性能优化说明:判断数据表里是否有数据,用limit 1/top 1取代求count
近期,数据中心系统负荷大,mysql服务器的CPU动辄高达90%以上。代码和数据表存在很大优化空间。
这里分享一个定时同步数据的Job任务的优化过程。
先上代码
public void executeJob(String jobParameter) { //获取风控个体工商业者信息表数据总计,如果没有任何数据,则需要初始化 int sohoCount = sbhSohoManager.count(); if (sohoCount == 0) { // 首次同步数据 ... } else { // 非首次,增量同步数据 ... }}
从这段代码不难看出来,根据表的数据量来走不同的分支处理逻辑。
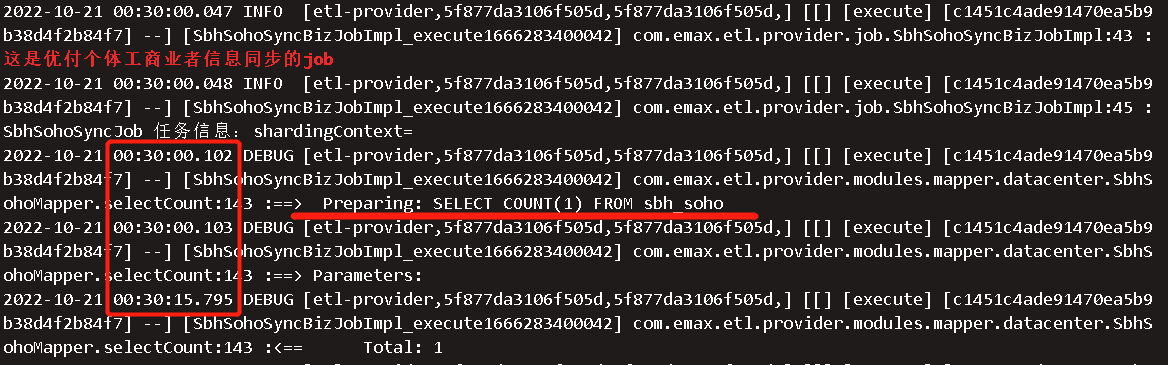
其中,sbhSohoManager#count是mybatisplus原生的count方法。对应SQL是: SELECT COUNT(1) FROM sbh_soho
查log,发现这么一个count,耗时竟然2s~15s。
优化方案
要实现这样一个判断,不用求count,取一条记录的耗时就小到数个ms了。对应的SQL是:SELECT * FROM sbh_soho limit 1
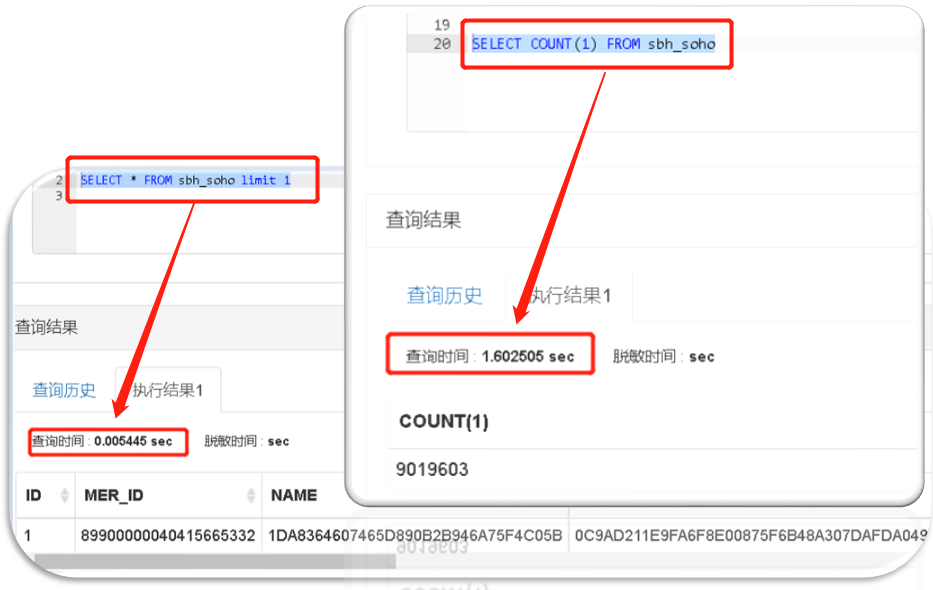
因此改一下逻辑。
public void executeJob(String jobParameter) { //获取风控个体工商业者信息表数据总计,如果没有任何数据,则需要初始化 int sohoCount = sbhSohoManager.hasRecord(); if (sohoCount == 0) { // 首次同步数据 ... } else { // 非首次,增量同步数据 ... }}
其中,sbhSohoManager#hasRecord 巧用mybatisplus的QueryWrapper#last(“limit 1”)实现SQL里的limit,定义如下


/** * 仅判断表里有没有数据 * @return */ public boolean hasRecord(){ QueryWrapper objectQueryWrapper = new QueryWrapper(); objectQueryWrapper.last("limit 1"); SbhSoho sbhSoho =getOne(objectQueryWrapper); //baseMapper.selectOne( null); return sbhSoho!=null; }
View Code还有优化空间
这是一个同步数据的job。定期从源库同步一个表的增量数据到当前库。
基于此,高端的程序员,你也许会想到, 判断是否存在数据其实不用每次查库。
所以,内存/缓存又派上用场了。————————————>另起一段。
当前JobService里定义一个static boolean 的field: isFirstTime,默认值为false。 job首次跑的时候…. 写伪代码吧,描述起来太费脑子费文字还不易懂。
@Servicepublic class SbhSohoSyncBizJobImpl { private static boolean isFirstTime = true; public void executeJob(String jobParameter) { if ( isFirstTime == true) { isFirstTime = ! CacheUtil.getCache("onlyoncekey" + getClass().getSimpleName(), TimeUnit.DAYS.toSeconds(30), () -> sbhSohoManager.hasRecord()); } //获取风控个体工商业者信息表数据总计,如果没有任何数据,则需要初始化 if (isFirstTime == true) { // 首次同步数据 ... } else { // 非首次,增量同步数据 ... } }}
CacheUtil.getCache是利用Redist#get、Redis#set、Supplier封装一个缓存util方法。


当看到一些不好的代码时,会发现我还算优秀;当看到优秀的代码时,也才意识到持续学习的重要!–buguge
本文来自博客园,转载请注明原文链接:https://www.cnblogs.com/buguge/p/16813967.html
hr.signhr{width:80%;margin:0 auto;border: 0;height: 4px;background-image: linear-gradient(to right, rgba(0, 0, 0, 0), rgba(0, 0, 0, 0.75), rgba(0, 0, 0, 0))}