1. 什么是MVCC
MVCC全称是Multi-Version Concurrency Control(多版本并发控制),是一种并发控制的方法,通过维护一个数据的多个版本,减少读写操作的冲突。
如果没有MVCC,想要实现同一条数据的并发读写,还要保证数据的安全性,就需要操作数据的时候加读锁和写锁,这样就降低了数据库的并发性能。
有了MVCC,就相当于把同一份数据生成了多个版本,在操作的开始各生成一个快照,读写操作互不影响。无需加锁,也实现数据的安全性和事务的隔离性。
事务的四大特性中隔离性就是基于MVCC实现的。
说MVCC的实现原理之前,先说一下事务的隔离级别。
2. 事务的隔离级别
说隔离级别之前,先说一下并发事务产生的问题:
脏读: 一个事务读到其他事务未提交的数据。
不可重复读: 相同的查询条件,多次查询到的结果不一致,即读到其他事务提交后的数据。
幻读: 相同的查询条件,多次查询到的结果不一致,即读到其他事务提交后的数据。
不可重复读与幻读的区别是: 不可重复读是读到了其他事务执行update、delete后的数据,而幻读是读到其他事务执行insert后的数据。
再说一下事务的四大隔离级别:
Read UnCommitted(读未提交): 读到其他事务未提交的数据,会出现脏读、不可重复读、幻读。
Read Committed(读已提交): 读到其他事务已提交的数据,解决了脏读,会出现不可重复读、幻读。
Repeatable Read(可重复读): 相同的条件,多次读取到的结果一致。解决了脏读、不可重复读,会出现幻读。
Serializable(串行化): 所有事务串行执行,解决了脏读、不可重复读、幻读。
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交 | 会 | 会 | 会 |
| 读已提交 | 不会 | 会 | 会 |
| 可重复读 | 不会 | 不会 | 会 |
| 串行化 | 不会 | 不会 | 不会 |
MVCC只在Read Committed和Repeatable Read两个隔离级别下起作用,因为Read UnCommitted隔离级别下,读写都不加锁,Serializable隔离级别下,读写都加锁,也就不需要MVCC了。
再谈一下Undo log日志。
3. Undo Log(回滚日志)
Undo Log记录的是逻辑日志,也就是SQL语句。
比如:当我们执行一条insert语句时,Undo Log就记录一条相反的delete语句。
作用:
回滚事务时,恢复到修改前的数据。
实现 MVCC 。
事务四大特性中原子性也是基于Undo Log实现的。
下面开始谈一下MVCC的实现原理。
4. MVCC的实现原理4.1 当前读和快照读
先普及一下什么是当前读和快照读。
当前读: 读取数据的最新版本,并对数据进行加锁。
例如:insert、update、delete、select for update、 select lock in share mode。
快照读: 读取数据的历史版本,不对数据加锁。
例如:select
MVCC是基于Undo Log、隐藏字段、Read View(读视图)实现的。
4.2 隐藏字段
先说一下MySQL的隐藏字段,当我们创建一张表时,InnoDB引擎会增加2个隐藏字段。
DB_TRX_ID(最近一次提交事务的ID):修改表数据时,都会提交事务,每个事务都有一个唯一的ID,这个字段就记录了最近一次提交事务的ID。
DB_ROLL_PTR(上个版本的地址):修改表数据时,旧版本的数据都会被记录到Undo Log日志中,每个版本的数据都有一个版本地址,这个字段记录的就是上个版本的地址。
4.3 版本链
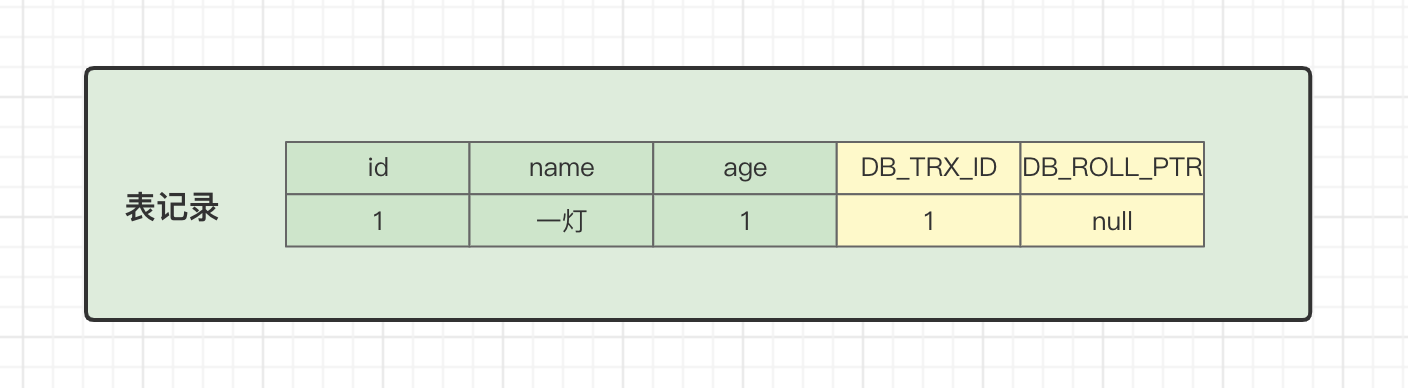
当我们第一次往用户表插入一条记录时,表数据和隐藏字段的值是下面这样的:
insert into user (name,age) values ('一灯',1);事务ID(DB_TRX_ID)是1,上个版本地址(DB_ROLL_PTR)是null。

第二次提交事务,把用户年龄加1。
update user set age=age+1 where id=1;事务ID变成2,上个版本地址指向Undo Log中的记录。
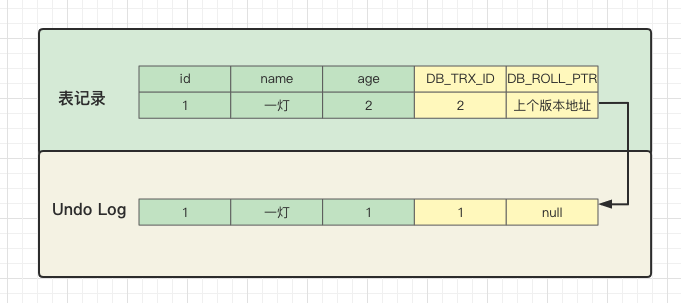
第三次提交事务,再把用户年龄加1。
update user set age=age+1 where id=1;事务ID变成3,上个版本地址指向Undo Log中事务ID为2的记录。
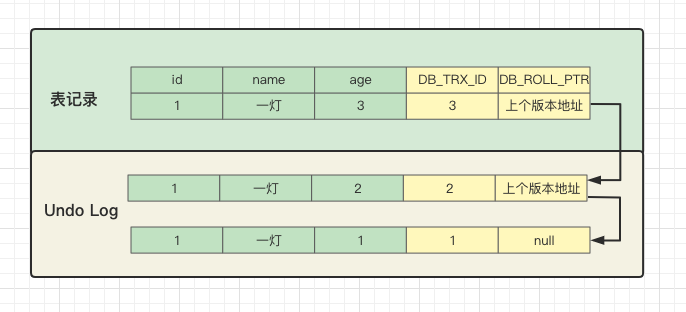
这样表记录和Undo Log历史数据就组成了一个版本链。
4.4 Read View(读视图)
在事务中,执行SQL查询,就会生成一个读视图,是用来保证数据的可见性,即读到Undo Log中哪个版本的数据。
快照读一般是读取的历史版本的读视图,当前图会生成一个最新版本的读视图。
读视图是基于下面几个字段实现的:
m_ids :当前系统中活跃的事务ID集合,即未提交的事务。
min_trx_id :m_ids中最小的ID
max_trx_id :下一个要分配的事务ID
creator_trx_id: 当前事务ID
读视图决定当前事务能读到哪个版本的数据,从表记录到Undo Log历史数据的版本链,依次匹配,满足哪个版本的匹配规则,就能读到哪个版本的数据,一旦匹配成功就不再往下匹配。
数据可见性规则:
- DB_TRX_ID = creator_trx_id
如果这个版本数据的事务ID等于当前事务ID,表示数据记录的最后一次操作的事务就是当前事务,当前读视图可以读到这个版本的数据。 - DB_TRX_ID < min_trx_id
如果这个版本数据的事务ID小于所有活跃事务ID,表示这个版本的数据不再被事务使用,即事务已提交,当前读视图可以读到这个版本的数据。 - DB_TRX_ID >= max_trx_id
如果这个版本数据的事务ID大于等于下一个要分配的事务ID,表示有新事务更新了这个版本的数据,这种情况下,当前读视图不可以读到这个版本的数据。 - min_trx_id <= DB_TRX_ID < max_trx_id
如果这个版本数据的事务ID在当前系统中活跃的事务ID集合(m_ids)里面,表示这个版本的数据被其他事务更新过,当前读视图不可以读到这个版本的数据。
如果这个版本数据的事务ID不在当前系统中活跃的事务ID集合(m_ids)里面,表示是在其他事务提交后创建的读视图,当前读视图可以读到这个版本的数据。
5. 不同隔离级别下可见性分析
在不同的事务隔离级别下,生成读视图的规则不同:
- READ COMMITTED(读已提交) :在事务中每一次执行快照读时都生成一个读视图,每个读视图中四个字段的值都是不同的。
- REPEATABLE READ(可重复读):仅在事务中第一次执行快照读时生成读视图,后续复用这个读视图。
5.1 READ COMMITTED(读已提交)
设置MySQL隔离级别为读已提交:
SET session TRANSACTION ISOLATION LEVEL READ COMMITTED;
执行两个事务,验证一下:

事务1第一次查询时,会生成一个读视图,读视图的各个属性如下:
| 属性 | 值 |
|---|---|
| m_ids | 1,2 |
| min_limit_id | 1 |
| max_limit_id | 3 |
| creator_trx_id | 1 |
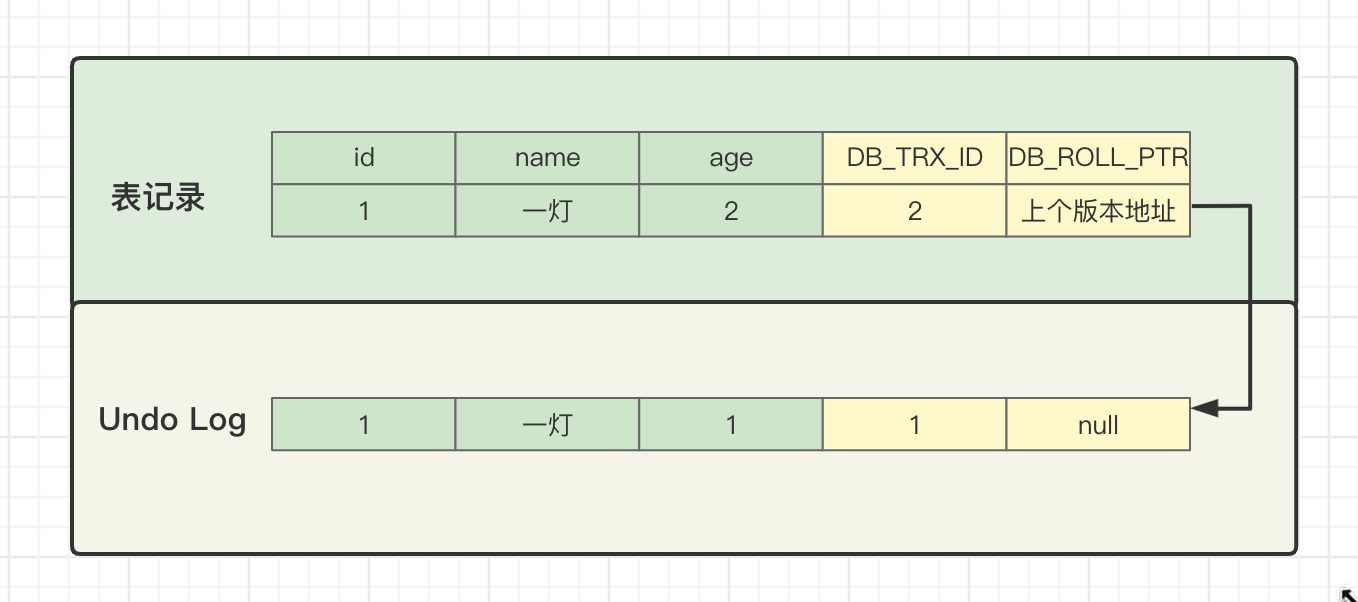
可见的版本链数据是:
符号规则 DB_TRX_ID = creator_trx_id = 1,可以看到当前版本的数据。
事务1第二次查询时,会生成一个新的读视图,读视图的各个属性如下:
| 属性 | 值 |
|---|---|
| m_ids | 1 |
| min_limit_id | 1 |
| max_limit_id | 3 |
| creator_trx_id | 1 |
可见的版本链数据是:
符号规则 min_trx_id <= DB_TRX_ID < max_trx_id(1<=2<3),并且当前数据版本的事务ID不在当前系统中活跃的事务ID集合,可以看到当前版本的数据。

同一个事务内,相同的查询条件,查询到的数据不一致,查到了其他事务更新过的数据,也就是出现了不可重复读的情况。
再看一下,在可重复读隔离级别下,是怎么解决这个问题的。
5.2 REPEATABLE READ(可重复读)
设置MySQL隔离级别为可重复读:
SET session TRANSACTION ISOLATION LEVEL REPEATABLE READ;
执行两个事务,验证一下:

事务1第一次查询时,会生成一个读视图,读视图的各个属性如下:
| 属性 | 值 |
|---|---|
| m_ids | 1,2 |
| min_limit_id | 1 |
| max_limit_id | 3 |
| creator_trx_id | 1 |
可见的版本链数据是:
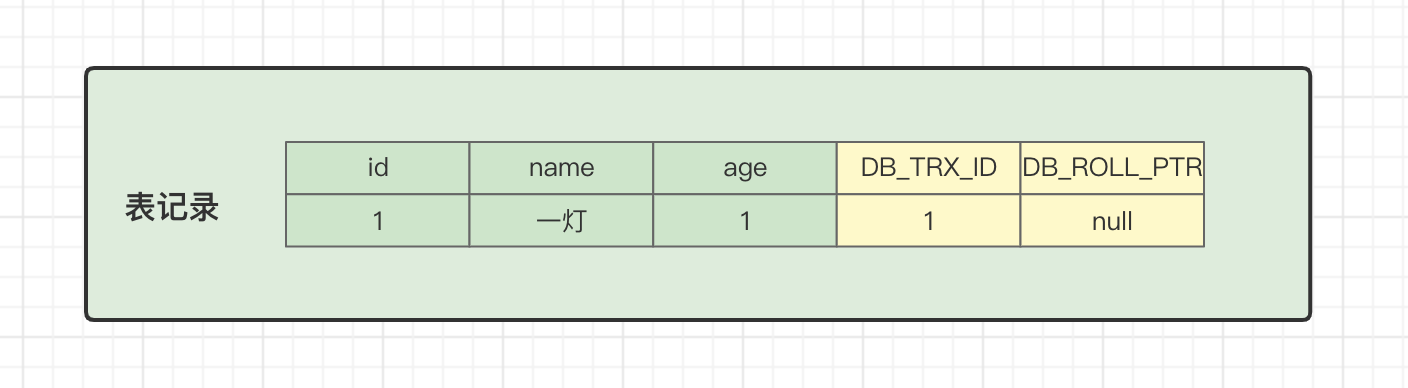
符号规则 DB_TRX_ID = creator_trx_id = 1,可以看到当前版本的数据。
事务1第二次查询时,会复用原有的读视图,读视图的各个属性如下:
| 属性 | 值 |
|---|---|
| m_ids | 1,2 |
| min_limit_id | 1 |
| max_limit_id | 3 |
| creator_trx_id | 1 |
可见的版本链数据是:

符号规则 min_trx_id <= DB_TRX_ID < max_trx_id(1<=2<3),并且当前数据版本的事务ID在当前系统中活跃的事务ID集合,所以是不可以看到当前版本的数据。
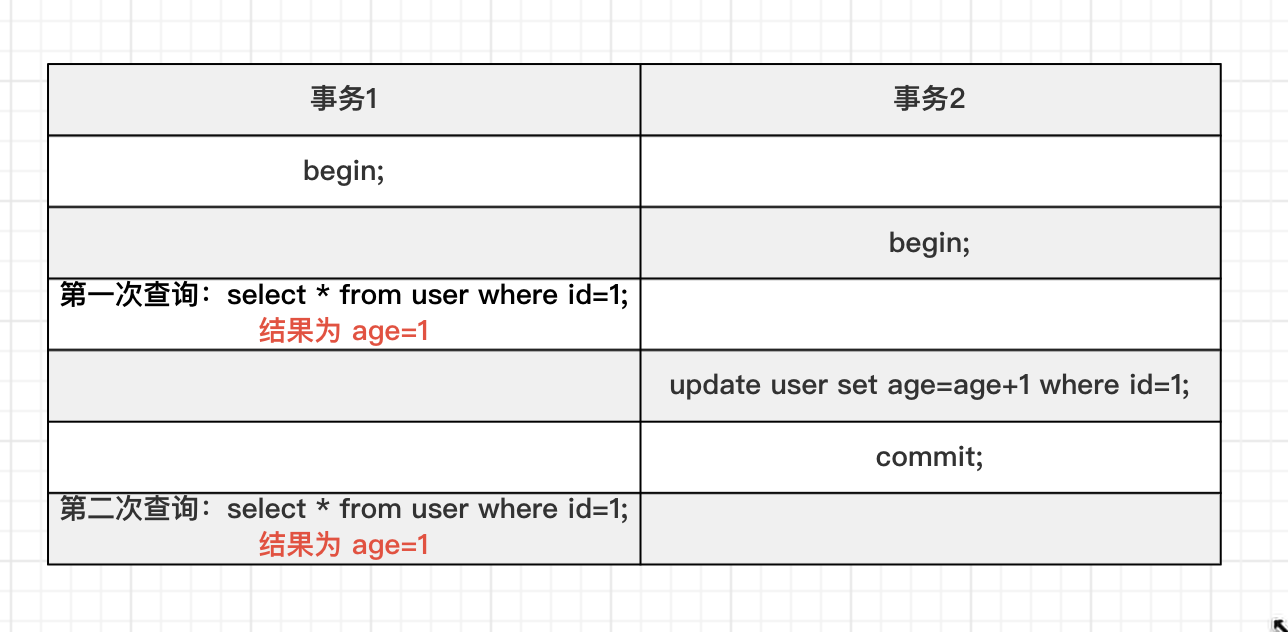
由此得知,可重复读隔离级别下,相同的查询条件,两次查询到的结果相同,也就是解决了可重复读的问题,是通过复用原有的读视图的方式解决的。