- GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源。
- GreatSQL是MySQL的国产分支版本,使用上与MySQL一致。
前文回顾
实现一个简单的Database1(译文)
实现一个简单的Database2(译文)
实现一个简单的Database3(译文)
实现一个简单的Database4(译文)
译注:cstsck在github维护了一个简单的、类似SQLite的数据库实现,通过这个简单的项目,可以很好的理解数据库是如何运行的。本文是第五篇,主要是实现数据持久化
Part 5 持久化到磁盘
“Nothing in the world can take the place of persistence.” – Calvin Coolidge(美国第30任总统)
我们数据库能让你插入数据并读取出来,但是只能在程序一直运行的时候才可以。如果你kill掉程序后再次重启以后,你所有的数据就丢失了。
我们期望的行为是这样的,下面是一个spec测试:
it 'keeps data after closing connection' do result1 = run_script([ "insert 1 user1 person1@example.com", ".exit", ]) expect(result1).to match_array([ "db > Executed.", "db > ", ]) result2 = run_script([ "select", ".exit", ]) expect(result2).to match_array([ "db > (1, user1, person1@example.com)", "Executed.", "db > ", ])end像SQLite一样,我们会把数据持久化,保存整个数据库到一个单一的文件中。
我们已经实现了将行序列化为页面大小的内存块。为数据库增加持久化的功能,我们可以简单的把这些内存中的块(blocks)写入到文件,在下次程序启动时,再把这些数据块读取到内存。
为了让实现更简单点,我们创建了一个叫做pager的抽象。我们向pager请求的数据页page号为x(page number x),然后pager会返给我们一个内存块。请求会首先查看内存中的数据,如果内存中没有(缓存未命中,cache miss),pager就会从磁盘上拷贝数据到内存中(通过读取数据库文件)。

我们的程序是如何与 SQLite 架构匹配的
Pager访问页缓存(page cache)和文件。表对象(Table object)通过Pager请求数据页(pages):
+typedef struct {+ int file_descriptor;+ uint32_t file_length;+ void* pages[TABLE_MAX_PAGES];+} Pager;+ typedef struct {- void* pages[TABLE_MAX_PAGES];+ Pager* pager; uint32_t num_rows; } Table;因为new_table()有了打开一个数据库连接的效果,所以我把new_table()重命名为db_open()。
打开一个连接的含义是:
- 打开数据库文件
- 初始化一个Pager数据结构
- 初始化一个table数据结构
-Table* new_table() {+Table* db_open(const char* filename) {+ Pager* pager = pager_open(filename);+ uint32_t num_rows = pager->file_length / ROW_SIZE;+ Table* table = malloc(sizeof(Table));- table->num_rows = 0;+ table->pager = pager;+ table->num_rows = num_rows; return table; }db_open() 接下来调用 pager_open(),pager_open() 会打开数据库文件并跟踪文件的大小。它也会初始化页缓存(page cache)为NULL(NULL 在 C 语言中为一个宏,定义为: #define NULL 0,也就是0)。
+Pager* pager_open(const char* filename) {+ int fd = open(filename,+ O_RDWR | // Read/Write mode+ O_CREAT, // Create file if it does not exist+ S_IWUSR | // User write permission+ S_IRUSR // User read permission+ );++ if (fd == -1) {+ printf("Unable to open file\n");+ exit(EXIT_FAILURE);+ }++ off_t file_length = lseek(fd, 0, SEEK_END);++ Pager* pager = malloc(sizeof(Pager));+ pager->file_descriptor = fd;+ pager->file_length = file_length;++ for (uint32_t i = 0; i pages[i] = NULL;+ }++ return pager;+}有了上面的Pager的抽象,我们把获取一个页面(fetch a page)的逻辑移动到它自己的方法里:
void* row_slot(Table* table, uint32_t row_num) { uint32_t page_num = row_num / ROWS_PER_PAGE;- void* page = table->pages[page_num];- if (page == NULL) {- // Allocate memory only when we try to access page- page = table->pages[page_num] = malloc(PAGE_SIZE);- }+ void* page = get_page(table->pager, page_num); uint32_t row_offset = row_num % ROWS_PER_PAGE; uint32_t byte_offset = row_offset * ROW_SIZE; return page + byte_offset;}
get_page() 方法有处理缓存未命中(cache miss)的逻辑。我们假设数据页一个接一个地保存在数据库文件中:
Page 0 在 offset 0
page 1 在 offset 4096
page 2 在 offset 8192
等等。
如果请求的page在文件的边界之外,那我们就知道它应该是空白,所以我们只需要分配一些内存并返回它就可以了。当我们flush这些缓存到磁盘时,这些page就会添加到文件中。
+void* get_page(Pager* pager, uint32_t page_num) {+ if (page_num > TABLE_MAX_PAGES) {+ printf("Tried to fetch page number out of bounds. %d > %d\n", page_num,+ TABLE_MAX_PAGES);+ exit(EXIT_FAILURE);+ }++ if (pager->pages[page_num] == NULL) {+ // Cache miss. Allocate memory and load from file.+ void* page = malloc(PAGE_SIZE);+ uint32_t num_pages = pager->file_length / PAGE_SIZE;++ // We might save a partial page at the end of the file+ if (pager->file_length % PAGE_SIZE) {+ num_pages += 1;+ }++ if (page_num file_descriptor, page_num * PAGE_SIZE, SEEK_SET);+ ssize_t bytes_read = read(pager->file_descriptor, page, PAGE_SIZE);+ if (bytes_read == -1) {+ printf("Error reading file: %d\n", errno);+ exit(EXIT_FAILURE);+ }+ }++ pager->pages[page_num] = page;+ }++ return pager->pages[page_num];+}
现在,我们想一直到用户关闭数据库的连接时候再flush这些缓存到磁盘。当用户退出时,我们就调用新的方法:db_close(),方法执行下面几个操作:
- flush页缓存到磁盘
- 关闭数据文件
- 释放Pager、table数据结构的内存
+void db_close(Table* table) {+ Pager* pager = table->pager;+ uint32_t num_full_pages = table->num_rows // ROWS_PER_PAGE;++ for (uint32_t i = 0; i pages[i] == NULL) {+ continue;+ }+ pager_flush(pager, i, PAGE_SIZE);+ free(pager->pages[i]);+ pager->pages[i] = NULL;+ }++ // There may be a partial page to write to the end of the file+ // This should not be needed after we switch to a B-tree+ uint32_t num_additional_rows = table->num_rows % ROWS_PER_PAGE;+ if (num_additional_rows > 0) {+ uint32_t page_num = num_full_pages;+ if (pager->pages[page_num] != NULL) {+ pager_flush(pager, page_num, num_additional_rows * ROW_SIZE);+ free(pager->pages[page_num]);+ pager->pages[page_num] = NULL;+ }+ }++ int result = close(pager->file_descriptor);+ if (result == -1) {+ printf("Error closing db file.\n");+ exit(EXIT_FAILURE);+ }+ for (uint32_t i = 0; i pages[i];+ if (page) {+ free(page);+ pager->pages[i] = NULL;+ }+ }+ free(pager);+ free(table);+}+-MetaCommandResult do_meta_command(InputBuffer* input_buffer) {+MetaCommandResult do_meta_command(InputBuffer* input_buffer, Table* table) { if (strcmp(input_buffer->buffer, ".exit") == 0) {+ db_close(table); exit(EXIT_SUCCESS); } else { return META_COMMAND_UNRECOGNIZED_COMMAND;_译注:后面作者会把使用array组织page的方式改为B-tree,有些代码只是暂时这样实现,后面还会修改。
在当前的设计中,文件长度是编码存储多少行来决定,所以我们可能会需要在文件的结尾写入部分页面(partial page,页的一部分,并非全页)。这也是为什么 pager_flush() 同时使用页码(page number)和数据页大小(size)两个参数的原因。这不是最好的设计,但是在我们开始实现B-tree之后,他们就会很快的消失了。
+void pager_flush(Pager* pager, uint32_t page_num, uint32_t size) {+ if (pager->pages[page_num] == NULL) {+ printf("Tried to flush null page\n");+ exit(EXIT_FAILURE);+ }++ off_t offset = lseek(pager->file_descriptor, page_num * PAGE_SIZE, SEEK_SET);++ if (offset == -1) {+ printf("Error seeking: %d\n", errno);+ exit(EXIT_FAILURE);+ }++ ssize_t bytes_written =+ write(pager->file_descriptor, pager->pages[page_num], size);++ if (bytes_written == -1) {+ printf("Error writing: %d\n", errno);+ exit(EXIT_FAILURE);+ }+}
最后,我们需要接受一个命令行参数:filname。也不要忘了在 do_meta_command() 添加额外参数:
译注:db_open(filename)返回一个table结构的指针,将这个指针作为参数传给do_meta_command()。
int main(int argc, char* argv[]) {- Table* table = new_table();+ if (argc buffer[0] == '.') {- switch (do_meta_command(input_buffer)) {+ switch (do_meta_command(input_buffer, table)) {
有了这些修改,我们能在关闭然后重新打开数据库时,我们记录仍然还在数据库中。
~ ./db mydb.dbdb > insert 1 cstack foo@bar.comExecuted.db > insert 2 voltorb volty@example.comExecuted.db > .exit~~ ./db mydb.dbdb > select(1, cstack, foo@bar.com)(2, voltorb, volty@example.com)Executed.db > .exit~
为了多找点乐子,让我们看看 mydb.db 文件中数据库是如何存储的。我使用的是 vim 来作为 hex 编辑器来查看文件在内存中是如何布局的:
vim mydb.db:%!xxd
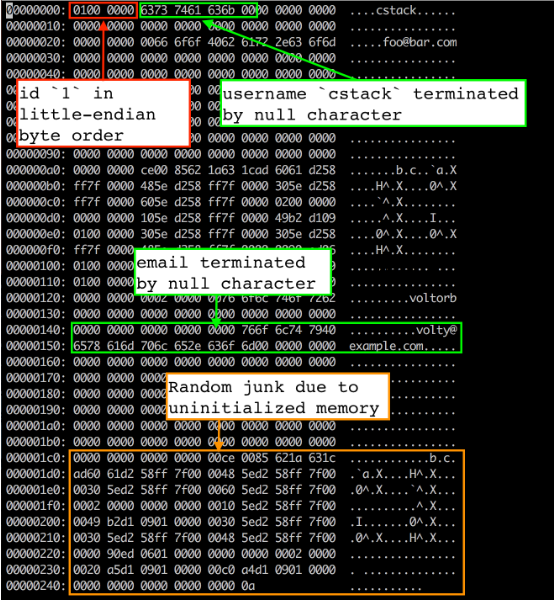

当前的文件布局
前四个字节是第一行数据的id(四个字节是因为我们存储使用的uint32_t类型)。它以小端字节序存储,因此低位字节首先出现 (01),紧跟的是高位字节( (00 00 00))。我们用 memcpy() 从 Row 数据结构拷贝字节到页缓存(page cache)中,这也就意味着这些结构在内存中的布局是小端字节序。这是我编译程序的机器的属性。如果想在我们的机器上写数据文件,然后把它读取到一个大端字节序的机器上,就不得不修改 serialize_row() 和 deserialize_row() 方法(序列化和反序列化)始终使用相同的顺序存储和读取字节。
译注:将多个字节的数据存储在一片连续的地址上,而将数据的各个字节从这片空间的高地址位开始存储还是从低地址位开始存储就决定了系统的存储字节序。大端字节序:高位字节数据存放在低地址处,低位数据存放在高地址处;小端字节序:高位字节数据存放在高地址处,低位数据存放在低地址处。这一般是服务器特性决定的,并不需要特别关注。作者在此浓墨重彩的介绍了一下。
接下来的33字节是存储以null为结尾的 username(占32个字节,未使用位置填充0,结尾以一个字节的null结束)。显然“cstack”在 ASCII 十六进制中是 63 73 74 61 63 6b(占用了6个字节,其余使用0填充),接下来是一个null字符(00)。其余33字节未使用。
接下来的256字节是使用相同方式存储的email(占255个字节,未使用位置填充0,结尾以一个字节的null结束)。在这里能看到在null结束符之后有一些随机的垃圾字符。这很可能是因为在我们的Row结构没有初始化内存导致的。我们拷贝整个256个字节长度 email 缓存写入到文件中,包含了任何在结束符之后的字节。当我们分配该结构内存时,内存中的任何原来的内容还在那里。但是因为我们使用了null结束符,所以它对数据库行为没有影响。
注意:如果我们需要确认所有的字节都被初始化,在 serialize_row() 中拷贝 username 和 email 字段时用 strncpy() 替换 memcpy() 就足够了,像下面这样:
void serialize_row(Row* source, void* destination) { memcpy(destination + ID_OFFSET, &(source->id), ID_SIZE);- memcpy(destination + USERNAME_OFFSET, &(source->username), USERNAME_SIZE);- memcpy(destination + EMAIL_OFFSET, &(source->email), EMAIL_SIZE);+ strncpy(destination + USERNAME_OFFSET, source->username, USERNAME_SIZE);+ strncpy(destination + EMAIL_OFFSET, source->email, EMAIL_SIZE);}
结论
好了!我们实现了持久化。这样实现不是最好的。例如,如果你kill程序而不是执行“.exit”退出,你就会丢失你的更新。此外,我们写回所有数据页到磁盘,尽管数据页自从我们从磁盘读取出来就没有被更新。这些都是我们后面可以解决的问题。
下次我们将要介绍游标(cursors)。这会让我们实现B-tree变得更容易。
在此之前,看一下完整代码对比(与上一部分对比):
+#include +#include #include #include #include #include #include +#include struct InputBuffer_t { char* buffer;@@ -62,9 +65,16 @@ const uint32_t PAGE_SIZE = 4096; const uint32_t ROWS_PER_PAGE = PAGE_SIZE / ROW_SIZE; const uint32_t TABLE_MAX_ROWS = ROWS_PER_PAGE * TABLE_MAX_PAGES;+typedef struct {+ int file_descriptor;+ uint32_t file_length;+ void* pages[TABLE_MAX_PAGES];+} Pager;+ typedef struct { uint32_t num_rows;- void* pages[TABLE_MAX_PAGES];+ Pager* pager; } Table;@@ -84,32 +94,81 @@ void deserialize_row(void *source, Row* destination) { memcpy(&(destination->email), source + EMAIL_OFFSET, EMAIL_SIZE); }+void* get_page(Pager* pager, uint32_t page_num) {+ if (page_num > TABLE_MAX_PAGES) {+ printf("Tried to fetch page number out of bounds. %d > %d\n", page_num,+ TABLE_MAX_PAGES);+ exit(EXIT_FAILURE);+ }++ if (pager->pages[page_num] == NULL) {+ // Cache miss. Allocate memory and load from file.+ void* page = malloc(PAGE_SIZE);+ uint32_t num_pages = pager->file_length / PAGE_SIZE;++ // We might save a partial page at the end of the file+ if (pager->file_length % PAGE_SIZE) {+ num_pages += 1;+ }++ if (page_num file_descriptor, page_num * PAGE_SIZE, SEEK_SET);+ ssize_t bytes_read = read(pager->file_descriptor, page, PAGE_SIZE);+ if (bytes_read == -1) {+ printf("Error reading file: %d\n", errno);+ exit(EXIT_FAILURE);+ }+ }++ pager->pages[page_num] = page;+ }++ return pager->pages[page_num];+}+ void* row_slot(Table* table, uint32_t row_num) { uint32_t page_num = row_num / ROWS_PER_PAGE;- void *page = table->pages[page_num];- if (page == NULL) {- // Allocate memory only when we try to access page- page = table->pages[page_num] = malloc(PAGE_SIZE);- }+ void *page = get_page(table->pager, page_num); uint32_t row_offset = row_num % ROWS_PER_PAGE; uint32_t byte_offset = row_offset * ROW_SIZE; return page + byte_offset; }-Table* new_table() {- Table* table = malloc(sizeof(Table));- table->num_rows = 0;+Pager* pager_open(const char* filename) {+ int fd = open(filename,+ O_RDWR | // Read/Write mode+ O_CREAT,// Create file if it does not exist+ S_IWUSR |// User write permission+ S_IRUSR// User read permission+ );++ if (fd == -1) {+ printf("Unable to open file\n");+ exit(EXIT_FAILURE);+ }++ off_t file_length = lseek(fd, 0, SEEK_END);++ Pager* pager = malloc(sizeof(Pager));+ pager->file_descriptor = fd;+ pager->file_length = file_length;+ for (uint32_t i = 0; i pages[i] = NULL;+ pager->pages[i] = NULL; }- return table;++ return pager; }-void free_table(Table* table) {- for (int i = 0; table->pages[i]; i++) {- free(table->pages[i]);- }- free(table);+Table* db_open(const char* filename) {+ Pager* pager = pager_open(filename);+ uint32_t num_rows = pager->file_length / ROW_SIZE;++ Table* table = malloc(sizeof(Table));+ table->pager = pager;+ table->num_rows = num_rows;++ return table; } InputBuffer* new_input_buffer() {@@ -142,10 +201,76 @@ void close_input_buffer(InputBuffer* input_buffer) { free(input_buffer); }+void pager_flush(Pager* pager, uint32_t page_num, uint32_t size) {+ if (pager->pages[page_num] == NULL) {+ printf("Tried to flush null page\n");+ exit(EXIT_FAILURE);+ }++ off_t offset = lseek(pager->file_descriptor, page_num * PAGE_SIZE,+ SEEK_SET);++ if (offset == -1) {+ printf("Error seeking: %d\n", errno);+ exit(EXIT_FAILURE);+ }++ ssize_t bytes_written = write(+ pager->file_descriptor, pager->pages[page_num], size+ );++ if (bytes_written == -1) {+ printf("Error writing: %d\n", errno);+ exit(EXIT_FAILURE);+ }+}++void db_close(Table* table) {+ Pager* pager = table->pager;+ uint32_t num_full_pages = table->num_rows / ROWS_PER_PAGE;++ for (uint32_t i = 0; i pages[i] == NULL) {+ continue;+ }+ pager_flush(pager, i, PAGE_SIZE);+ free(pager->pages[i]);+ pager->pages[i] = NULL;+ }++ // There may be a partial page to write to the end of the file+ // This should not be needed after we switch to a B-tree+ uint32_t num_additional_rows = table->num_rows % ROWS_PER_PAGE;+ if (num_additional_rows > 0) {+ uint32_t page_num = num_full_pages;+ if (pager->pages[page_num] != NULL) {+ pager_flush(pager, page_num, num_additional_rows * ROW_SIZE);+ free(pager->pages[page_num]);+ pager->pages[page_num] = NULL;+ }+ }++ int result = close(pager->file_descriptor);+ if (result == -1) {+ printf("Error closing db file.\n");+ exit(EXIT_FAILURE);+ }+ for (uint32_t i = 0; i pages[i];+ if (page) {+ free(page);+ pager->pages[i] = NULL;+ }+ }++ free(pager);+ free(table);+}+ MetaCommandResult do_meta_command(InputBuffer* input_buffer, Table *table) { if (strcmp(input_buffer->buffer, ".exit") == 0) { close_input_buffer(input_buffer);- free_table(table);+ db_close(table); exit(EXIT_SUCCESS); } else { return META_COMMAND_UNRECOGNIZED_COMMAND;@@ -182,6 +308,7 @@ PrepareResult prepare_insert(InputBuffer* input_buffer, Statement* statement) { return PREPARE_SUCCESS; }+ PrepareResult prepare_statement(InputBuffer* input_buffer, Statement* statement) { if (strncmp(input_buffer->buffer, "insert", 6) == 0) {@@ -227,7 +354,14 @@ ExecuteResult execute_statement(Statement* statement, Table *table) { } int main(int argc, char* argv[]) {- Table* table = new_table();+ if (argc < 2) {+ printf("Must supply a database filename.\n");+ exit(EXIT_FAILURE);+ }++ char* filename = argv[1];+ Table* table = db_open(filename);+ InputBuffer* input_buffer = new_input_buffer(); while (true) { print_prompt();下面是与上一部分的测试不同的地方:
describe 'database' do+ before do+ `rm -rf test.db`+ end+ def run_script(commands) raw_output = nil- IO.popen("./db", "r+") do |pipe|+ IO.popen("./db test.db", "r+") do |pipe| commands.each do |command| pipe.puts command end@@ -28,6 +32,27 @@ describe 'database' do ]) end+ it 'keeps data after closing connection' do+ result1 = run_script([+ "insert 1 user1 person1@example.com",+ ".exit",+ ])+ expect(result1).to match_array([+ "db > Executed.",+ "db > ",+ ])++ result2 = run_script([+ "select",+ ".exit",+ ])+ expect(result2).to match_array([+ "db > (1, user1, person1@example.com)",+ "Executed.",+ "db > ",+ ])+ end+ it 'prints error message when table is full' do script = (1..1401).map do |i| "insert #{i} user#{i} person#{i}@example.com"
Enjoy GreatSQL ?
关于 GreatSQL
GreatSQL是由万里数据库维护的MySQL分支,专注于提升MGR可靠性及性能,支持InnoDB并行查询特性,是适用于金融级应用的MySQL分支版本。
相关链接: GreatSQL社区GiteeGitHubBilibili
GreatSQL社区:
欢迎来GreatSQL社区发帖提问
https://greatsql.cn/

技术交流群:
微信:扫码添加GreatSQL社区助手微信好友,发送验证信息加群。
