前言
嗨喽~大家好呀,这里是魔王呐 !

国企文员和游戏陪玩两个职业间,你会选择哪个?
00后李明的答案是后者。
今年3月,某二本院校应届毕业生李明,兜兜转转,没有找到特别合心的工作
却凭着还不错的游戏技术,成为了全职的游戏陪玩。
“按单收费,大概一单大概两三百元,按时长收费,一小时50到100元”,李明告诉《财经故事荟》。
身入陪玩半年,李明的月收入高得时候一万三四,低的时候也有八千多元。
面对这样的例子你心不心动,不管你咋样,反正博主心动了~

陪玩衍生于电竞行业,陪玩行业的兴衰也依附于电竞行业。
近年来,电子竞技频频破圈,为陪玩行业的发展提供了绝佳的机遇。
陪玩崛起:电竞产业的衍生,孤独经济的解药
大规模的“空巢游戏青年”,对陪玩服务嗷嗷待需。
那么今天我们就来采集一下陪玩小姐姐数据吧~看看是否真的能月入过万

开发环境:
python 3.8
pycharm
模块使用:
import os: 文件操作
import re: 正则
import requests: 数据请求 —> pip install requests
import json: json数据转换
import csv: 保存csv数据
from tqdm import tqdm: 进度条显示 —> pip install tqdm
import base64: 转换base64格式
如果安装python第三方模块:
win + R 输入 cmd 点击确定, 输入安装命令 pip install 模块名 (pip install requests) 回车
在pycharm中点击Terminal(终端) 输入安装命令
如何配置pycharm里面的python解释器?
选择file(文件) >>> setting(设置) >>> Project(项目) >>> python interpreter(python解释器)
点击齿轮, 选择add
添加python安装路径
==资料、软件、源码教程点击蓝色字体领取,我都放在这里了。==
pycharm如何安装插件?
选择file(文件) >>> setting(设置) >>> Plugins(插件)
点击 Marketplace 输入想要安装的插件名字 比如:翻译插件 输入 translation / 汉化插件 输入 Chinese
选择相应的插件点击 install(安装) 即可
安装成功之后 是会弹出 重启pycharm的选项 点击确定, 重启即可生效
案例思路流程:一. 数据来源分析:
确定需求, 采集那个网站上面什么数据
抓包分析, 通过开发者工具进行抓包分析
开发者工具 会用 1 不会 0 实现爬虫案例必备工具
- F12 刷新网页 清空数据, 点击选择
找相关数据包 –> 请求url 请求方式 得到数据是什么样
二. 代码实现步骤过程:
发送请求, 对于刚刚分析得到url地址发送请求
获取数据, 获取服务器返回响应数据 –> 开发者工具 response
解析数据, 提取我们想要数据内容, 音频试音, 陪玩照片, 基本陪玩数据
保存数据, 保存本地文件夹
代码
导入模块
# 导入数据请求模块 --> 第三方模块 需要在cmd里面或者pycharm终端里面进行安装 pip install requestsimport requests# 导入格式化输出模块 --> 内置模块 不需要安装from pprint import pprint# 导入json模块 --> 内置模块 不需要安装import json# 导入csv模块 --> 内置模块 不需要安装import csvimport os.path
创建文件
c = open('data.csv', mode='a', encoding='utf-8-sig', newline='')# c 文件对象 fieldnames 字段名csv_writer = csv.DictWriter(c, fieldnames=[ '昵称', '价格', '热度', '简介', '详情页',])# 写入表头csv_writer.writeheader()
1. 发送请求, 对于刚刚分析得到url地址发送请求
- headers是否添加, 看网站, 网站没什么反爬的话, 可以不用加
for page in range(1, 11): # --> 1 2 3 4 5 6 7 8 9 10
确定请求网址

==或点击蓝色字体领取完整源码,我都放在这里了。==
# 请求参数 ---> 打座机电话, 都是区号 data = { 'act': 'userList', 'page': page, 'type': '1', 'sex': '2', 'voice': '1', 'order': '1', } # 发送请求 response = requests.post(url=url, data=data)
响应对象 200 状态码表示请求成功
2. 获取数据, 获取服务器返回响应数据 –> 开发者工具 response
response.text 获取响应文本数据 字符串数据类型
response.json() 获取响应json字典数据 字典数据类型
区别数据类型不同
一般情况, 如果服务器返回数据, 带有{}花括号形式, 我们会取response.json(), 可以方便后续取值
3. 解析数据, 提取我们想要数据内容, 音频试音, 陪玩照片, 基本陪玩数据
返回数据字典数据类型, 字典取值 根据冒号左边的内容[键], 提取冒号右边的内容[值] –> 键值对取值
print(index)–> 打印字典数据, 呈现一行
pprint(index)–> 打印字典数据, 呈现多行, 展开效果
“””
# for循环遍历 list 列表 把列表里面的数据一条一条提取出来 for index in response.json()['data']['rows']: # 陪玩基本数据获取 --> 保存表格里面 dit = { '昵称': index['nickname'], '价格': index['price'], '热度': index['exp'], # replace() 字符串替换的方法 replace('替换之前的内容', '替换之后的内容') '简介': index['summary'].replace('\n', ''), # f'{}' 字符串格式化方法 format

4. 保存数据 三个数据
保存音频和图片 –> 发送请求, 获取数据
img_content = requests.get(url=img_url).content # 图片二进制数据 audio_content = requests.get(url=audio_url).content # 音频二进制数据 title = index["nickname"] # 自动创建文件夹 data\\憨憨\\ file = f'data\\{title}\\' # 判断如果没有文件夹 if not os.path.exists(file): # 自动创建文件夹 os.makedirs(file) with open(file + title + '.jpg', mode='wb') as img: img.write(img_content) with open('img\\' + title + '.jpg', mode='wb') as img: img.write(img_content) with open(file + title + '.mp3', mode='wb') as audio: audio.write(audio_content) # 保存表格数据 csv_writer.writerow(dit) print(dit)
效果
下面我们来看一看我们这代码运行的效果吧~

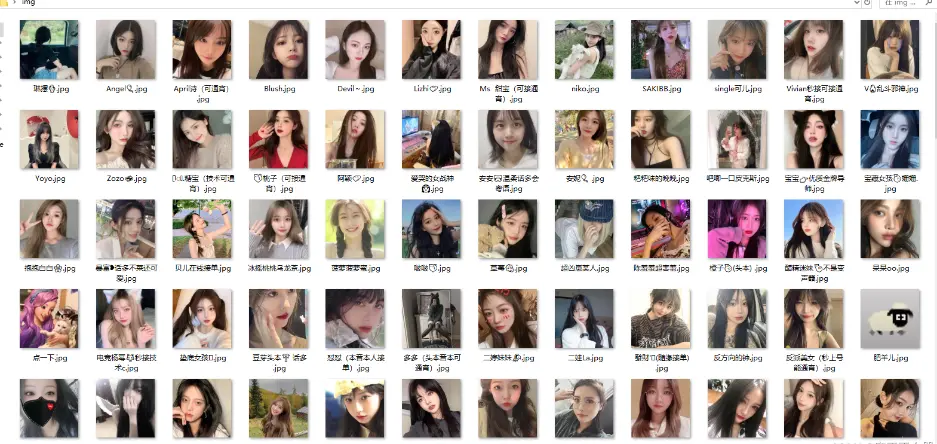











文章看不懂,我专门录了对应的视频讲解,本文只是大致展示,完整代码和视频教程点击下方蓝字
==点击蓝色字体自取,我都放在这里了。==
尾语
要成功,先发疯,下定决心往前冲!
学习是需要长期坚持的,一步一个脚印地走向未来!
未来的你一定会感谢今天学习的你。
—— 心灵鸡汤
本文章到这里就结束啦~感兴趣的小伙伴可以复制代码去试试哦 ?
