前言
之前我已经将Python的基本语法与Java进行了比较,相信大家对Python也有了一定的了解。我不会选择去写一些无用的业务逻辑来加强对Python的理解。相反,我更喜欢通过编写一些数据结构和算法来加深自己对Python编程的理解。学习任何语言都一样。
通过编写数据结构和算法,不仅可以加强我自己的思维能力,还能提高对Python编程语言的熟练程度。在这个过程中,我会不断地优化我的代码,以提高算法的效率和性能。我相信通过这种方式,我能够更好地掌握Python编程,并且在解决实际问题时能够更加灵活地运用Python的特性和语法。
跳表
今天我们来使用Python实现一个简易版本的跳表。所谓跳表就是一种跳跃式的数据结构。
假设你是一位图书馆管理员,你需要在图书馆的书架上找到一本特定的书。如果图书馆只是一个普通的书架,你需要逐本书进行查找,这样会花费很多时间和精力。
然而,如果图书馆采用了跳表这种数据结构,书架上的书被分成了几个层次,每一层都有一个索引,上面标注了每本书的位置信息。当你需要找到一本书时,你可以先查看最高层的索引,快速定位到可能包含该书的区域,然后再在该区域内根据索引逐步查找,直到找到目标书籍。
这样,跳表的索引层就相当于图书馆的书籍分类系统,它提供了一个快速查找的方法。通过索引层,你可以迅速定位到书籍所在的区域,减少了查找的次数和时间。
跳表主要的思想是利用索引的概念。因此,每个节点除了保存下一个链表节点的地址之外,还需要额外存储索引地址,用于指示下一步要跳转的地址。它在有序链表的基础上增加了多层索引,以提高查找效率。
而且这适合于读多写少的场景。在实现过程中,无论是在插入数据完毕后重新建立索引,还是在插入数据的同时重新建立索引,都会导致之前建立的索引丢弃,浪费了大量时间。而且,如果考虑多线程的情况,情况会更糟糕。写这种东西时,通常先实现一个简单版,然后根据各个环节进行优化,逐步改进算法。因此,我们今天先实现一个简单版的跳表。
具体实现
我们先来实现一个简单版的跳表,不动态规定步长。我们可以先定义一个固定的步长,比如2。
为了实现跳表,我们需要定义一个节点的数据结构。这个节点包含以下信息:当前节点的值(value),指向前一个节点的指针(before_node),指向后一个节点的指针(next_node),以及指向索引节点的指针(index_node)。
class SkipNode: def __init__(self,value,before_node=None,next_node=None,index_node=None): self.value = value self.before_node = before_node self.next_node = next_node self.index_node = index_node head = SkipNode(-1)tail = SkipNode(-1)为了方便操作,我先生成了两个特殊节点,一个是头节点,另一个是尾节点。头节点作为跳表的起始点,尾节点作为跳表的结束点。
数据插入
在跳表中插入节点时,我们按照从小到大的升序进行排序。插入节点时,无需维护索引节点。一旦完成插入操作,我们需要重新规划索引节点,以确保跳表的性能优化。
def insert_node(node): if head.next_node is None: head.next_node = node node.next_node = tail node.before_node = head tail.before_node = node return temp = head.next_node # 当遍历到尾节点时,需要直接插入 while temp.next_node is not None or temp == tail: if temp.value > node.value or temp == tail: before = temp.before_node before.next_node = node temp.before_node = node node.before_node = before node.next_node = temp break temp = temp.next_node re_index()重建索引
为了重新规划索引,我们可以先将之前已经规划好的索引全部删除。然后,我们可以使用步长为2的方式重新规划索引。
def re_index(): step = 2 # 用来建立索引的节点 index_temp = head.next_node # 用来遍历的节点 temp = head.next_node while temp.next_node is not None: temp.index_node = None if step == 0: step = 2 index_temp.index_node = temp index_temp = temp temp = temp.next_node step -= 1查询节点
查询:从头节点开始查询,根据节点的值与目标值进行比较。如果节点的值小于目标值,则向右移动到下一个节点或者索引节点继续比较。如果节点的值等于目标值,则找到了目标节点,返回结果。如果节点的值大于目标值,则则说明目标节点不存在。
def search_node(value): temp = head.next_node step = 0 while temp.next_node is not None: step += 1 if value == temp.value: print(f"该值已找到,经历了{step}次查询") return elif value temp.index_node.value: temp = temp.index_node else: temp = temp.next_node print(f"该值在列表不存在,经历了{step}次查询")遍历
为了方便查看,我特意编写了一个用于遍历和查看当前数据的功能,以便更清楚地了解数据的结构和内容。
def print_node(): my_list = [] temp = head.next_node while temp.next_node is not None: if temp.index_node is not None: my_dict = {"current_value": temp.value, "index_value": temp.index_node.value} else: my_dict = {"current_value": temp.value, "index_value": None} # 设置一个默认值为None my_list.append(my_dict) temp = temp.next_node for item in my_list: print(item)查看结果
所有代码已经准备完毕,现在我们可以在另一个文件中运行并查看跳表的内容和数据。让我们快速进行操作一下。
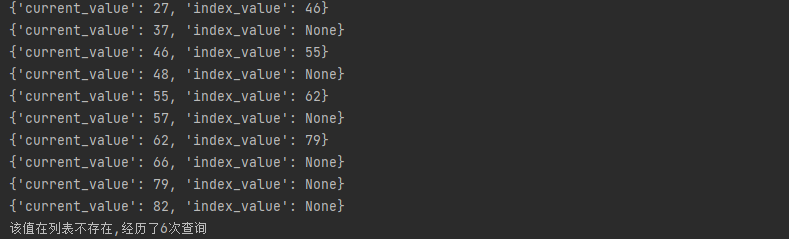
import skipListimport randomfor i in range(0,10): random_number = random.randint(1, 100) temp = skipList.SkipNode(random_number) skipList.insert_node(temp)skipList.print_node()skipList.search_node(89)以下是程序的运行结果。为了方便查看,我特意打印了索引节点的值,以告诉你要跳到哪一个节点。
总结
通过实现一个简易版本的跳表,可以加深了对Python编程的理解。跳表是一种跳跃式的数据结构,通过索引层提供快速查找的能力,提高了查找的效率。在实现跳表的过程中,会更加熟悉了Python的语法和特性,并且可以更加灵活地运用它来解决实际问题。