1.支持向量机简介
英文名为Support Vector Machine简称为SVM,是一种二分类模型
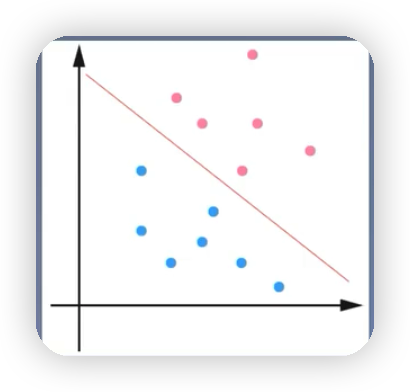
线性可分支持向量机:如下图就可以通过一条红色的直线将蓝色的球和红色的球完全区分开,该直线被称为线性分类器,如果是高维的,就可以通过一个超平面将三维立体空间里的样本点给分开。通过硬间隔最大化,学习一个线性分类器。
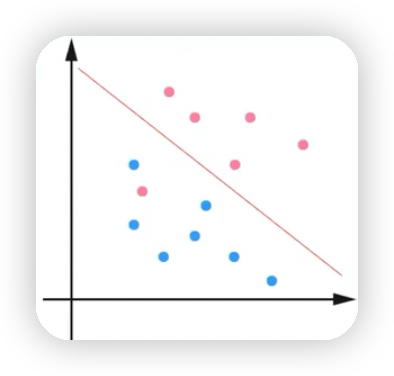
- 线性支持向量机:如下图有一个红色的点无论怎么分,都无法将蓝点的点和红色的点完全区分开,但是这种情况下绝大多数的点都可以通过该直线分割开来,也就是通过软间隔最大化,学习一个线性分类器
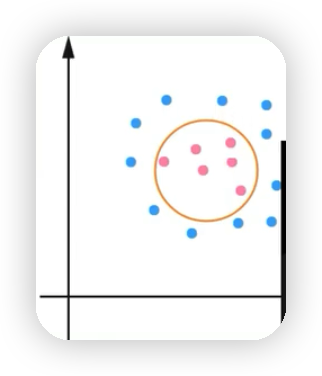
- 非线性支持向量机:如下图将蓝色的点和红色的点区分开的是一个圈并不是通过直线来区分开。也就是通过核技巧,学习一个非线性分类器
- 支持向量:就是支持或支撑平面(间隔平面)上把两类类别划分开来的超平面的向量点,如下图样本点过间隔平面的这些点被称为向量点,这些点组成的向量为支持向量。
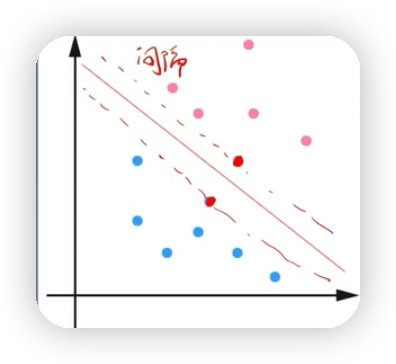
2.线性可分支持向量机如下图,要找到离黑色实线最近的样本点,使得该点到黑线的距离达到最大,该距离可以用我们以前学过的点到直线的距离公式来求
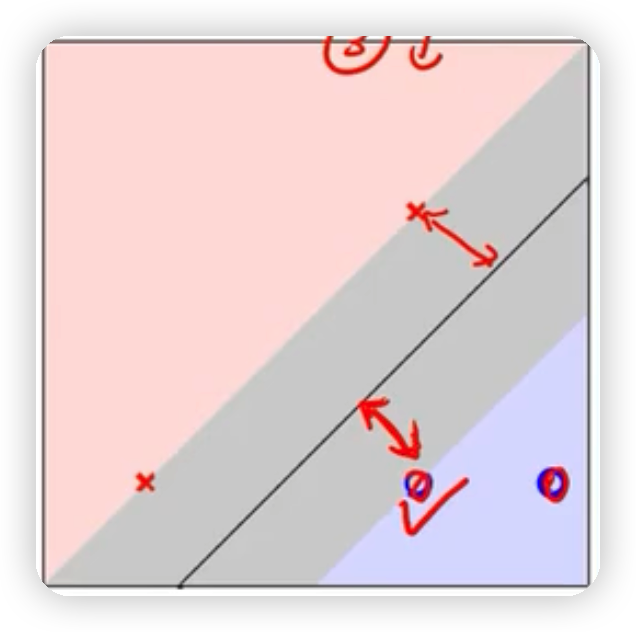
几何间隔
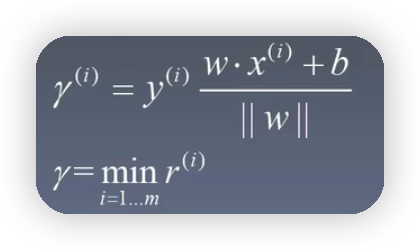

以上公式的来源:假如有一个点(A,B)到直线方程为ax+by+c=0的距离如下图所示
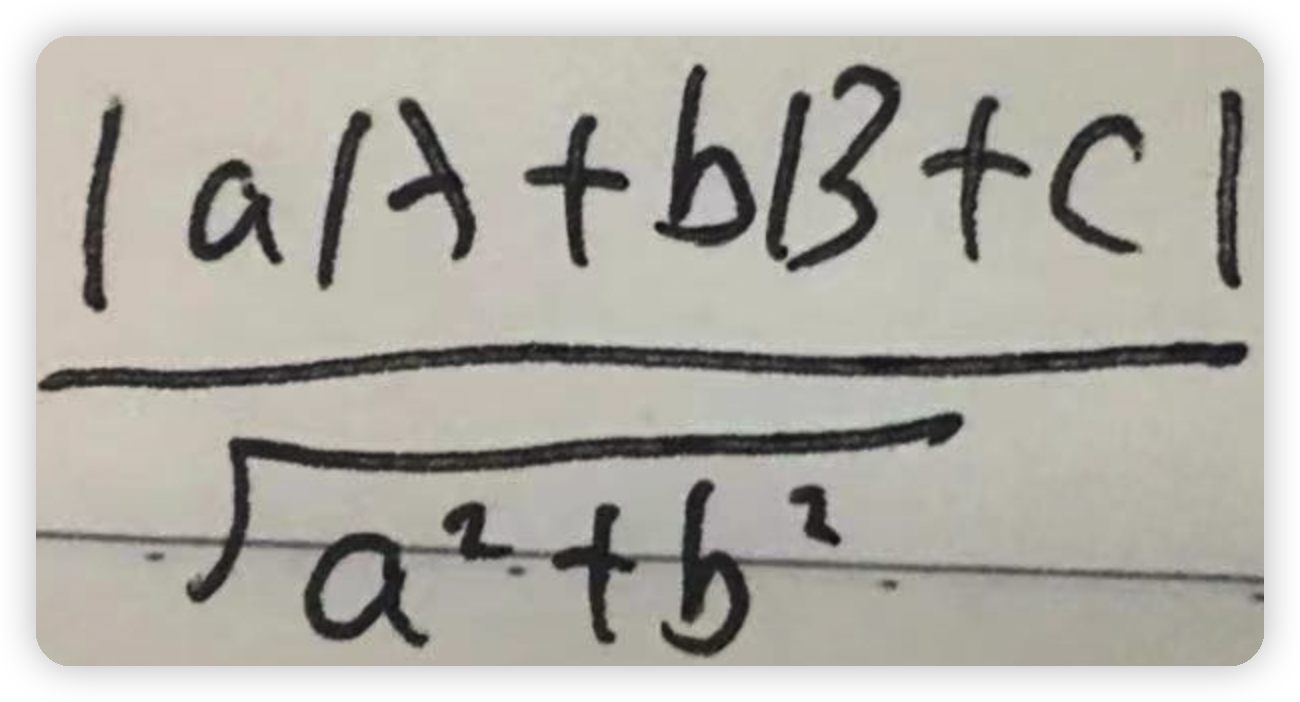
如果将直线方程改为w0x0+w1x1+b=0,那么点到直线的距离就可以改为如下图所示
再进一步化简即可得到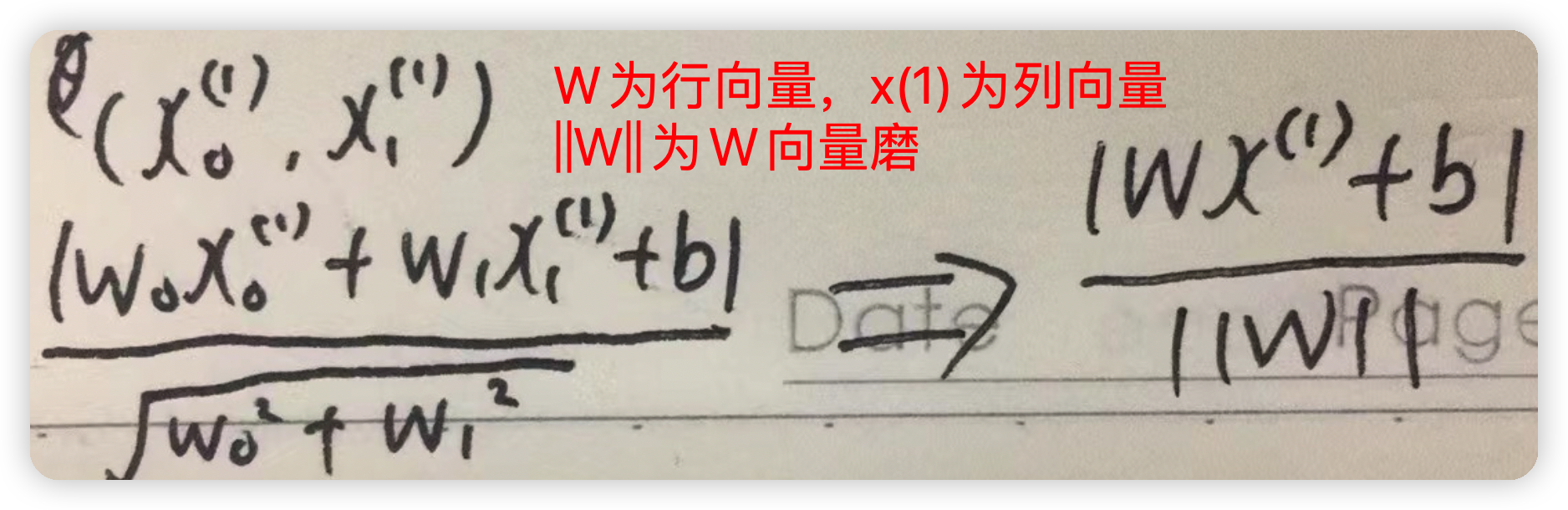
如果当前的样本点属于正样本点,则其y的值为1,反之y的值为-1,所以为了去掉距离公式中的绝对值,可以再前面乘以个y的值,因为如果为负样本,距离值为负,y的值也是负,这样得到的乘积也依然为正,和以前没有乘以y,然后加绝对值得到的结果一致由以上步骤就可以得到几何间隔的公式
函数间隔
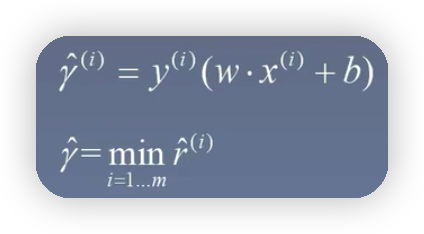
与几何间隔相比较一个最大的区别就是没有了分母的||W||,这样的话,就可以通过缩放方程的系数来更改函数间隔的值,同样也就可以通过缩放系数值,来使得函数间隔的值设置为1,举个简单的例子假设直线方程为2x+y+1=0,样本点的坐标为(1,2),则不难算出集合间隔点到直线的距离为5/根号5,而函数间隔为5;如果将直线方程的系数扩大2倍,也就是变为4x+2*y+2=0,此时算出来的几何间隔的值任然不变,但是函数间隔的值变为10,也就是说通过缩放方程系数的值,可以改变函数间隔的值,而不能改变几何间隔的值两者的关系

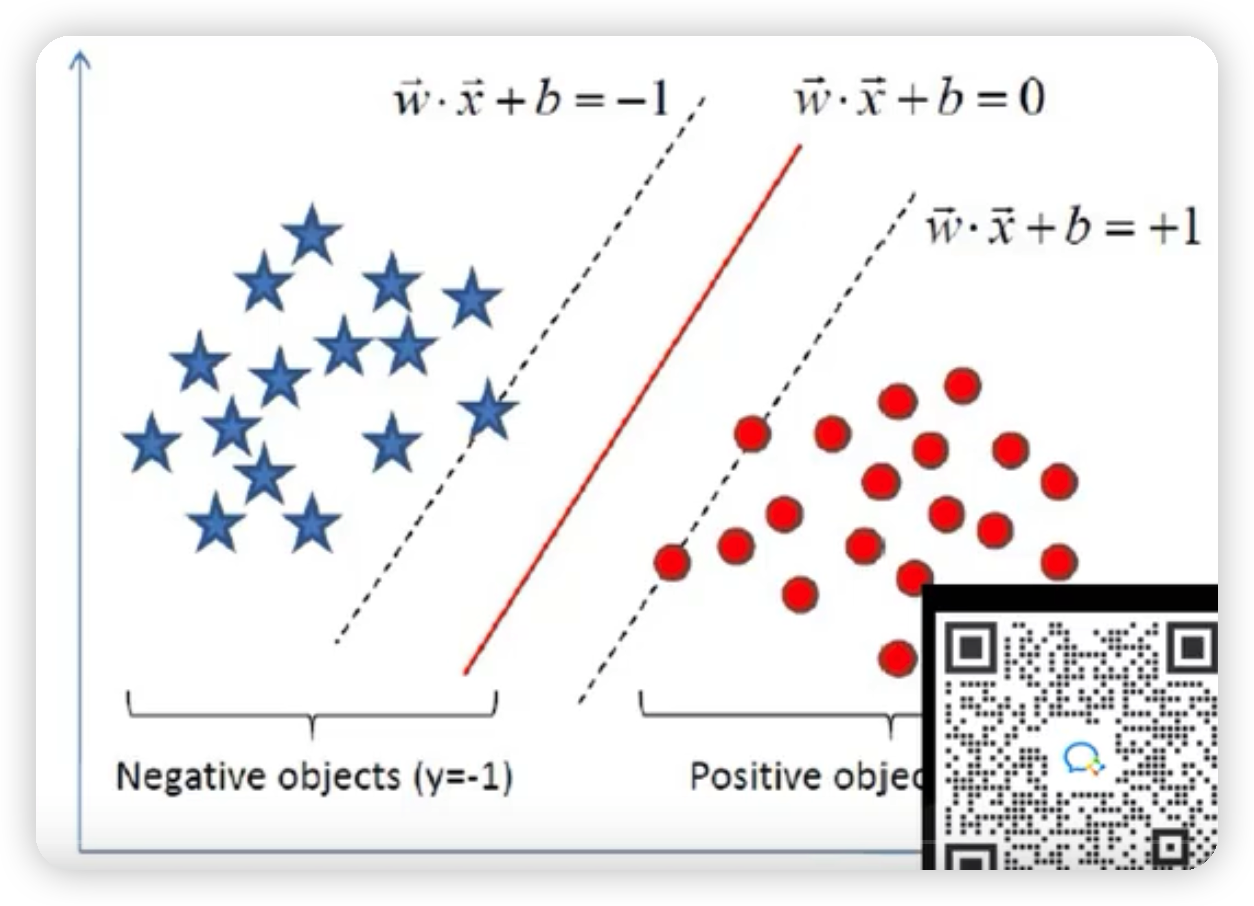
最大间隔分离超平面

3.SVM目标函数的求解

由目标函数构造拉格朗日函数,下图的变量写错了应该是L(w,b,a)

然后对拉格朗日求解

3.1对alpha求最大值

3.2举例求解

求解步骤如下图:

4.线性支持向量机4.1概念有些样本点无论怎么分,都不能用一条直线将样本点完全分开,但是对于绝大多数样本点还是可以通过超平面给分隔开。

4.2目标函数的优化


由上图可知得到的结果与线性可分向量机得到的结果可以说是完全一样,唯一的区别就是约束条件不太一样

5.非线性支持向量机
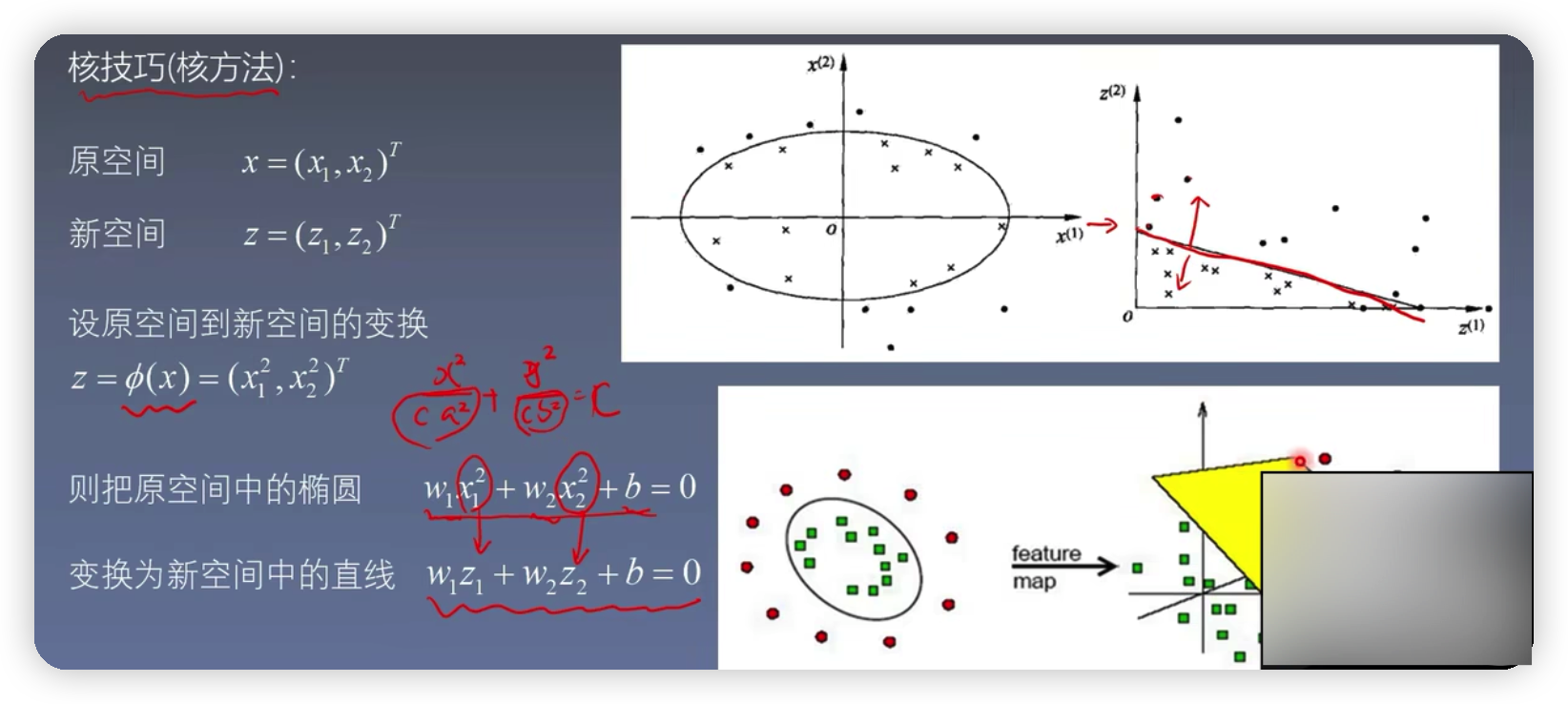
由上图可知在原空间中,用一个椭圆曲线将圆点和xx分开,总所周知,椭圆的方程为x^2 / a^2 + y^2 / b^2,为了使得其与机器学习相关,可以再左右添加一个参数c,然后用w1表示1/c* a^2 , w2表示1 / c*b^2, b表示-c,则椭圆方程可以简化为w1 * x1^2 + w2 * x2^2 + b=0,坐在新空间中存在一种对应关系,使得z1= x1^2 ,z2= x2^2 ,则椭圆方程可以进一步简化为w1 * Z1+ w2 * Z2+b=0,这个过程也被称为核技巧,也就是将元空间的曲线方程,转化为新空间的线性可分的直线方程
由下图可知,当o(x)取不同维数的函数,经过映射之后得到的核函数都是一样的。所以核函数的原理就是通过在低维空间的计算,而去完成在高维空间所能完成的事情


5.SMO算法推导结果如果不知道推导的过程其实也不影响后面的学习,知道每个公式在代码里面怎么用就可以了

5.1SMO算法简易版代码实现
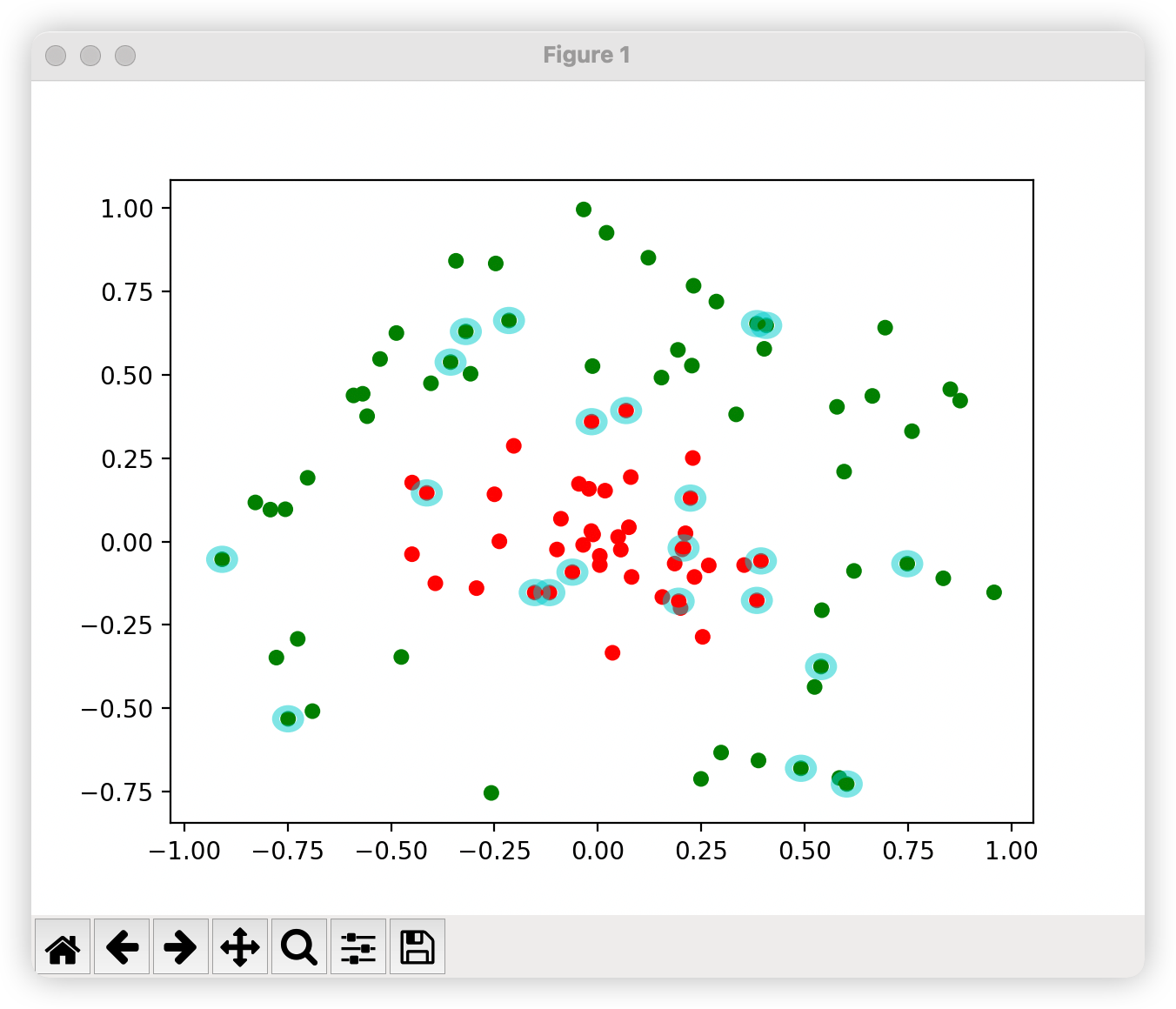
from numpy import *import matplotlib as mplimport matplotlib.pyplot as pltfrom matplotlib.patches import Circledef loadDataSet(fileName): dataMat=[];labelMat=[]#数据集以及标签集分开存储 fr=open(fileName) for line in fr.readlines():#读取文件的每一行数据 lineArr=line.strip().split('\t')#每个数据以空格分开 dataMat.append([float(lineArr[0]),float(lineArr[1])])#将每一行的第一个数据和第二个数据存放在数据集中 labelMat.append(float(lineArr[2]))#每一行的第三个数据存放在标签集中 return dataMat,labelMat#alpha的选取,随机选择一个不等于i值得jdef selectJrand(i,m):#i的值就是当前选定的alpha的值 j=i while(j==i): j=int(random.uniform(0,m)) return j#进行剪辑def clipAlpha(aj,H,L): if aj>H: aj=H if L>aj: aj=L return aj#dataMatIn就是之前讲的公式里的x,classLabels就是之前公式里的y#toler误差值达到多少时可以停止,maxIter迭代次数达到多少是可以停止def smoSimple(dataMatIn,classLabels,C,toler,maxIter): dataMatrix=mat(dataMatIn);labelMat=mat(classLabels).transpose() #初始化b为0 b=0 #获取数据维度 m,n=shape(dataMatrix) #初始化所有alpha为0 alphas=mat(zeros((m,1))) iter=0 #迭代求解 while(iter<maxIter): alphaPairsChanged=0 for i in range(m): #计算g(xi) gXi= float(multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[i,:].T))+b #计算Ei Ei=gXi-float(labelMat[i]) if((labelMat[i]*Ei<-toler) and (alphas[i]toler) and (alphas[i]>0)): #随机选择一个待优化的alpha(先随机出alpha下标) j=selectJrand(i,m) #计算g(xj) gXj = float(multiply(alphas, labelMat).T * (dataMatrix * dataMatrix[j, :].T)) + b #计算Ej Ej = gXj - float(labelMat[j]) #把原来的恶alpha的值复制一份,作为old的值 alphaIold=alphas[i].copy();alpaJold=alphas[j].copy() #计算上下界 if(labelMat[i]!=labelMat[j]): L=max(0,alphas[j]-alphas[i]) H=min(C,C+alphas[j]-alphas[i]) else: L=max(0,alphas[j]+alphas[i]-C) H=min(C,alphas[j]-alphas[i]) if L==H: print("L==H") continue #计算eta:在公式里就是计算K11+K22-2K12,但是这里算的负的eta eta=2*dataMatrix[i,:]*dataMatrix[j,:].T-dataMatrix[i,:]*dataMatrix[i,:].T-dataMatrix[j,:]*dataMatrix[j,:].T if eta>=0: print("eta>=0") continue #计算alpha[j],为了和公式对应把j看出2 alphas[j]-=labelMat[j]*(Ei-Ej)/eta #剪辑alphas[j],为了和公式对应把j看成2 alphas[j]=clipAlpha(alphas[j],H,L) if(abs(alphas[j]-alpaJold)<0.00001): print("j not moving enough") continue #计算alphas[i],为了和公式对应把i看成1 alphas[i] += labelMat[i]*labelMat[j]*(alpaJold-alphas[j]) #计算b1 b1=-Ei-labelMat[i]*(dataMatrix[i,:]*dataMatrix[i,:].T)*(alphas[i]-alphaIold)-labelMat[j]*(dataMatrix[j,:]*dataMatrix[i,:].T)*(alphas[j]-alpaJold)+b #计算b2 b2=-Ej-labelMat[i]*(dataMatrix[i,:]*dataMatrix[j,:].T)*(alphas[i]-alphaIold)-labelMat[j]*(dataMatrix[j,:]*dataMatrix[j,:].T)*(alphas[j]-alpaJold)+b #求解b if(0alphas[j]): b = b1 elif (0alphas[j]): b = b2 else: b=(b1+b2)/2.0 alphaPairsChanged+=1 print("iter:%d i:%d,pairs changed %d" %(iter,i,alphaPairsChanged)) if(alphaPairsChanged==0): iter+=1 else: iter=0 print("iteration number:%d" %iter) return b,alphas#计算w的值def calcWs(dataMat, labelMat, alphas): X=mat(dataMat);labelMat=mat(labelMat).transpose() m,n=shape(X) #初始化w都为1 w=zeros((n,1)) #循环计算 for i in range(m): w+=multiply(alphas[i]*labelMat[i],X[i,:].T) return w#画图def showClassifer(dataMat, labelMat, b,alphas,w): fig=plt.figure() ax=fig.add_subplot(111) cm_dark=mpl.colors.ListedColormap(['g','r']) ax.scatter(array(dataMat)[:,0],array(dataMat)[:,1],c=array(labelMat).squeeze(),cmap=cm_dark,s=30) #画决策平面 x=arange(-2.0,12.0,0.1) y=(-w[0]*x-b)/w[1] ax.plot(x,y.reshape(-1,1)) ax.axis([-2,12,-8,6]) #画支持向量 alphas_non_zeros_index=where(alphas>0) for i in alphas_non_zeros_index[0]: circle= Circle((dataMat[i][0],dataMat[i][1]),0.2,facecolor='none',edgecolor=(0,0.8,0.8),linewidth=3,alpha=0.5) ax.add_patch(circle) plt.show()if __name__ == '__main__': dataMat, labelMat = loadDataSet('testSet.txt') b,alphas=smoSimple(dataMat,labelMat,0.6,0.001,40) w = calcWs(dataMat, labelMat, alphas) showClassifer(dataMat, labelMat, b,alphas,w)画决策平面
x=arange(-2.0,12.0,0.1)y=(-w[0]*x-b)/w[1]ax.plot(x,y.reshape(-1,1))ax.axis([-2,12,-8,6])plt.show()
画支持向量
alphas_non_zeros_index=where(alphas>0)for i in alphas_non_zeros_index[0]: circle= Circle((dataMat[i][0],dataMat[i][1]),0.2,facecolor='none',edgecolor=(0,0.8,0.8),linewidth=3,alpha=0.5) ax.add_patch(circle)plt.show()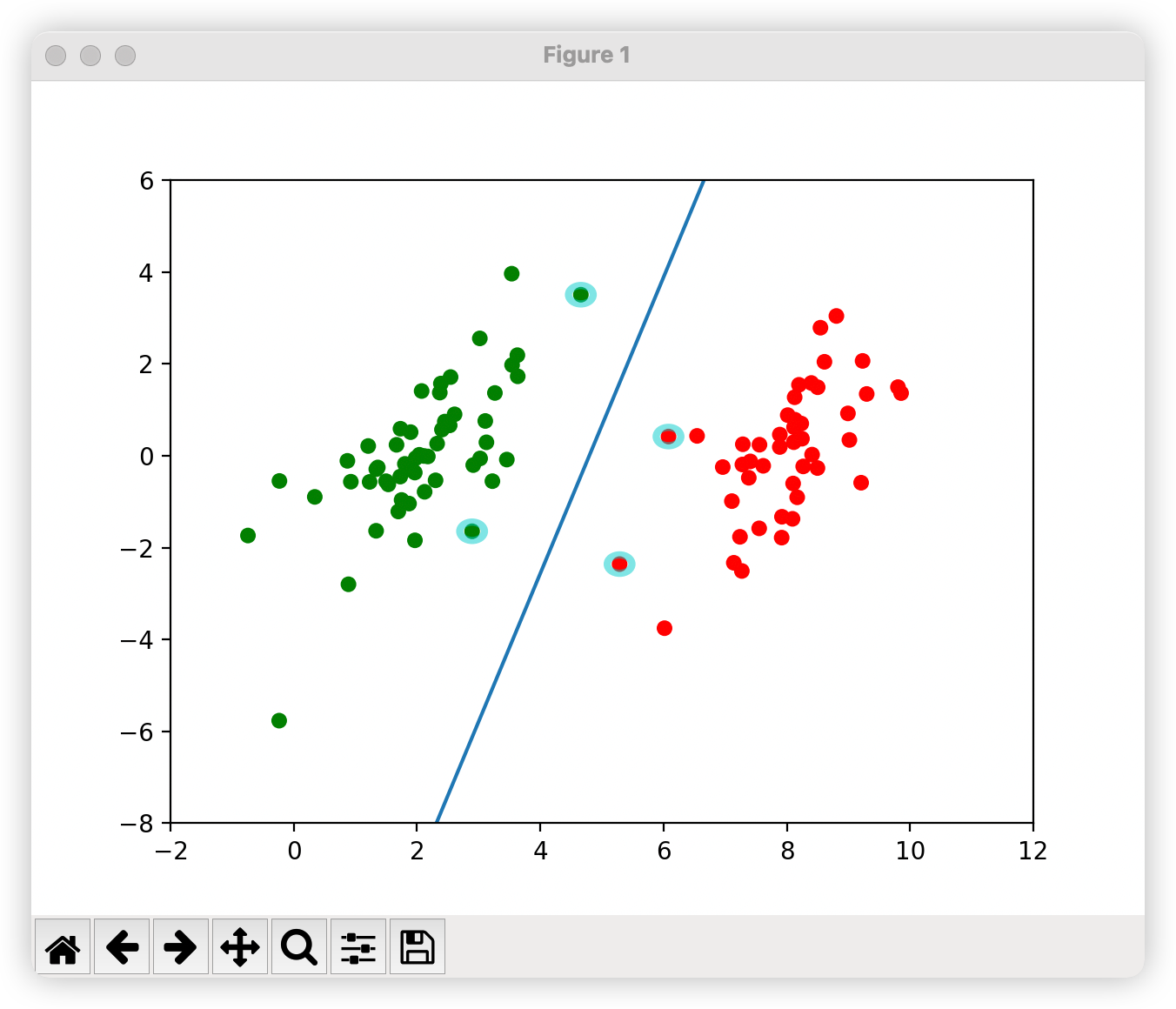
5.2引入核函数
from numpy import *import matplotlib as mplimport matplotlib.pyplot as pltfrom matplotlib.patches import Circleclass optStruct: """ 数据结构,维护所有需要操作的值 Parameters: dataMatIn - 数据矩阵 classLabels - 数据标签 C - 松弛变量 toler - 容错率 """ def __init__(self, dataMatIn, classLabels, C, toler, kTup): self.X = dataMatIn #数据矩阵 self.labelMat = classLabels #数据标签 self.C = C #松弛变量 self.tol = toler #容错率 self.m = shape(dataMatIn)[0] #数据矩阵行数 self.alphas = mat(zeros((self.m,1))) #根据矩阵行数初始化alpha参数为0 self.b = 0 #初始化b参数为0 self.eCache = mat(zeros((self.m,2))) #根据矩阵行数初始化虎误差缓存,第一列为是否有效的标志位,第二列为实际的误差E的值。 self.K = mat(zeros((self.m, self.m))) # 初始化核K for i in range(self.m): # 计算所有数据的核K self.K[:, i] = kernelTrans(self.X, self.X[i, :], kTup)def loadDataSet(fileName): dataMat=[];labelMat=[]#数据集以及标签集分开存储 fr=open(fileName) for line in fr.readlines():#读取文件的每一行数据 lineArr=line.strip().split('\t')#每个数据以空格分开 dataMat.append([float(lineArr[0]),float(lineArr[1])])#将每一行的第一个数据和第二个数据存放在数据集中 labelMat.append(float(lineArr[2]))#每一行的第三个数据存放在标签集中 return dataMat,labelMatdef calcEk(oS, k): """ 计算误差 Parameters: oS - 数据结构 k - 标号为k的数据 Returns: Ek - 标号为k的数据误差 """ fXk = float(multiply(oS.alphas, oS.labelMat).T * oS.K[:, k] + oS.b) Ek = fXk - float(oS.labelMat[k]) return Ekdef selectJ(i, oS, Ei): """ 内循环启发方式2 Parameters: i - 标号为i的数据的索引值 oS - 数据结构 Ei - 标号为i的数据误差 Returns: j, maxK - 标号为j或maxK的数据的索引值 Ej - 标号为j的数据误差 """ maxK = -1; maxDeltaE = 0; Ej = 0 #初始化 oS.eCache[i] = [1,Ei] #设为有效 #根据Ei更新误差缓存 validEcacheList = nonzero(oS.eCache[:,0].A)[0] #返回误差不为0的数据的索引值 if (len(validEcacheList)) > 1: #有不为0的误差 for k in validEcacheList: #迭代所有有效的缓存,找到误差最大的E if k == i: continue #不计算i,浪费时间 Ek = calcEk(oS, k) #计算Ek deltaE = abs(Ei - Ek) #计算|Ei-Ek| if (deltaE > maxDeltaE): #找到maxDeltaE maxK = k; maxDeltaE = deltaE; Ej = Ek return maxK, Ej #返回maxK,Ej else: #没有不为0的误差 j = selectJrand(i, oS.m) #随机选择alpha_j的索引值 Ej = calcEk(oS, j) #计算Ej return j, Ej#跟新缓存def updateEk(oS, k): """ 计算Ek,并更新误差缓存 Parameters: oS - 数据结构 k - 标号为k的数据的索引值 Returns: 无 """ Ek = calcEk(oS, k) #计算Ek oS.eCache[k] = [1,Ek] #更新误差缓存def innerL(i,oS): """ 优化的SMO算法 Parameters: i - 标号为i的数据的索引值 oS - 数据结构 Returns: 1 - 有任意一对alpha值发生变化 0 - 没有任意一对alpha值发生变化或变化太小 """ # 步骤1:计算误差Ei Ei = calcEk(oS, i) # 优化alpha,设定一定的容错率。 if ((oS.labelMat[i] * Ei < -oS.tol) and (oS.alphas[i] oS.tol) and (oS.alphas[i] > 0)): # 使用内循环启发方式2选择alpha_j,并计算Ej j, Ej = selectJ(i, oS, Ei) # 保存更新前的aplpha值,使用深拷贝 alphaIold = oS.alphas[i].copy() alphaJold = oS.alphas[j].copy() # 步骤2:计算上下界L和H if (oS.labelMat[i] != oS.labelMat[j]): L = max(0, oS.alphas[j] - oS.alphas[i]) H = min(oS.C, oS.C + oS.alphas[j] - oS.alphas[i]) else: L = max(0, oS.alphas[j] + oS.alphas[i] - oS.C) H = min(oS.C, oS.alphas[j] + oS.alphas[i]) if L == H: print("L==H") return 0 # 步骤3:计算eta eta = 2.0 * oS.K[i, j] - oS.K[i, i] - oS.K[j, j] if eta >= 0: print("eta>=0") return 0 # 步骤4:更新alpha_j oS.alphas[j] -= oS.labelMat[j] * (Ei - Ej) / eta # 步骤5:修剪alpha_j oS.alphas[j] = clipAlpha(oS.alphas[j], H, L) # 更新Ej至误差缓存 updateEk(oS, j) if (abs(oS.alphas[j] - alphaJold) < 0.00001): print("alpha_j变化太小") return 0 # 步骤6:更新alpha_i oS.alphas[i] += oS.labelMat[j] * oS.labelMat[i] * (alphaJold - oS.alphas[j]) # 更新Ei至误差缓存 updateEk(oS, i) # 步骤7:更新b_1和b_2 b1 = oS.b - Ei - oS.labelMat[i] * (oS.alphas[i] - alphaIold) * oS.K[i, i] - oS.labelMat[j] * ( oS.alphas[j] - alphaJold) * oS.K[i, j] b2 = oS.b - Ej - oS.labelMat[i] * (oS.alphas[i] - alphaIold) * oS.K[i, j] - oS.labelMat[j] * ( oS.alphas[j] - alphaJold) * oS.K[j, j] # 步骤8:根据b_1和b_2更新b if (0 oS.alphas[i]): oS.b = b1 elif (0 oS.alphas[j]): oS.b = b2 else: oS.b = (b1 + b2) / 2.0 return 1 else: return 0#alpha的选取,随机选择一个不等于i值得jdef selectJrand(i,m):#i的值就是当前选定的alpha的值 j=i while(j==i): j=int(random.uniform(0,m)) return j#进行剪辑# aj - alpha值# H - alpha上限# L - alpha下限def clipAlpha(aj,H,L): if aj>H: aj=H if L>aj: aj=L return aj#dataMatIn就是之前讲的公式里的x,classLabels就是之前公式里的y#toler误差值达到多少时可以停止,maxIter迭代次数达到多少是可以停止def smoSimple(dataMatIn,classLabels,C,toler,maxIter,kTup = ('lin',0)): """ 完整的线性SMO算法 Parameters: dataMatIn - 数据矩阵 classLabels - 数据标签 C - 松弛变量 toler - 容错率 maxIter - 最大迭代次数 kTup - 包含核函数信息的元组 Returns: oS.b - SMO算法计算的b oS.alphas - SMO算法计算的alphas """ oS = optStruct(mat(dataMatIn), mat(classLabels).transpose(), C, toler, kTup) #初始化数据结构iter = 0 # 初始化当前迭代次数 iter=0 entireSet = True alphaPairsChanged = 0 while (iter 0) or (entireSet)): # 遍历整个数据集都alpha也没有更新或者超过最大迭代次数,则退出循环 alphaPairsChanged = 0 if entireSet: # 遍历整个数据集 for i in range(oS.m): alphaPairsChanged += innerL(i, oS) # 使用优化的SMO算法 print("全样本遍历:第%d次迭代 样本:%d, alpha优化次数:%d" % (iter, i, alphaPairsChanged)) iter += 1 else: # 遍历非边界值 nonBoundIs = nonzero((oS.alphas.A > 0) * (oS.alphas.A 0) for i in alphas_non_zeros_index[0]: circle= Circle((dataMat[i][0],dataMat[i][1]),0.03,facecolor='none',edgecolor=(0,0.8,0.8),linewidth=3,alpha=0.5) ax.add_patch(circle) plt.show()if __name__ == '__main__': dataMat, labelMat = loadDataSet('testSetRBF.txt') b,alphas=smoSimple(dataMat,labelMat,0.6,0.001,40) w = calcWs(dataMat, labelMat, alphas) showClassifer(dataMat, labelMat, b,alphas,w)运行结果