细分析其原理和功能。
我们目前只需要知道,eBPF 实际上是一种过滤器,这种过滤器几乎可以插入内核源码的任意的流程和环节中,实现自定义的逻辑。由于 eBPF 自身的若干限制,使它最常见的用法是,附着在内核某些关键流程上,抓取一些关键数据,用于监控、统计和分析。
1 一个简单的例子
下面是一个简单的例子,我想实现一个程序,用来实时监控内核可执行文件(ELF)的加载。这个程序运行如下:
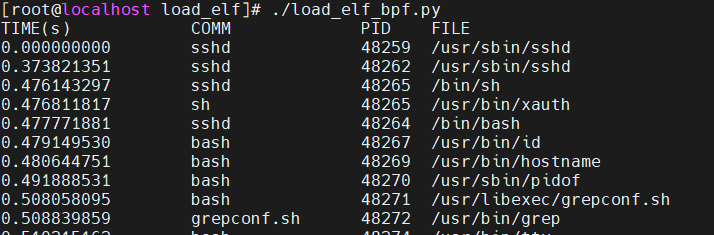
如图所示,每当有一个 ELF 文件被加载时,可以显示这个 ELF 加载时的一些内核信息,如:加载时间、加载进程名、加载进程 PID、以及被加载的 ELF 文件名。
这个程序就是基于 eBPF 实现的。接下来,我们就逐步了解一下,如何通过 BCC 框架,成功编写运行这个 eBPF 程序。
2 BCC 框架
进行 eBPF 编程,有很多种方式。例如:
1)libbpf:使用原生的 C 语言,基于 libbpf 库,编写用户态程序和 BPF 程序的加载;
2)libbpf-bootstrap:使用 libbpf-bootstrap 脚手架,轻而易举地编写 BPF 程序;
3)BCC:使用 BCC 框架,基于 python/Lua 脚本,实现 BPF 和用户态程序,上手容易,简化了 BPF 的开发;
4)Bpftrace:一种用于eBPF的高级跟踪语言,使用LLVM作为后端,将脚本编译为BPF字节码;
5)eunomia-bpf:较新的基于 libbpf 的 CO-RE 轻量级框架,简化了 eBPF 程序的开发、构建、分发、运行
选择 BCC 框架作为第一个学习的框架的原因是,BCC 封装较好,上手容易,用户态和内核态的区分明显,用户态支持 Python,易于理解。
安装过程很简单,直接通过对应软件包管理器安装即可。
本文的实验环境是 REHL 8(x86),因此,执行 yum 命令来安装。
yum install -y python3-bcc.x86_642.1 编写 hello world
安装好 Python BCC 依赖包后,在工作目录中创建一个 py 脚本文件,输入以下代码:
#!/bin/python3from bcc import BPFbpf_code = '''int kprobe__sys_clone(void *ctx) { bpf_trace_printk("Hello world!\\n"); return 0;}'''b = BPF(text=bpf_code)b.trace_print()运行这个 py 脚本,当有进程被创建时,打印一条 Hello world 记录。
这就是一个最简单的 eBPF 程序。
3 扩展这个 Hello world
上面给出的这个程序结构很清晰,分为两个部分:以 C 编写的 eBPF 内核态程序,和以 Python 编写的用户态控制程序。eBPF 内核态程序被 BCC 框架编译到内核中,等待预设的触发条件,——这里是 sys_clone 即进程创建的系统调用,eBPF 被执行时,将会返回数据给用户态控制程序。
流程可以描述如下:
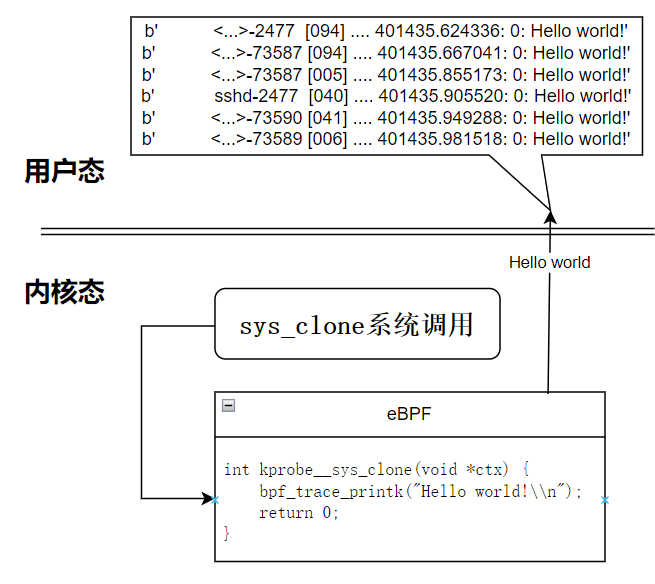
接下来我们对这个程序进行亿点点扩展,让它变得规范一些,代码如下:
#!/bin/python3from bcc import BPFfrom bcc.utils import printb# define BPF programprog = """int hello(void *ctx) { bpf_trace_printk("Hello, World!\\n"); return 0;}"""# load BPF programb = BPF(text=prog)b.attach_kprobe(event=b.get_syscall_fnname("clone"), fn_name="hello")# headerprint("%-18s %-16s %-6s %s" % ("TIME(s)", "COMM", "PID", "MESSAGE"))# format outputwhile 1: try: (task, pid, cpu, flags, ts, msg) = b.trace_fields() except ValueError: continue except KeyboardInterrupt: exit() printb(b"%-18.9f %-16s %-6d %s" % (ts, task, pid, msg))在这段程序中,我们做出了以下几点变动:
1)使用 event=b.get_syscall_fnname("clone") 来绑定内核中的系统调用监视点,这里绑定了 clone 进程创建调用;使用 fn_name="hello" 绑定了 eBPF 程序中的自定义检查逻辑;使用 b.attach_kprobe() 函数将 eBPF 程序加载到内核中。
2)使用 b.trace_fields() 函数按字段的形式,接收内核 eBPF 程序传出的输出信息;其中,msg 为 bpf_trace_printk() 的打印信息。
3)通过无限循环,监测 clone 系统调用的执行;增加了异常输出。
这段程序运行后,输出结果如下:

4 进一步扩展,监视 do_execve
第 3 节的代码,输出内核字段的方式是 bpf_trace_printk() + trace_fields(),比较灵活,但性能较差。实际上,还有一种比较常见的输出方式,那就是通过一段共享内存 Ring buffer 来实现。
此外,这次我们更换一个内核监视点,不再关注进程的创建,而关注进程的执行。
接下来,对上面的代码进行大刀阔斧的修改吧。
文件拆分:
// do_execve.c#include // #define NAME_MAX255#include // struct filename;#include // #define TASK_COMM_LEN16// 定义 Buffer 中的数据结构,用于内核态和用户态的数据交换struct data_t {u32 pid;char comm[TASK_COMM_LEN];char fname[NAME_MAX];};BPF_PERF_OUTPUT(events);// 自定义 hook 函数int check_do_execve(struct pt_regs *ctx, struct filename *filename, const char __user *const __user *__argv, const char __user *const __user *__envp) {truct data_t data = { };data.pid = bpf_get_current_pid_tgid();bpf_get_current_comm(&data.comm, sizeof(data.comm));bpf_probe_read_kernel_str(&data.fname, sizeof(data.fname), (void *)filename->name);// 提交 buffer 数据events.perf_submit(ctx, &data, sizeof(data));return 0;}# do_execve.py#!/bin/python3from bcc import BPFfrom bcc.utils import printb# 指定 eBPF 源码文件b = BPF(src_file="do_execve.c")# 以内核函数的方式绑定 eBPF 探针b.attach_kprobe(event="do_execve", fn_name="check_do_execve")print("%-6s %-16s %-16s" % ("PID", "COMM", "FILE"))# 自定义回调函数def print_event(cpu, data, size):event = b["events"].event(data)printb(b"%-6d %-16s %-16s" % (event.pid, event.comm, event.fname))# 指定 buffer 名称,为 buffer 的修改添加回调函数b["events"].open_perf_buffer(print_event)while 1:try:# 循环监听b.perf_buffer_poll()except KeyboardInterrupt:exit()这一次,我们又进行了亿点点修改:
1)首先,对 eBPF BCC 程序的用户态和内核态代码进行拆分,并在用户态程序中,通过 b = BPF(src_file="do_execve.c") 对内核态源码文件进行绑定。
2)以内核函数的方式绑定 eBPF 程序,绑定点为 do_execve(),自定义处理函数为 check_do_execve()。
注意:
可以看到,
check_do_execve()函数的参数分为两部分:① struct pt_regs *ctx;② struct filename *filename, const char __user *const __user *__argv, const char __user *const __user *__envp这是因为,②所代表的,正是内核
do_execve()函数的参数。do_execve()函数签名如下:// fs/exec.cint do_execve(struct filename *filename, const char __user *const __user *__argv, const char __user *const __user *__envp) {...}是的,通过这种方式,几乎可以监控任意一个内核中的函数。
3)内核态程序中,使用了一些 eBPF Helper 函数来进行一些基础的操作和数据获取,例如:
bpf_get_current_pid_tgid()// 获取当前进程 pidbpf_get_current_comm(&data.comm, sizeof(data.comm));// 获取当前进程名 commbpf_probe_read_kernel_str(&data.fname, sizeof(data.fname), (void *)filename->name);// 将数据从内核空间拷贝到用户空间4)内核态程序中,使用 BPF_PERF_OUTPUT(events) 声明 buffer 中的共享变量;使用 events.perf_submit(ctx, &data, sizeof(data)) 提交数据。
用户态程序中,使用 b["events"].open_perf_buffer(print_event) 指定 buffer 名称,为 buffer 的修改添加回调函数 print_event。
运行这段程序,输出如下:

可以看到,这段程序可以实时监控内核进程执行,并输出执行的进程和被执行的文件名。
5 总结
本文通过几个程序 demo,简单介绍了 eBPF BCC 框架的编程方法,并最终实现了一个简单的进程执行的监视工具,可以实时打印被执行的进程信息。
本文开篇所引出的实时监控内核可执行文件(ELF)的加载程序,也就没那个高深莫测了。