作者:马伟,青云科技容器顾问,云原生爱好者,目前专注于云原生技术,云原生领域技术栈涉及 Kubernetes、KubeSphere、KubeKey 等。
2019 年,我在给很多企业部署虚拟化,介绍虚拟网络和虚拟存储。
2023 年,这些企业都已经上了云原生了。对于高流量的 Web 应用程序,实时数据分析,大规模数据处理、移动应用程序等业务,容器比虚拟机更适合,因为它轻量级,快速响应,可轻松移植,并具有很强的弹性伸缩能力。
为什么需要弹性伸缩呢?
- 峰值负载应对:促销活动、节假日购物季或突发事件根据需求快速扩展资源,保证应用可用性和性能。
- 提高资源利用率:根据实际资源负载动态调整资源规模,避免基础设施资源浪费,降低 TCO。
- 应对故障和容错:多实例部署和快速替换,提高业务连续性和可用性。
- 跟随需求变化:匹配前端的业务需求及压力,快速调整规模,提高事件应对能力,满足需求和期望。
Horizontal Pod Autoscaling
Kubernetes 自身提供一种弹性伸缩的机制,包括 Vertical Pod Autoscaler (VPA)和 Horizontal Pod Autoscaler (HPA)。HPA 根据 CPU 、内存利用率增加或减少副本控制器的 pod 数量,它是一个扩缩资源规模的功能特性。
HPA 依赖 Metrics-Server 捕获 CPU、内存数据来提供资源使用测量数据,也可以根据自定义指标(如 Prometheus)进行扩缩。
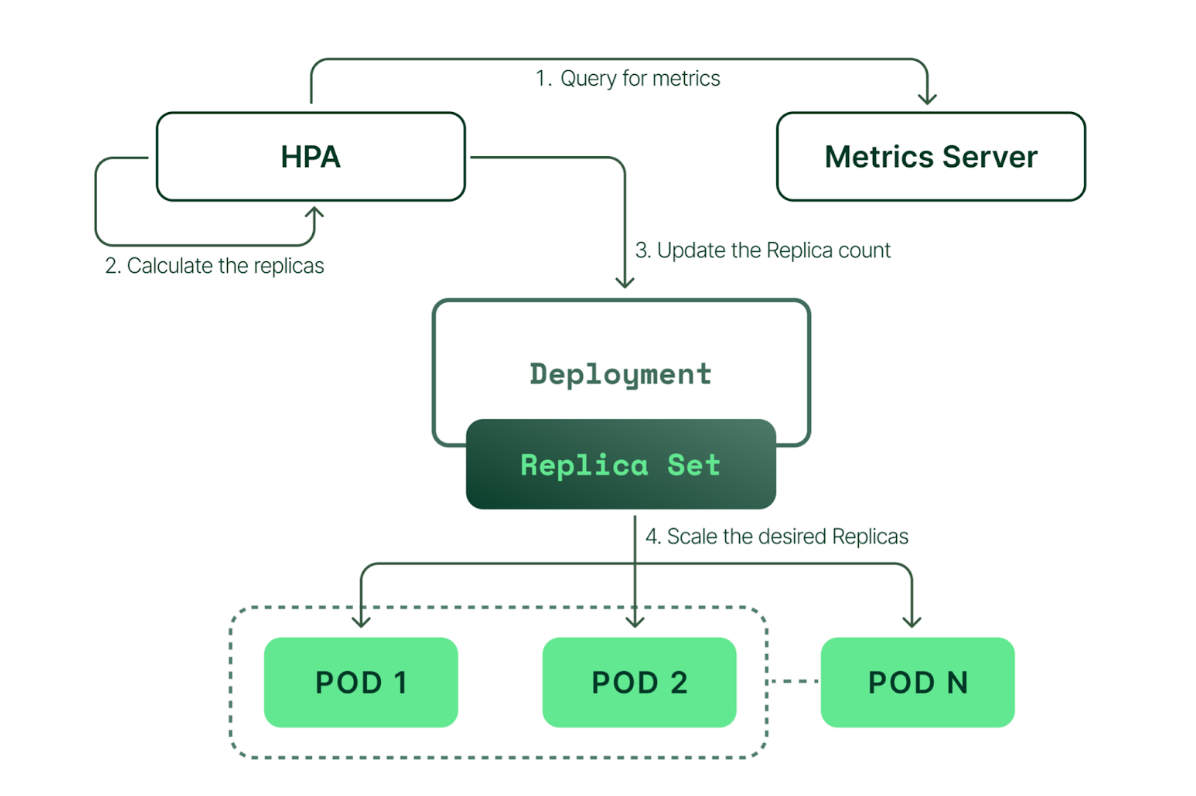
由上图看出,HPA 持续监控 Metrics-Server 的指标情况,然后计算所需的副本数动态调整资源副本,实现设置目标资源值的水平伸缩。
但也有一定局限性:
- 无外部指标支持。如不同的事件源,不同的中间件/应用程序等,业务端的应用程序变化及依赖是多样的,不只是基于 CPU 和内存扩展。
- 无法 1->0。应用程序总有 0 负载的时候,此时不能不运行工作负载吗?
所以就有了Kubernetes-based Event-Driven Autoscaling(KEDA)!
KEDA
KEDA 基于事件驱动进行自动伸缩。什么是事件驱动?我理解是对系统上的各种事件做出反应并采取相应行动(伸缩)。那么 KEDA 就是一个 HPA+多种触发器。只要触发器收到某个事件被触发,KEDA 就可以使用 HPA 进行自动伸缩了,并且,KEDA 可以 1-0,0-1!
架构
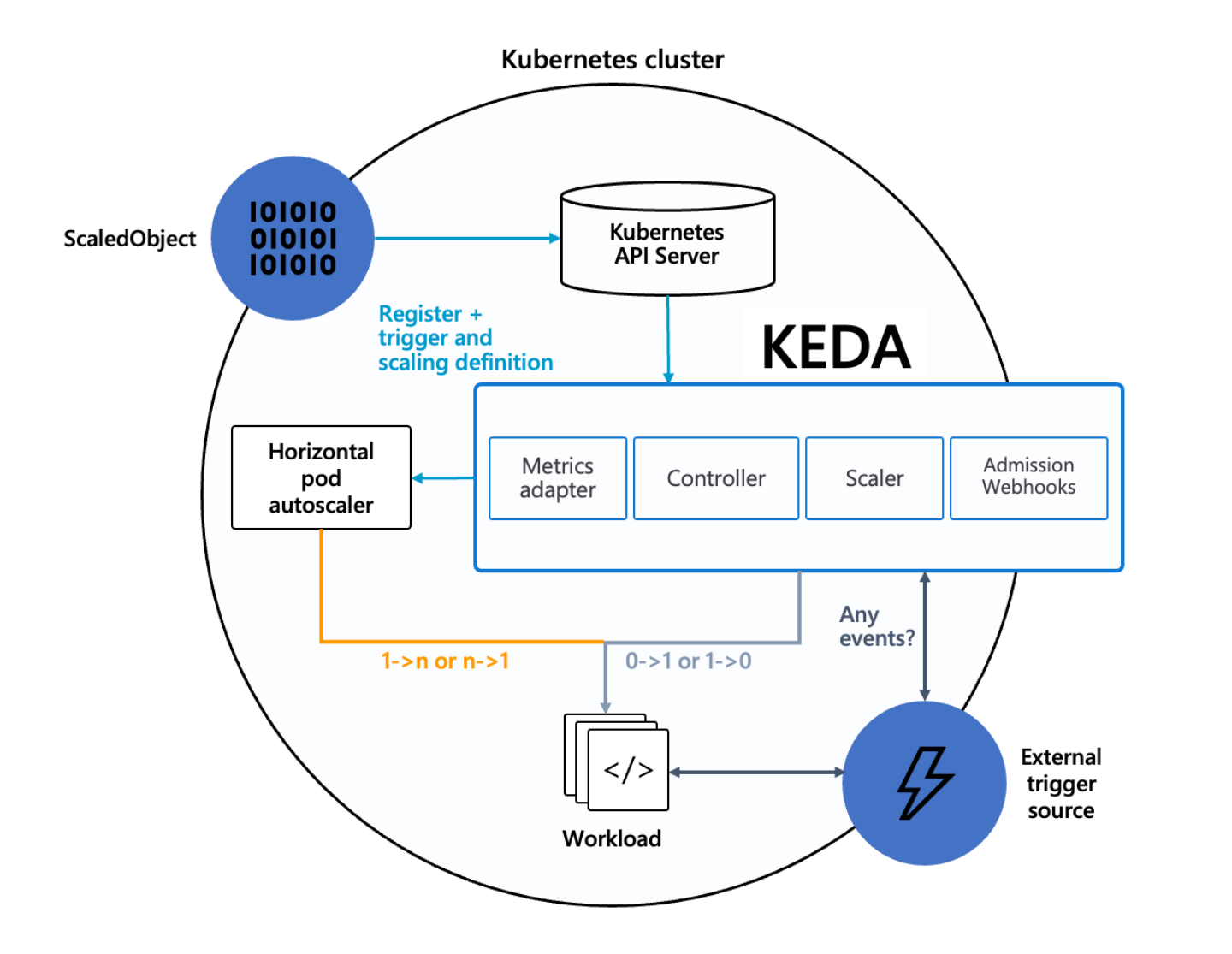
KEDA 自身有几个组件:
- Agent: KEDA 激活和停止 Kubernetes 工作负载(keda-operator 主要功能)
- Metrics: KEDA 作为一个 Kubernetes 指标服务器,向 Horizontal Pod Autoscaler 提供丰富的事件数据,从源头上消费事件。(keda-operator-metrics-apiserver 主要作用)。
- Admission Webhooks: 自动验证资源变化,以防止错误配置。
- Event sources: KEDA 更改 pod 数量的外部事件/触发源。如 Prometheus、Kafka。
- Scalers: 监视事件源,获取指标并根据事件触发伸缩。
- Metrics adapter:从 Scalers 获取指标并发送给 HPA。
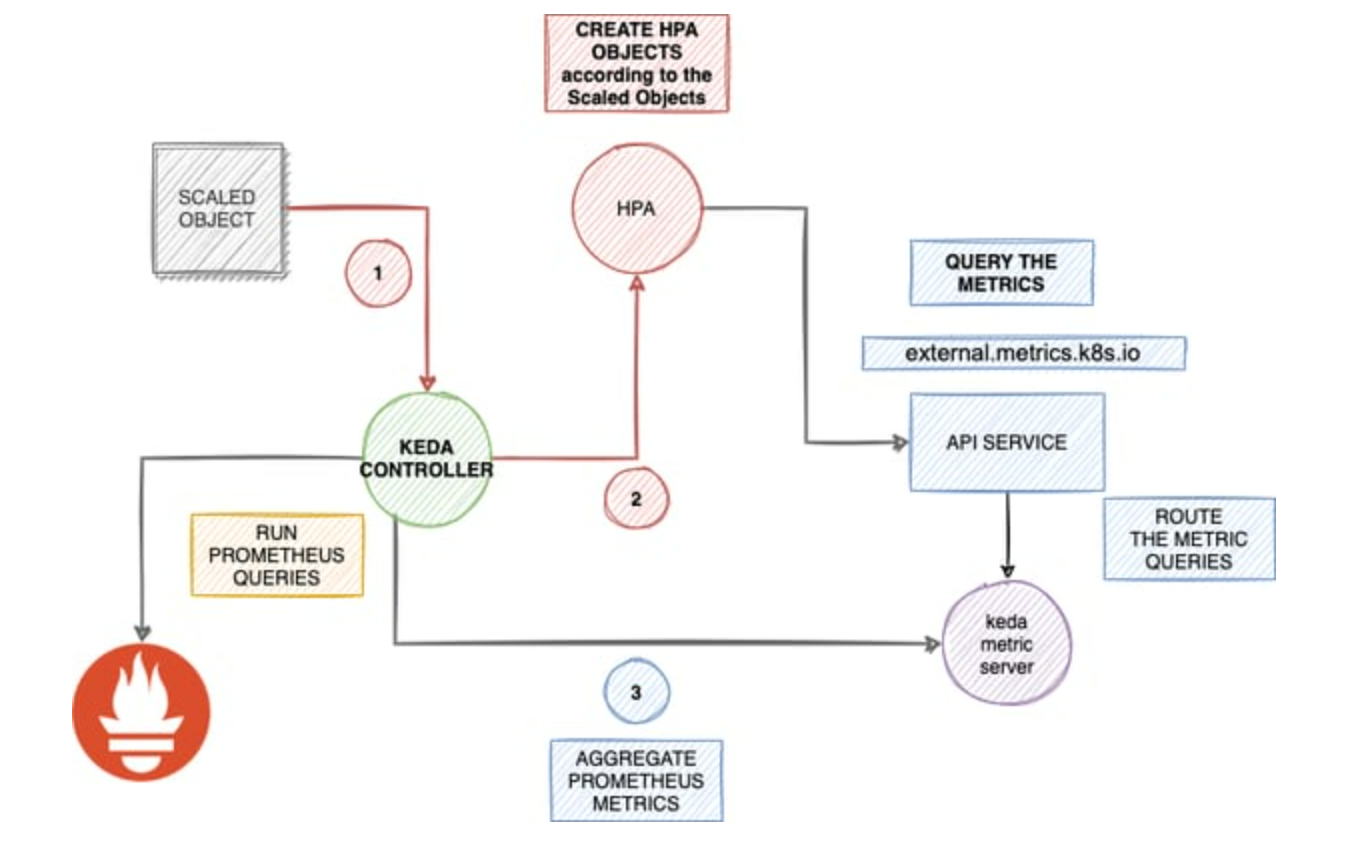
- Controller: 根据 Adapter 提供的指标进行操作,调谐到 ScaledObject 中指定的资源状态。Scaler 根据 ScaledObject 中设置的事件源持续监视事件,发生任何触发事件时将指标传递给 Metrics Adapter。Metrics Adapter 调整指标并提供给 Controller 组件,Controller 根据 ScaledObject 中设置的缩放规则扩大或缩小 Deployment。
总的来说,KEDA 设置一个 ScaledObject,定义一个事件触发器,可以是来自消息队列的消息、主题订阅的消息、存储队列的消息、事件网关的事件或自定义的触发器。基于这些事件来自动调整应用程序的副本数量或处理程序的资源配置,以根据实际负载情况实现弹性伸缩。
CRD
- ScaledObjects:代表事件源(如 Rabbit MQ)和 Kubernetes。 Deployment、StatefulSet 或任何定义 / 规模子资源的自定义资源之间的所需映射。
- ScaledJobs:事件源和 Kubernetes Jobs 之间的映射。根据事件触发调整 Job 规模。
- TriggerAuthentications:触发器的认证参数。
- ClusterTriggerAuthentications:集群维度认证。
部署 KEDA
helm repo add kedacore https://kedacore.github.io/chartshelm repo updatekubectl create namespace kedahelm install keda kedacore/keda --namespace kedakubectl apply -f https://github.com/kedacore/keda/releases/download/v2.10.1/keda-2.10.1.yamlroot@node-1:/# kubectl get all -n kedaNAME READY STATUS RESTARTS AGEpod/keda-metrics-apiserver-7d89dbcb54-v22nl 1/1 Running 0 44spod/keda-operator-5bb9b49d7c-kh6wt 0/1 Running 0 44sNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEservice/keda-metrics-apiserver ClusterIP 10.233.44.19 443/TCP,80/TCP 45sNAME READY UP-TO-DATE AVAILABLE AGEdeployment.apps/keda-metrics-apiserver 1/1 1 1 45sdeployment.apps/keda-operator 0/1 1 0 45sNAME DESIRED CURRENT READY AGEreplicaset.apps/keda-metrics-apiserver-7d89dbcb54 1 1 1 45sreplicaset.apps/keda-operator-5bb9b49d7c 1 1 0 45sroot@node-1:/# kubectl get all -n kedaNAME READY STATUS RESTARTS AGEpod/keda-metrics-apiserver-7d89dbcb54-v22nl 1/1 Running 0 4m8spod/keda-operator-5bb9b49d7c-kh6wt 1/1 Running 0 4m8sNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEservice/keda-metrics-apiserver ClusterIP 10.233.44.19 443/TCP,80/TCP 4m9sNAME READY UP-TO-DATE AVAILABLE AGEdeployment.apps/keda-metrics-apiserver 1/1 1 1 4m9sdeployment.apps/keda-operator 1/1 1 1 4m9sNAME DESIRED CURRENT READY AGEreplicaset.apps/keda-metrics-apiserver-7d89dbcb54 1 1 1 4m9sreplicaset.apps/keda-operator-5bb9b49d7c# kubectl get crd | grep kedaclustertriggerauthentications.keda.sh 2023-05-11T09:26:06Zscaledjobs.keda.sh 2023-05-11T09:26:07Zscaledobjects.keda.sh 2023-05-11T09:26:07Ztriggerauthentications.keda.sh 2023-05-11T09:26:07ZKubeSphere 部署 KEDA
kubectl edit cc -n kubesphere-system (kubesphere 3.4+)spec:··· autoscaling: enabled: true···扩展工作负载 CRD
ScaledObject 资源定义,详情参数请看 :https://keda.sh/docs/2.10/concepts/scaling-deployments/。
apiVersion: keda.sh/v1alpha1kind: ScaledObjectmetadata: name: {scaled-object-name}spec: scaleTargetRef: apiVersion: {api-version-of-target-resource} # Optional. Default: apps/v1 kind: {kind-of-target-resource} # Optional. Default: Deployment name: {name-of-target-resource} # Mandatory. Must be in the same namespace as the ScaledObject envSourceContainerName: {container-name} # Optional. Default: .spec.template.spec.containers[0] pollingInterval: 30 # Optional. Default: 30 seconds cooldownPeriod: 300 # Optional. Default: 300 seconds idleReplicaCount: 0 # Optional. Default: ignored, must be less than minReplicaCount minReplicaCount: 1 # Optional. Default: 0 maxReplicaCount: 100 # Optional. Default: 100 fallback: # Optional. Section to specify fallback options failureThreshold: 3 # Mandatory if fallback section is included replicas: 6 # Mandatory if fallback section is included advanced: # Optional. Section to specify advanced options restoreToOriginalReplicaCount: true/false # Optional. Default: false horizontalPodAutoscalerConfig: # Optional. Section to specify HPA related options name: {name-of-hpa-resource} # Optional. Default: keda-hpa-{scaled-object-name} behavior: # Optional. Use to modify HPA's scaling behavior scaleDown: stabilizationWindowSeconds: 300 policies: - type: Percent value: 100 periodSeconds: 15 triggers: # {list of triggers to activate scaling of the target resource}查看 KEDA Mterics Server 暴露的指标
kubectl get –raw “/apis/external.metrics.k8s.io/v1beta1”
Demo
KEDA 目前支持 53 种 Scalers,如 Kafka,Elasticsearch,MySQL,RabbitMQ,Prometheus 等等。
此处演示一个 Prometheus 和 Kafka 的例子。
Prometheus & KEDA
部署一个 Web 应用,使用 Prometheus 监控 Web 应用 http 请求指标。
为寻求演示效果,此处部署了一个有点击,互动的 Demo APP,地址如下:https://github.com/livewyer-ops/keda-demo/blob/v1.0.0/examples/keda/。
部署成功后通过 NodePort 访问:
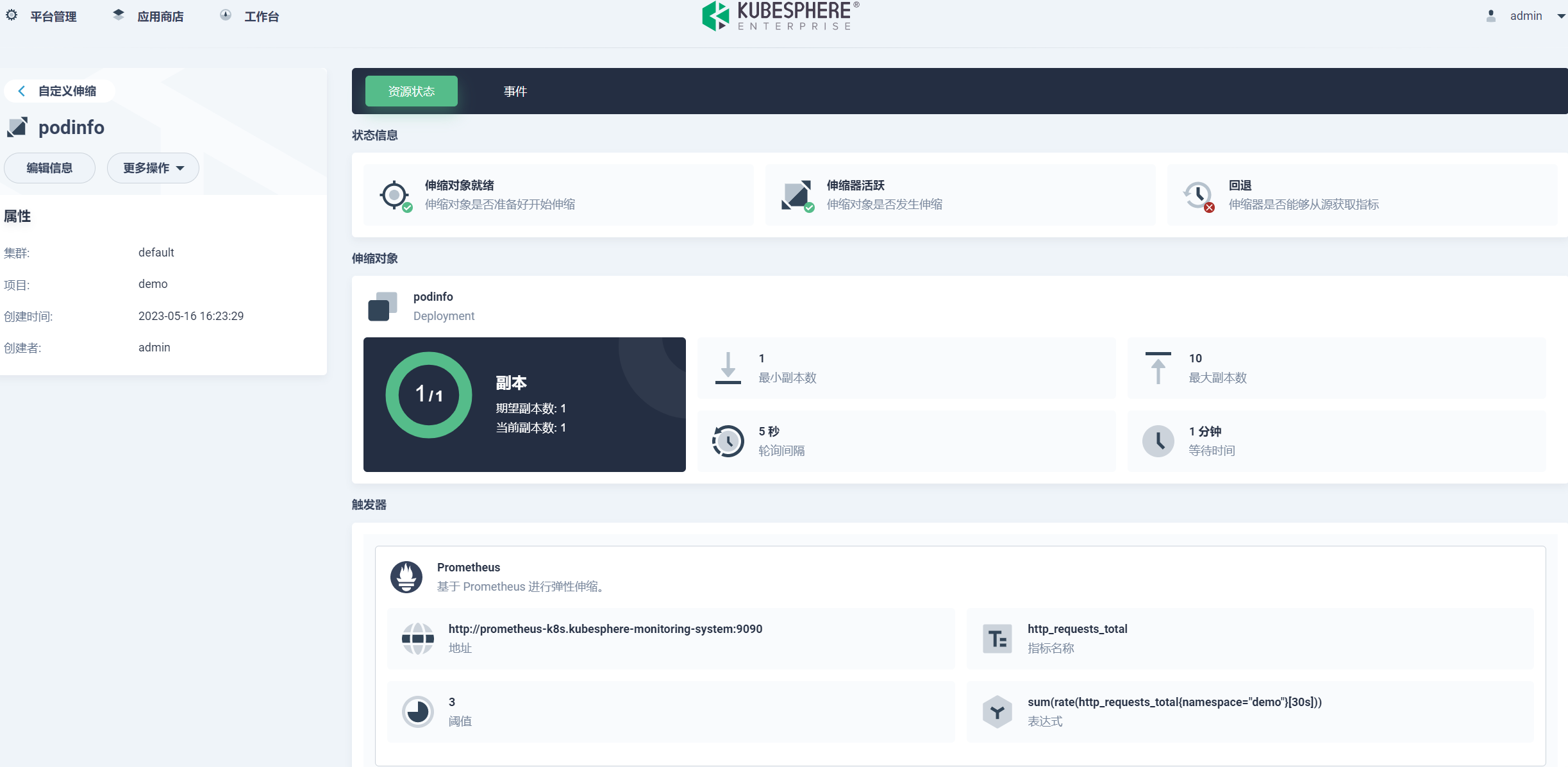
进入 KubeSphere 项目,新建一个自定义伸缩:
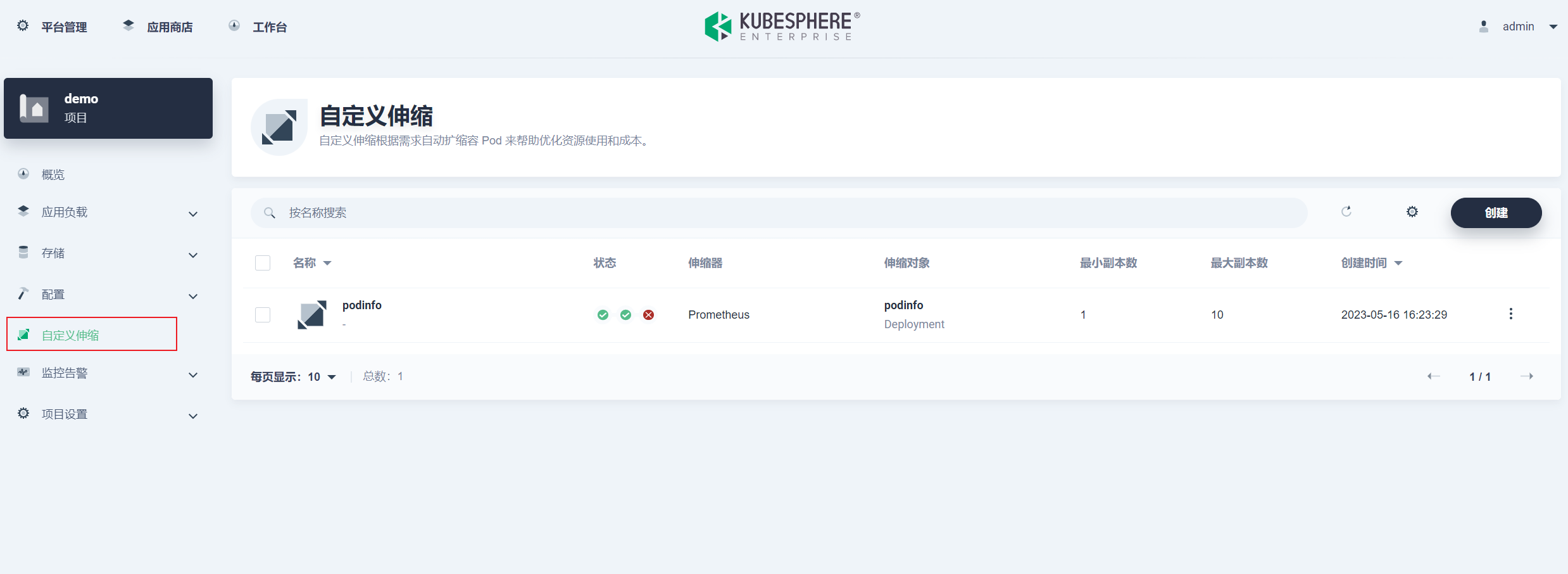
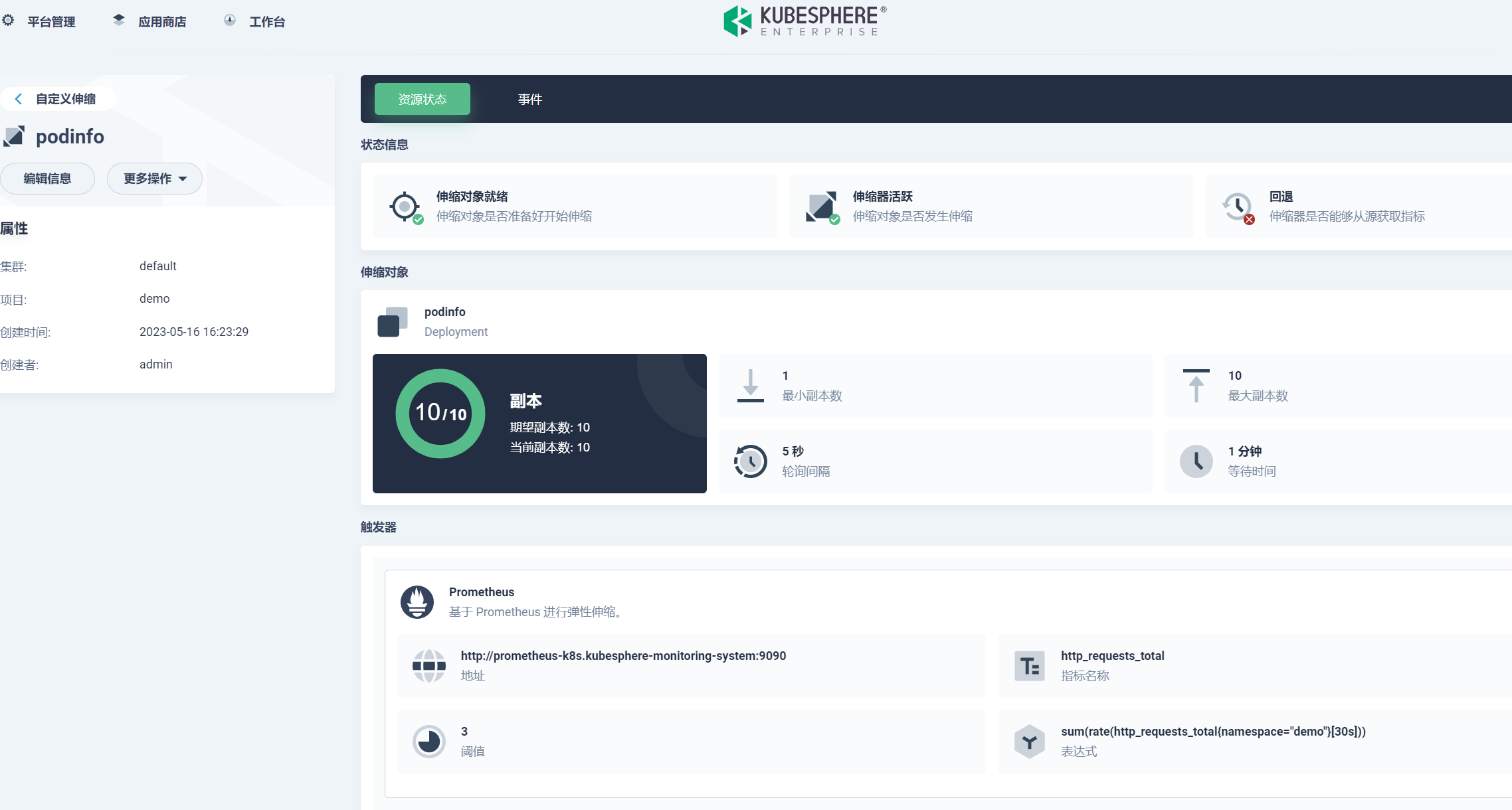
设置最小副本数为 1,最大副本数为 10,轮询间隔 5 秒,等待时间为 1 分钟:
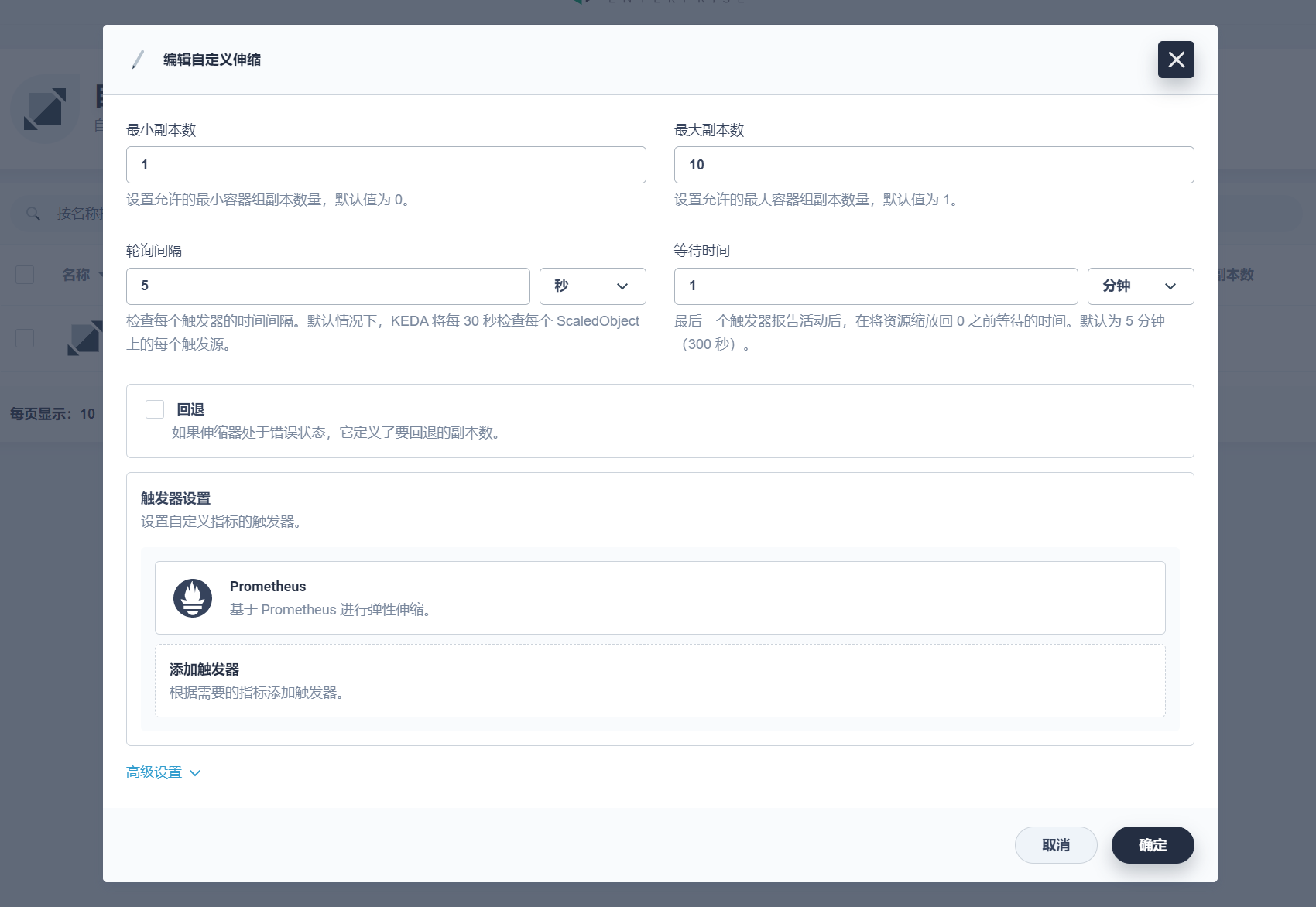
KubeSphere 支持 Cron、Prometheus,和自定义触发器:
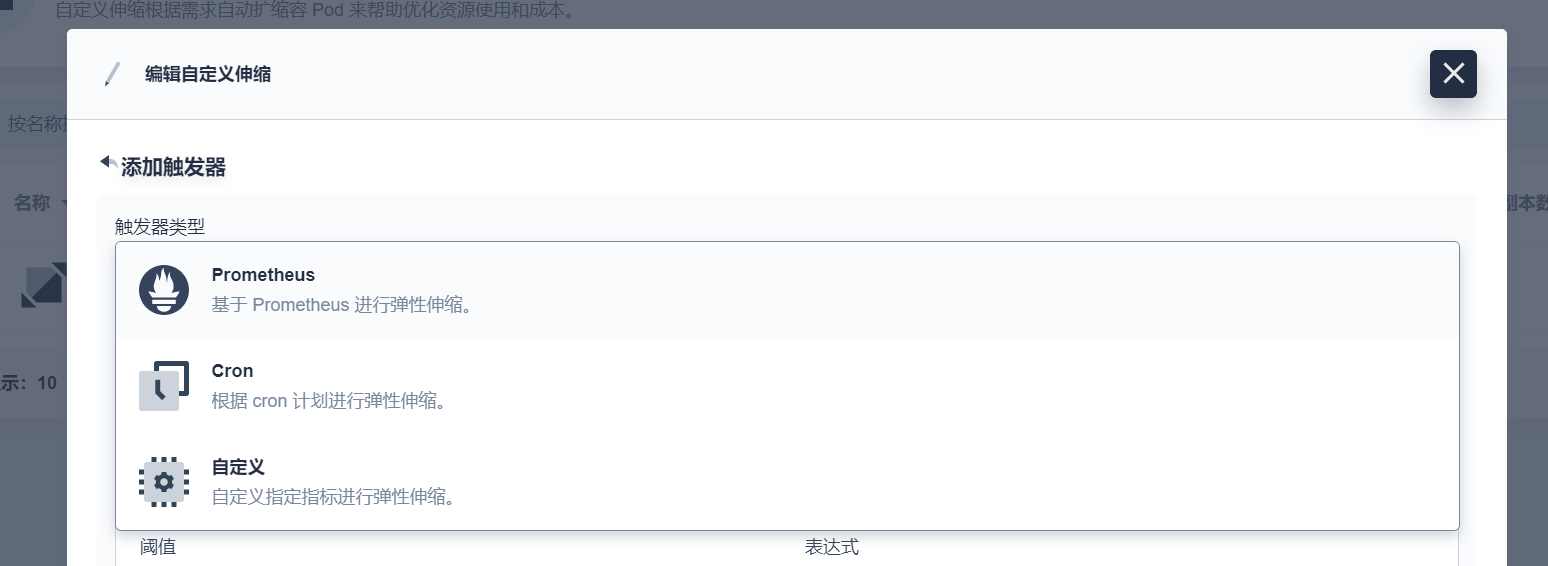
触发器设置 Prometheus,设置请求为 30s 内的增长率总和,当阈值大于 3 时事件驱动触发缩放:
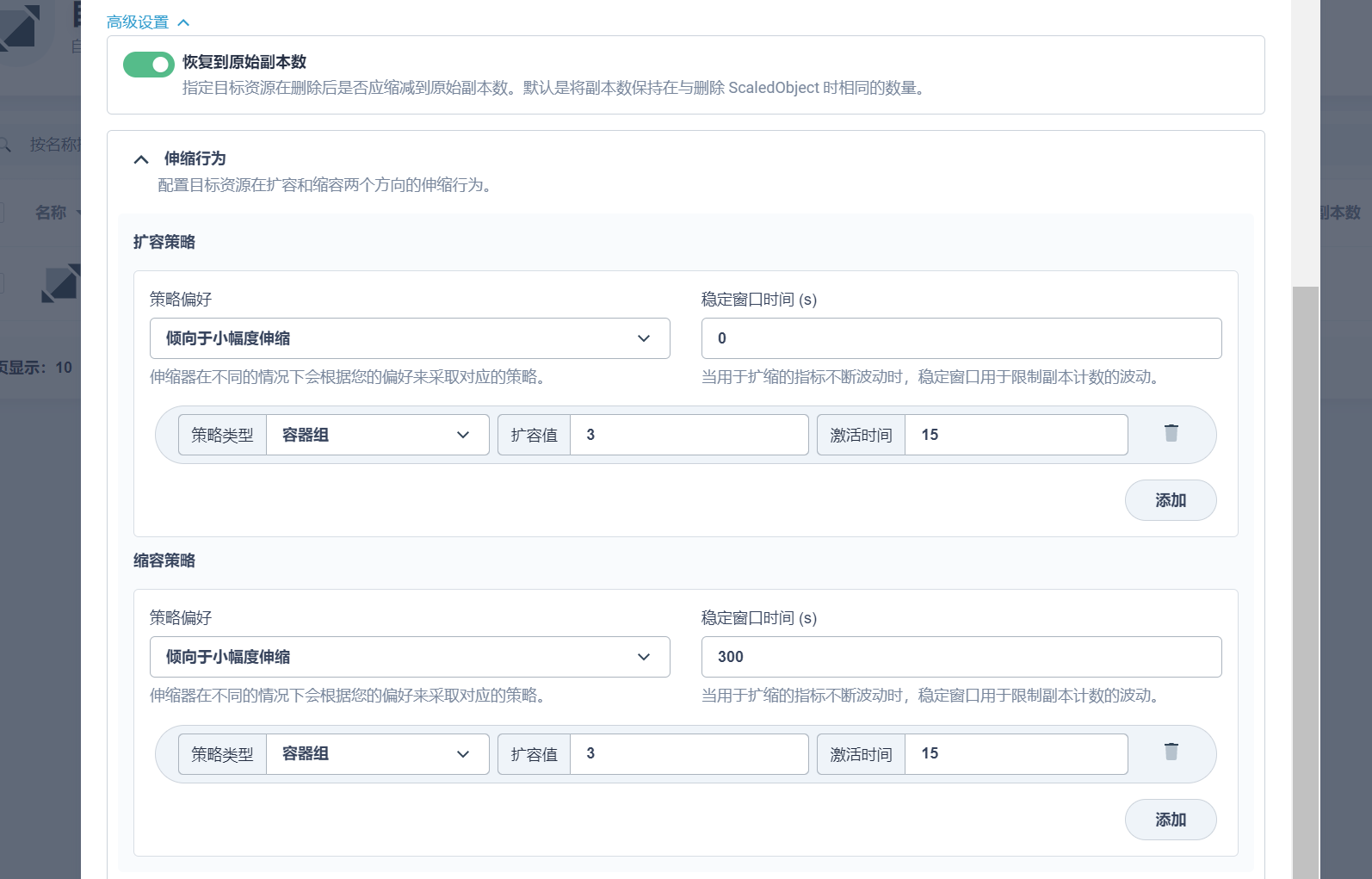
设置一些其他设置,如资源删除后是否恢复指本来的副本数,以及扩缩策略设置:
现在并发访问 Web App:

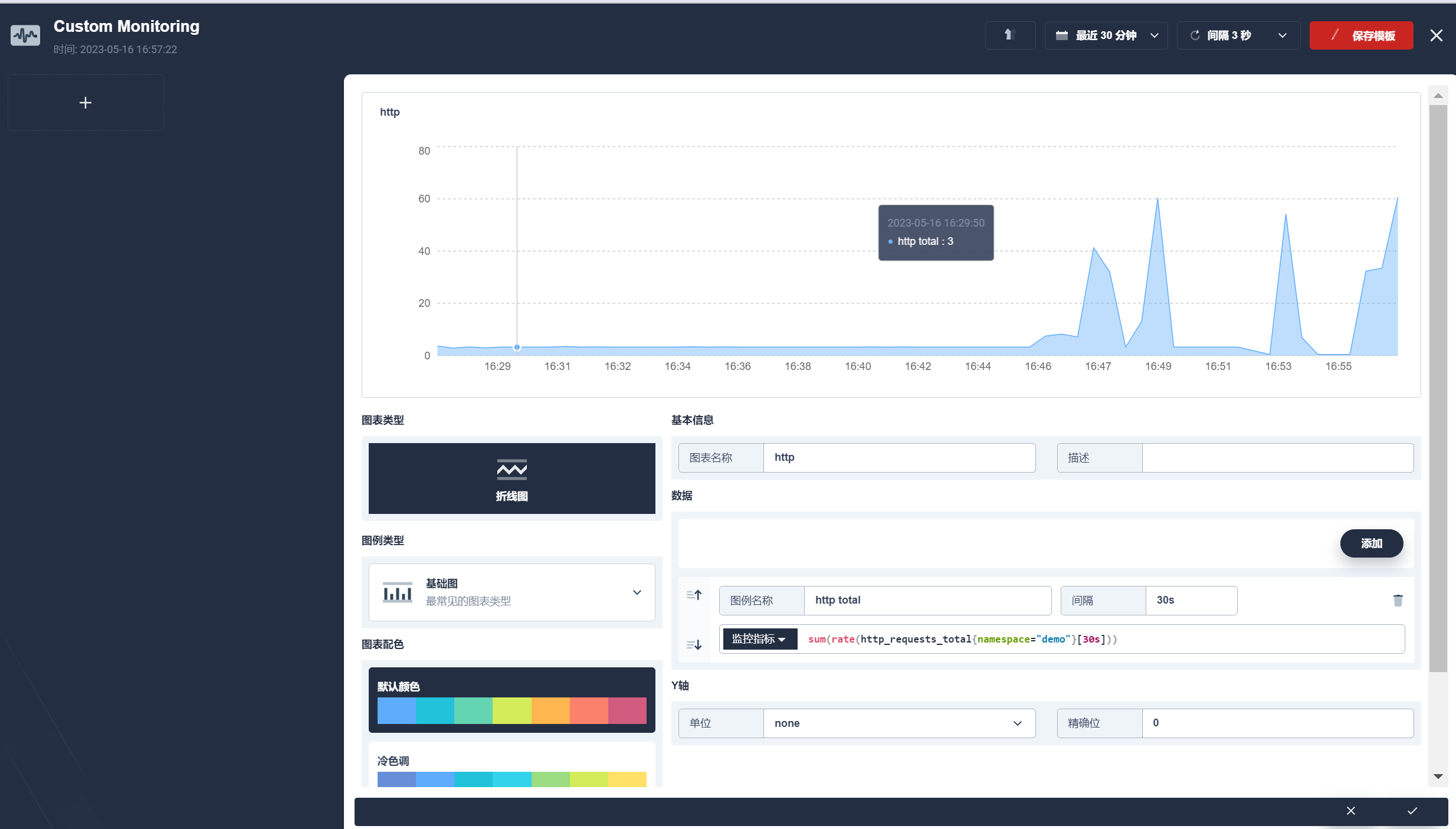
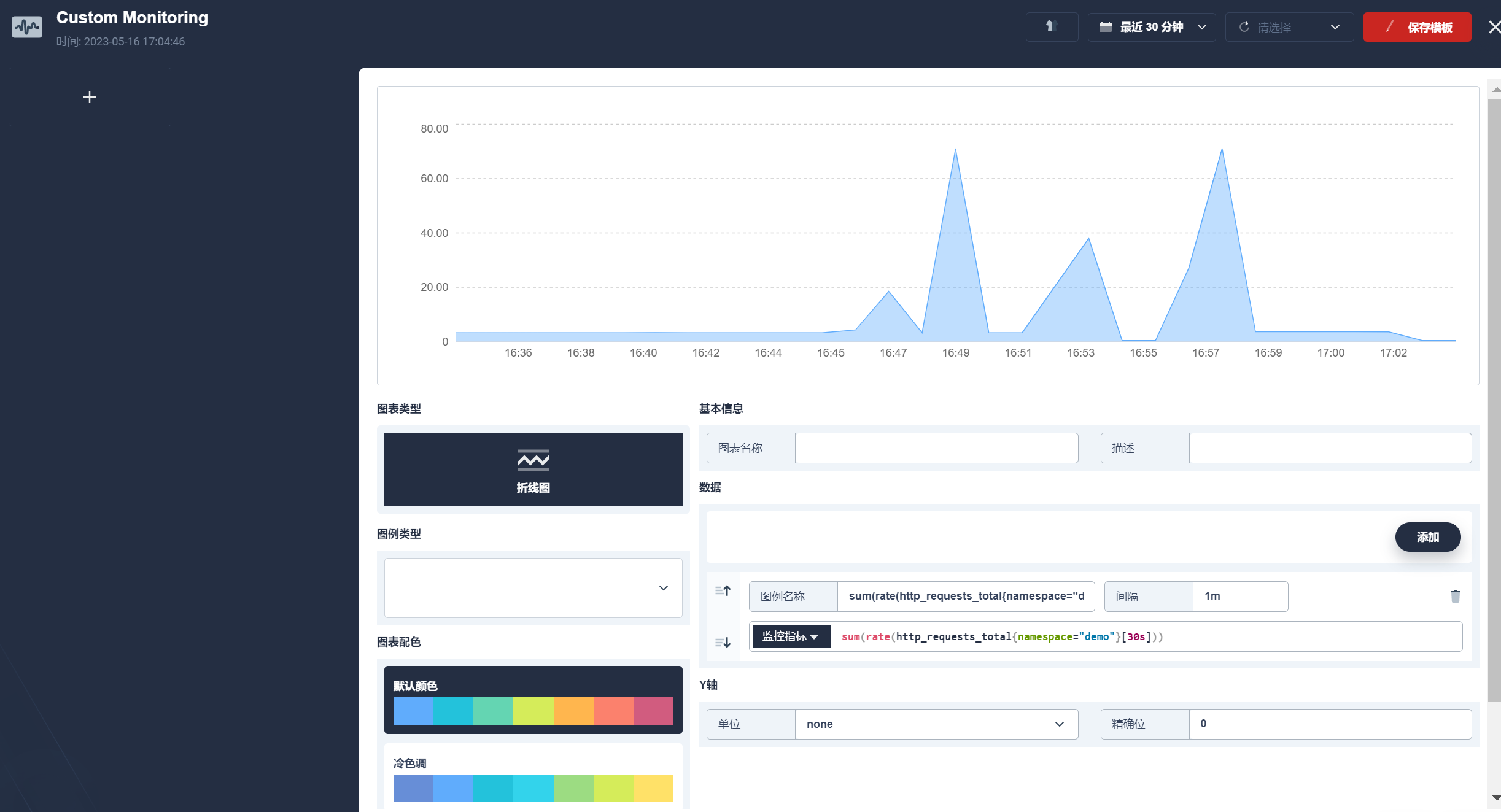
可以在自定义监控看到监控指标的变化:
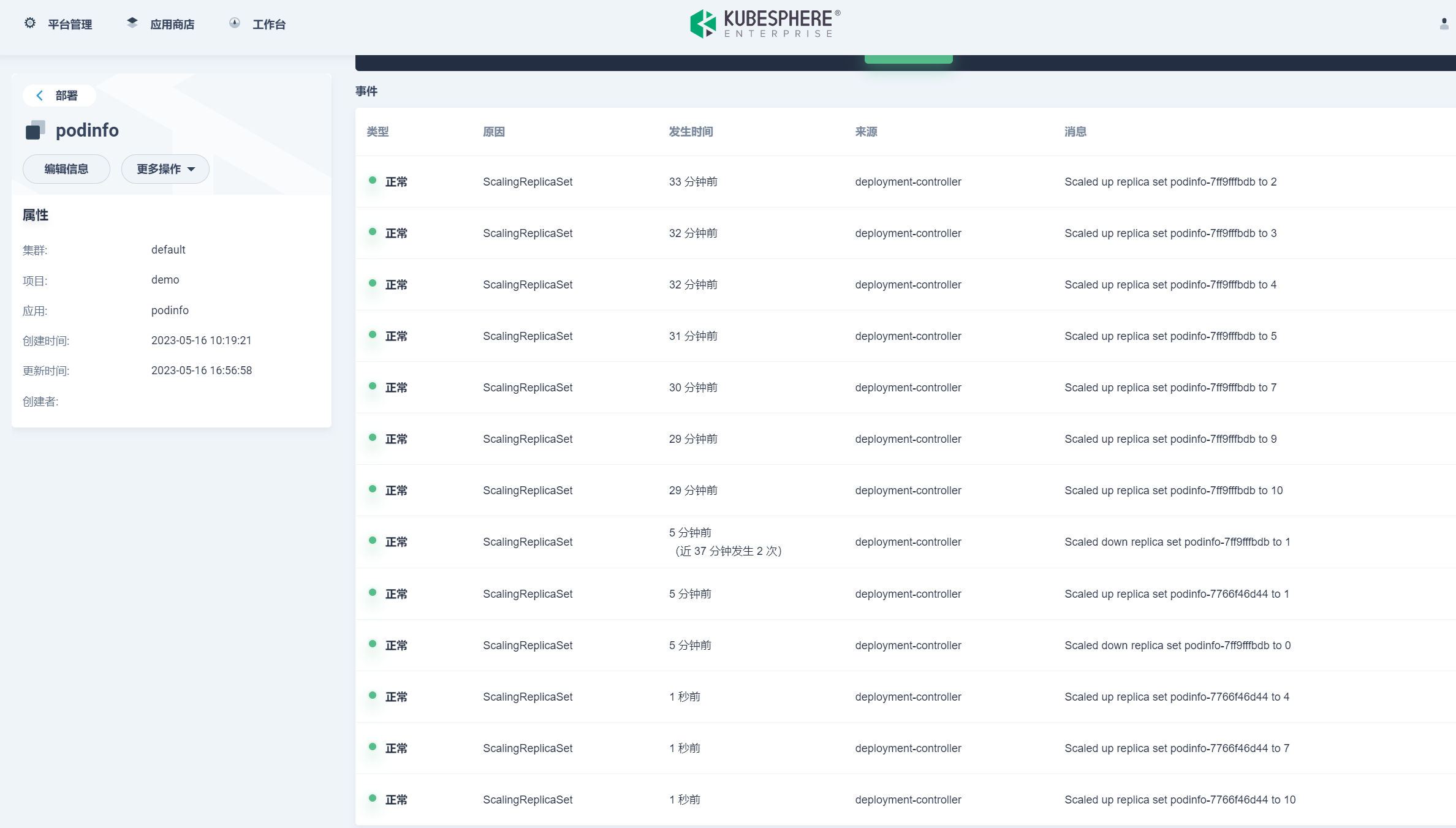
Web App 的副本数开始横向扩展:
最终扩展到 ScaledObject 中定义的 10 个副本:
在访问停止后,可以看到监控指标的数值在慢慢变小:
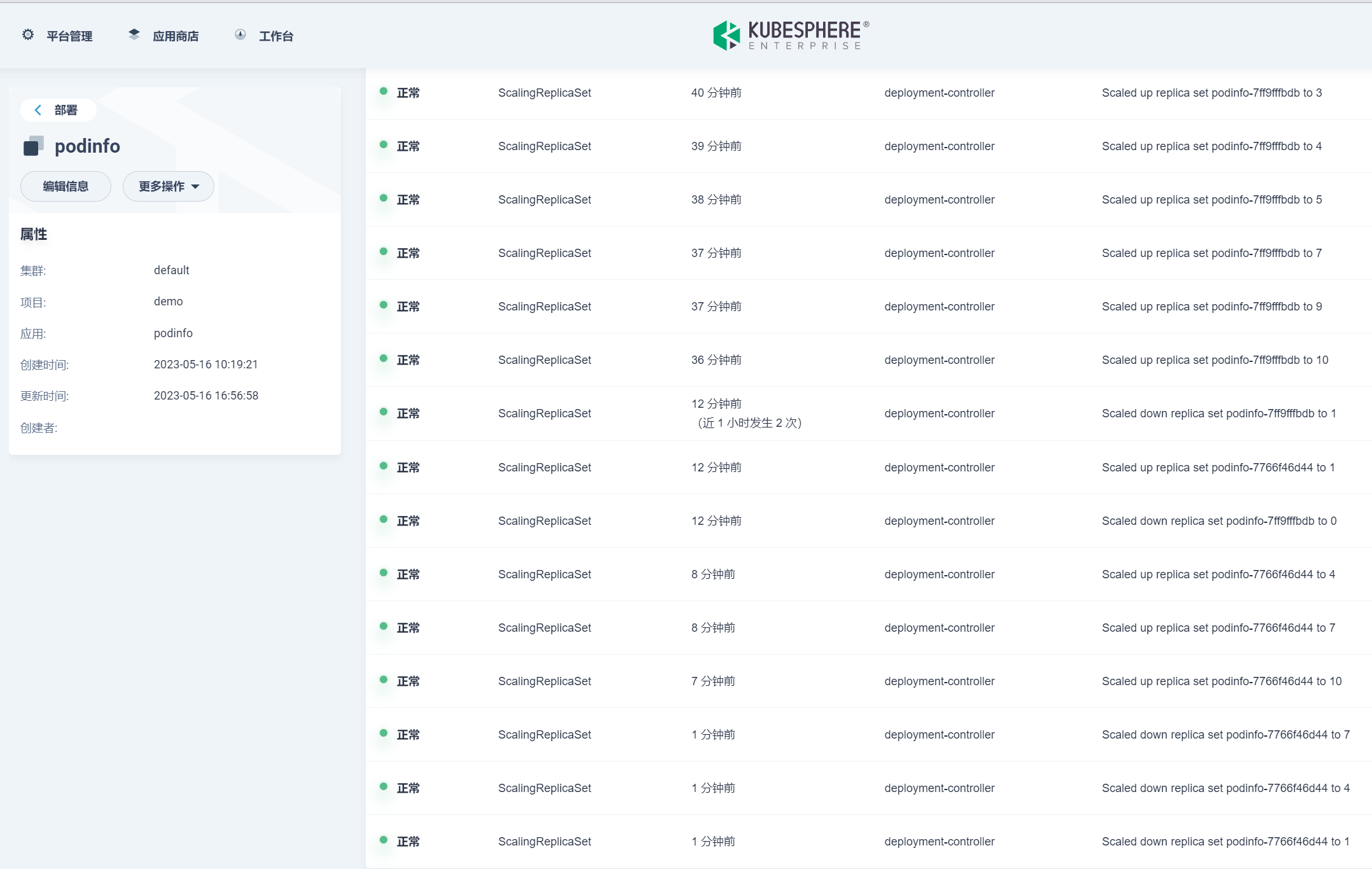
Deployment 开始缩容:
Kafka & KEDA
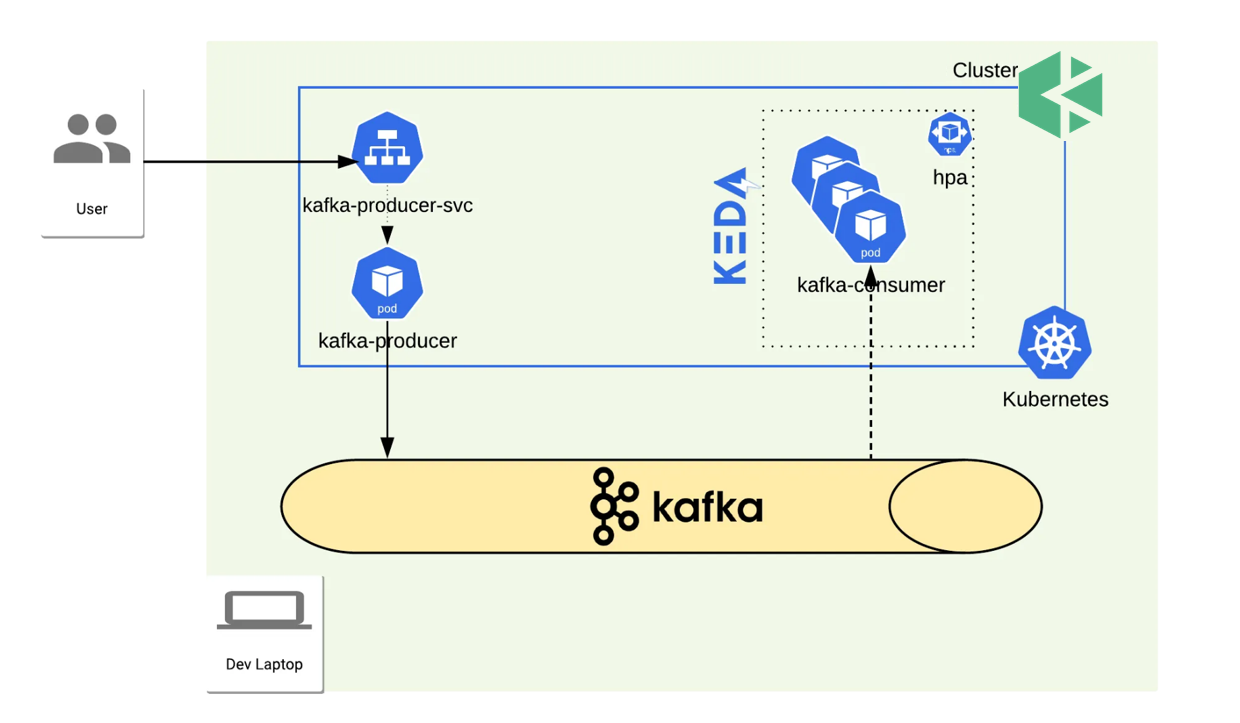
KEDA 使用 Kafka 事件源演示的整体拓扑如下:
Kafka 使用 Demo 代码:https://github.com/ChamilaLiyanage/kafka-keda-example.git。
部署 Kafka
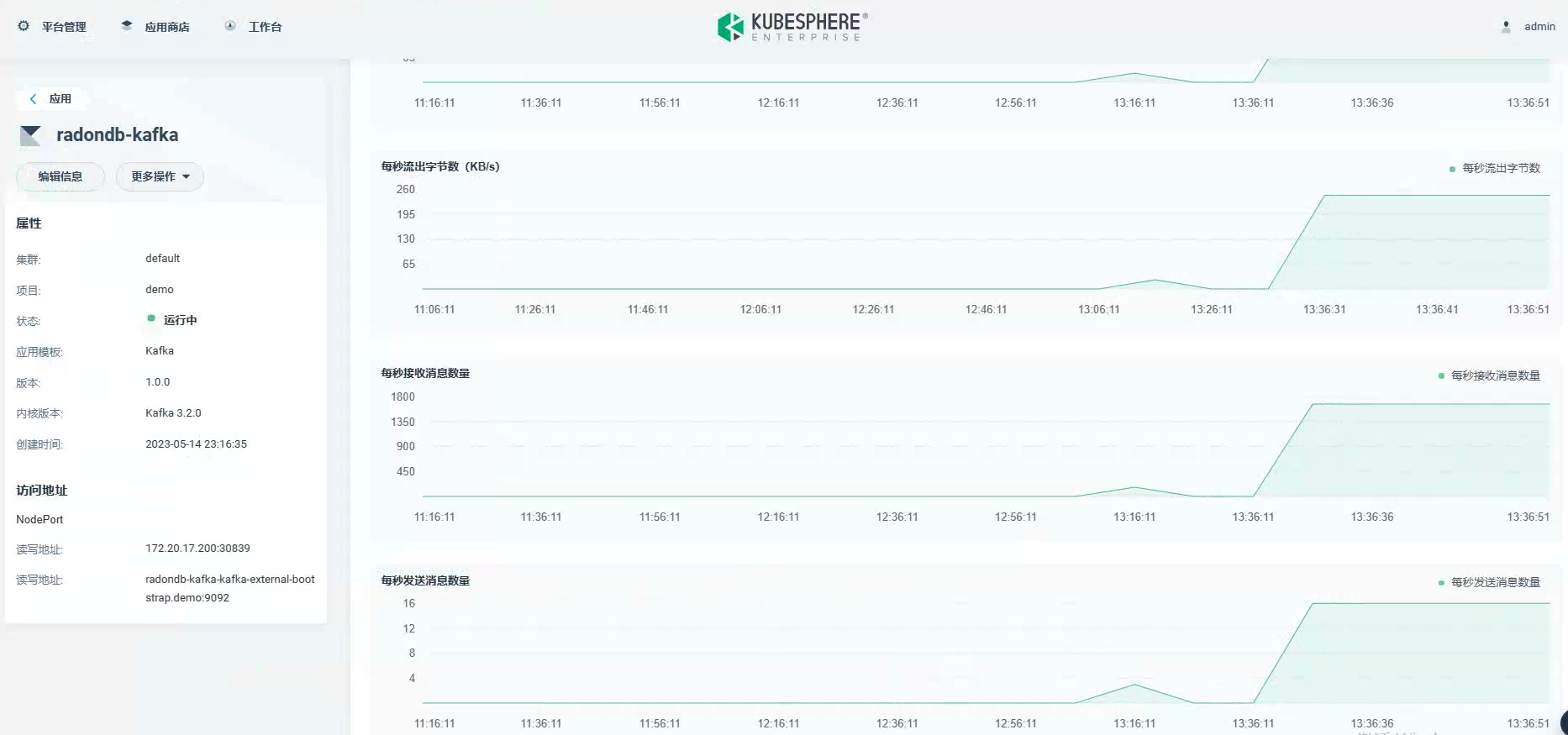
打开 KubeSphere 应用商店,查看 DMP 数据库中心:
选择 Kafka,进行安装:
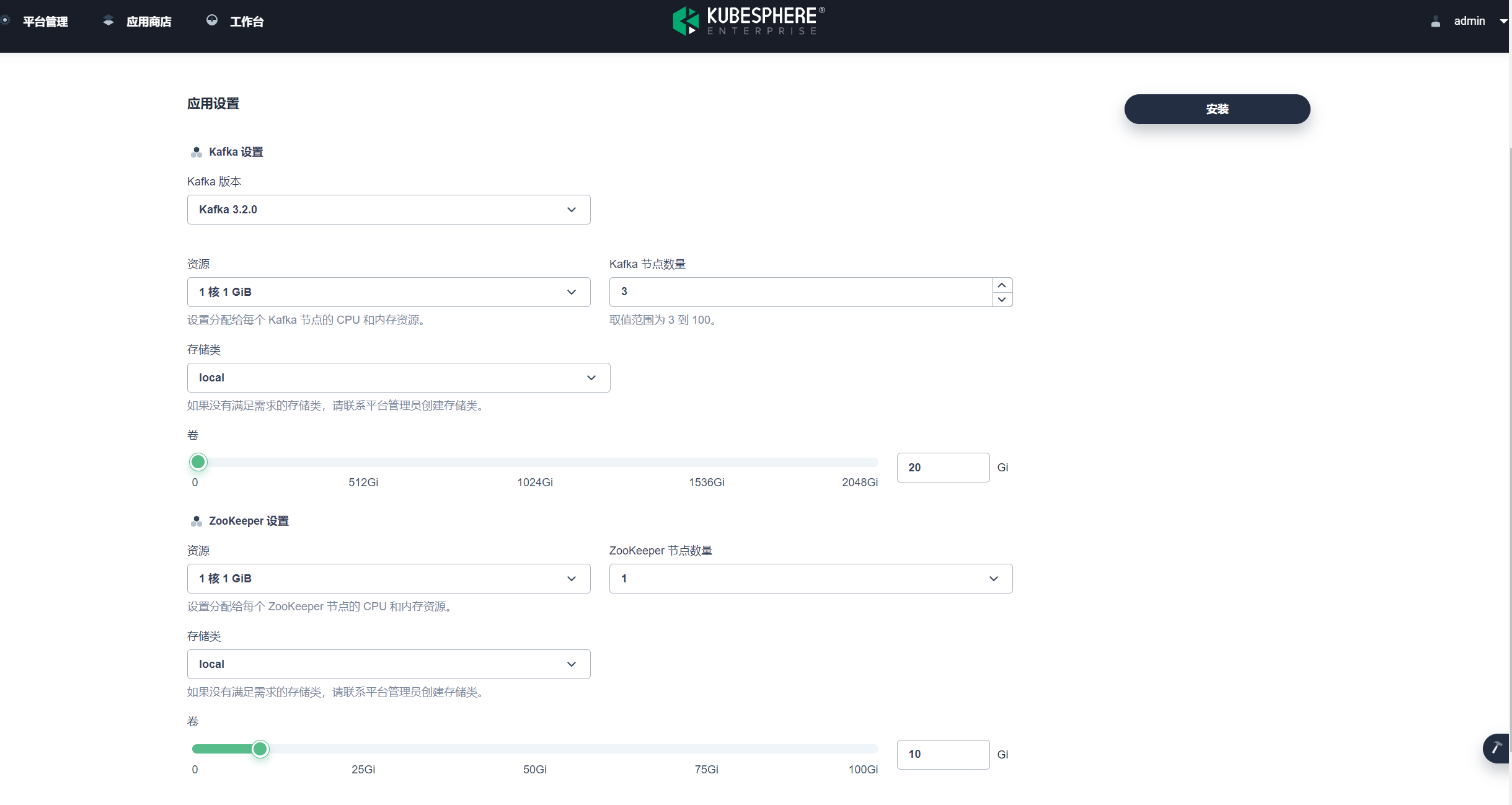
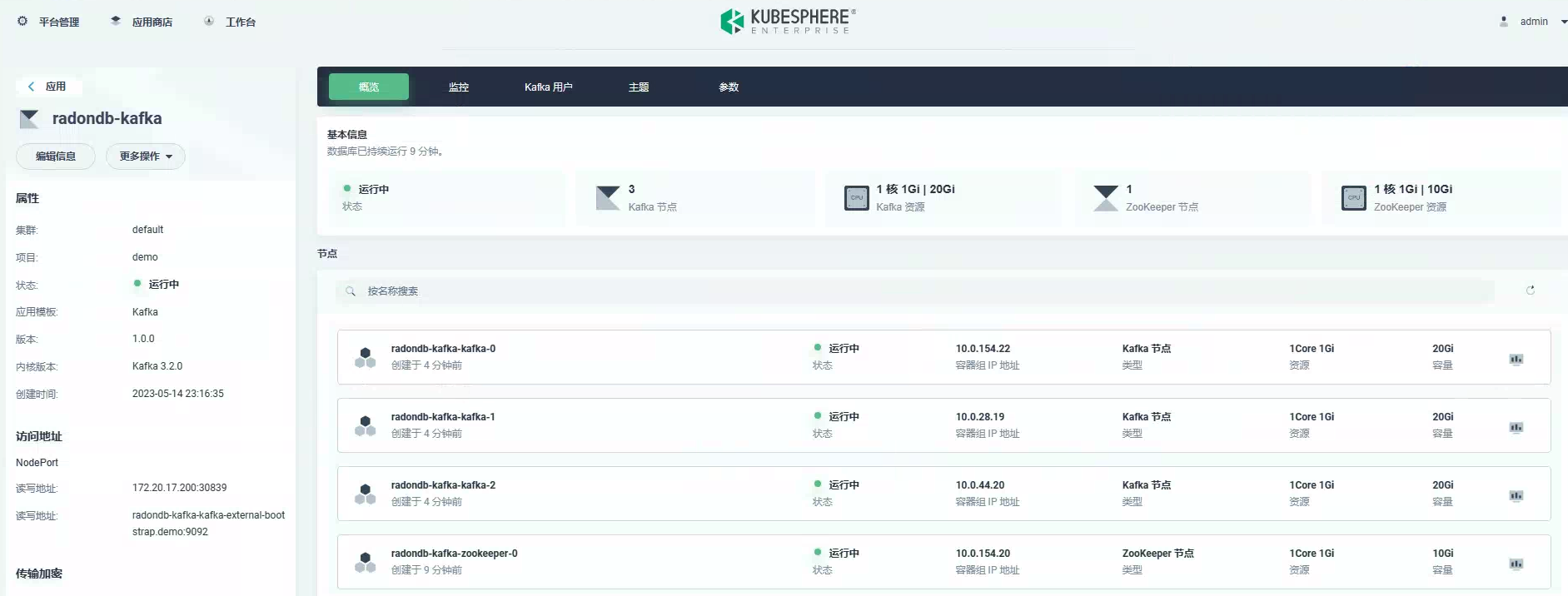
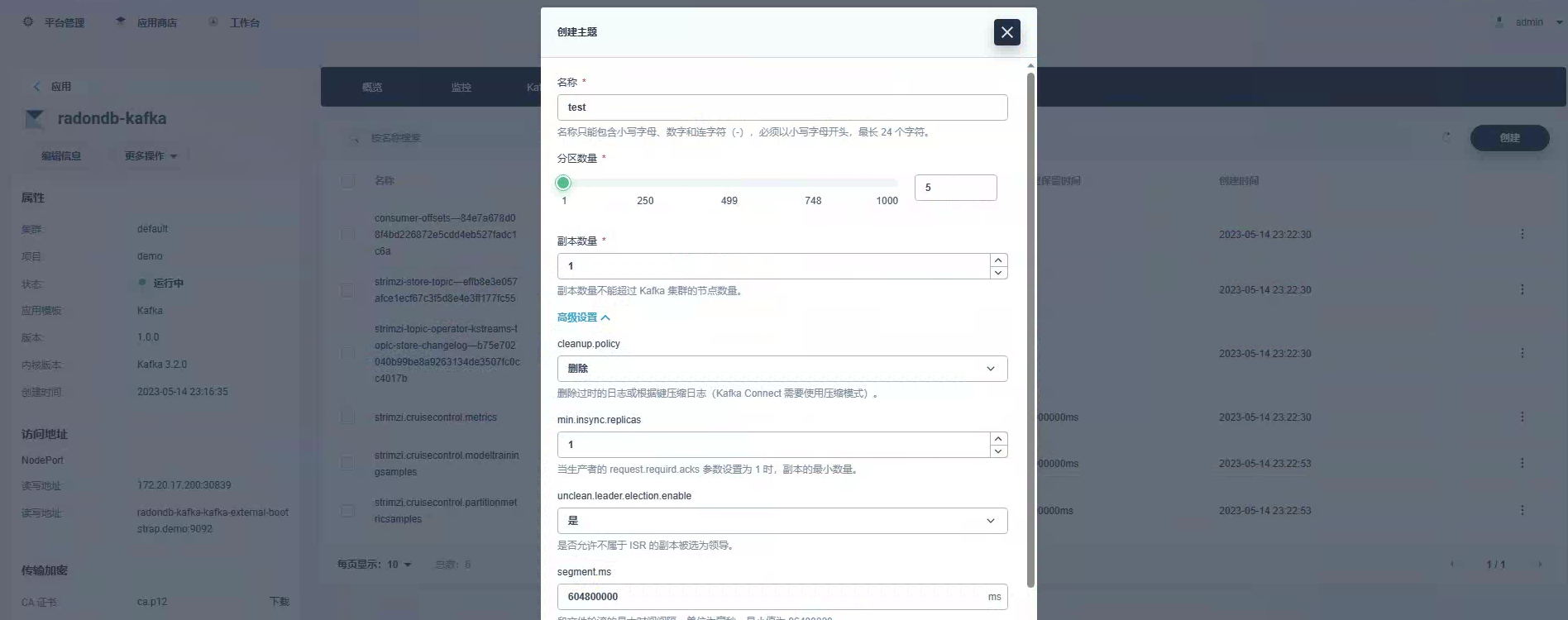
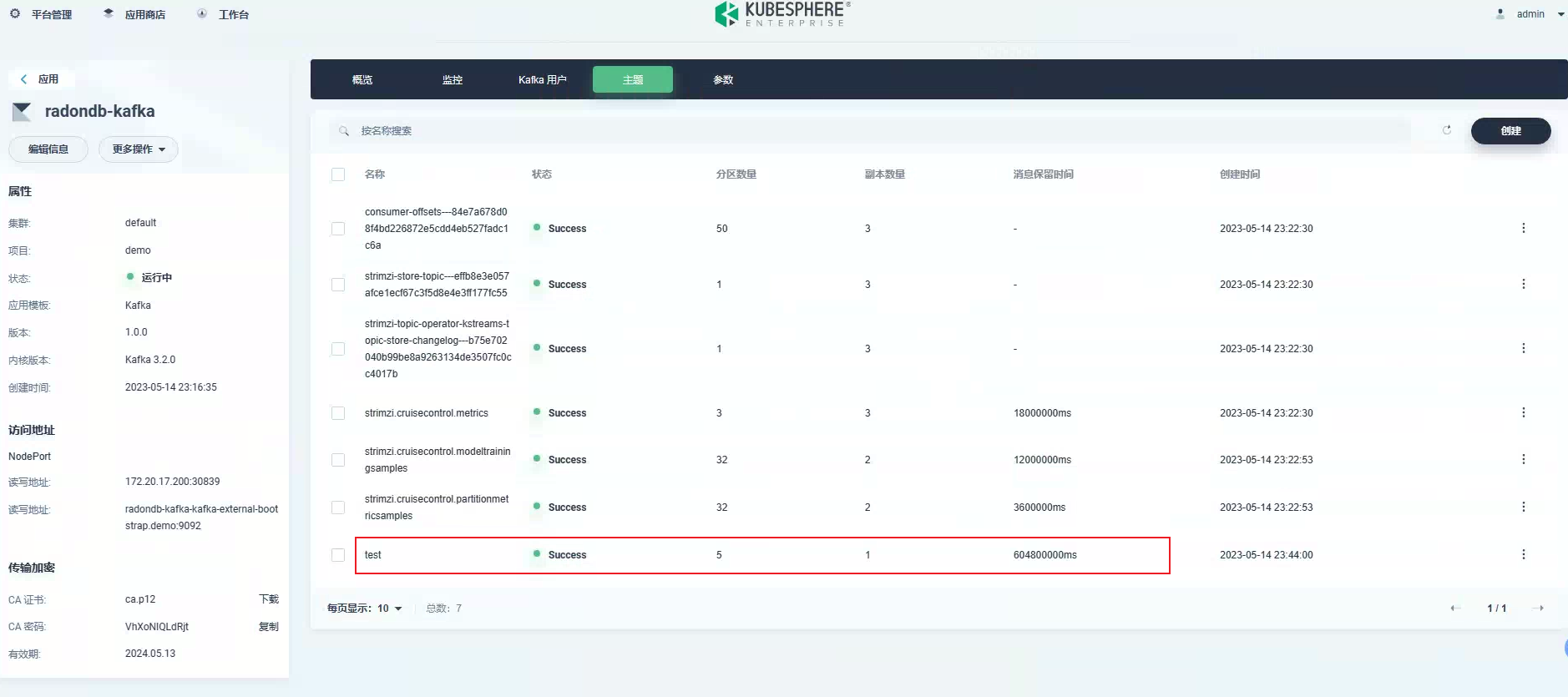
安装好 Kafka 后,创建一个测试的 Kafka Topic,Topic 分区设置为 5,副本设置为 1:
创建 Kafka Producer 服务:

向主题发送订单:
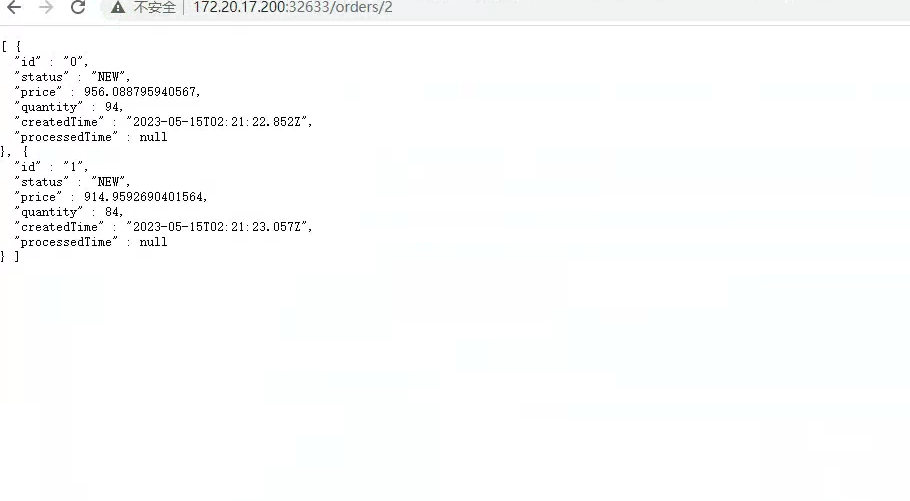

创建 Consumer 服务:
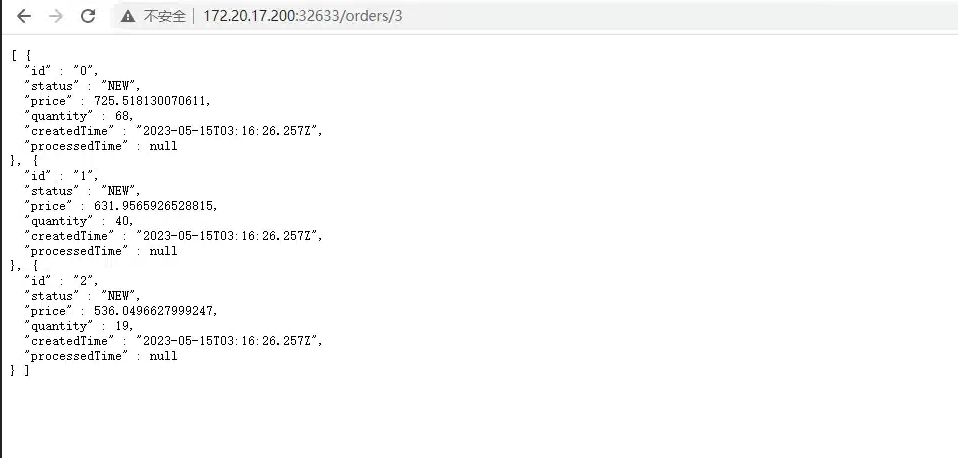
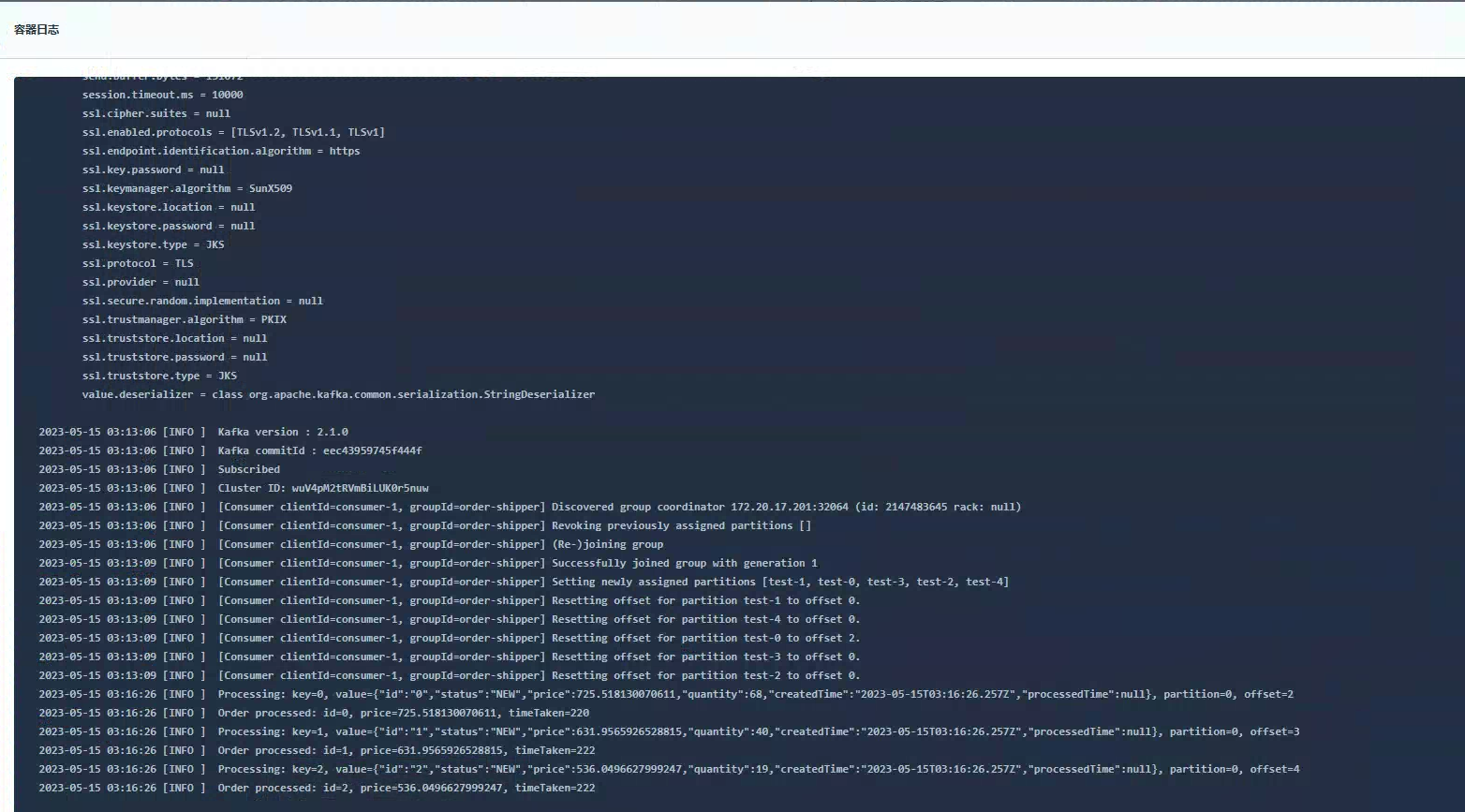
发送新订单看 Consumer 服务是否消费:
现在可以来做自动伸缩了,创建一个 ScaledObject,设置最小副本数为 0,最大为 10,轮询间隔为 5s,Kafka LagThreshold 为 10:
apiVersion: keda.k8s.io/v1alpha1kind: ScaledObjectmetadata: name: kafka-scaledobject namespace: default labels: deploymentName: kafka-consumer-deployment # Required Name of the deployment we want to scale.spec: scaleTargetRef: deploymentName: kafka-consumer-deployment # Required Name of the deployment we want to scale. pollingInterval: 5 minReplicaCount: 0 #Optional Default 0 maxReplicaCount: 10 #Optional Default 100 triggers: - type: kafka metadata: # Required BootstrapeServers: radondb-kafka-kafka-external-bootstrap.demo:9092 # Kafka bootstrap server host and port consumerGroup: order-shipper # Make sure that this consumer group name is the same one as the one that is consuming topics topic: test lagThreshold: "10" # Optional. How much the stream is lagging on the current consumer group创建自定义伸缩:
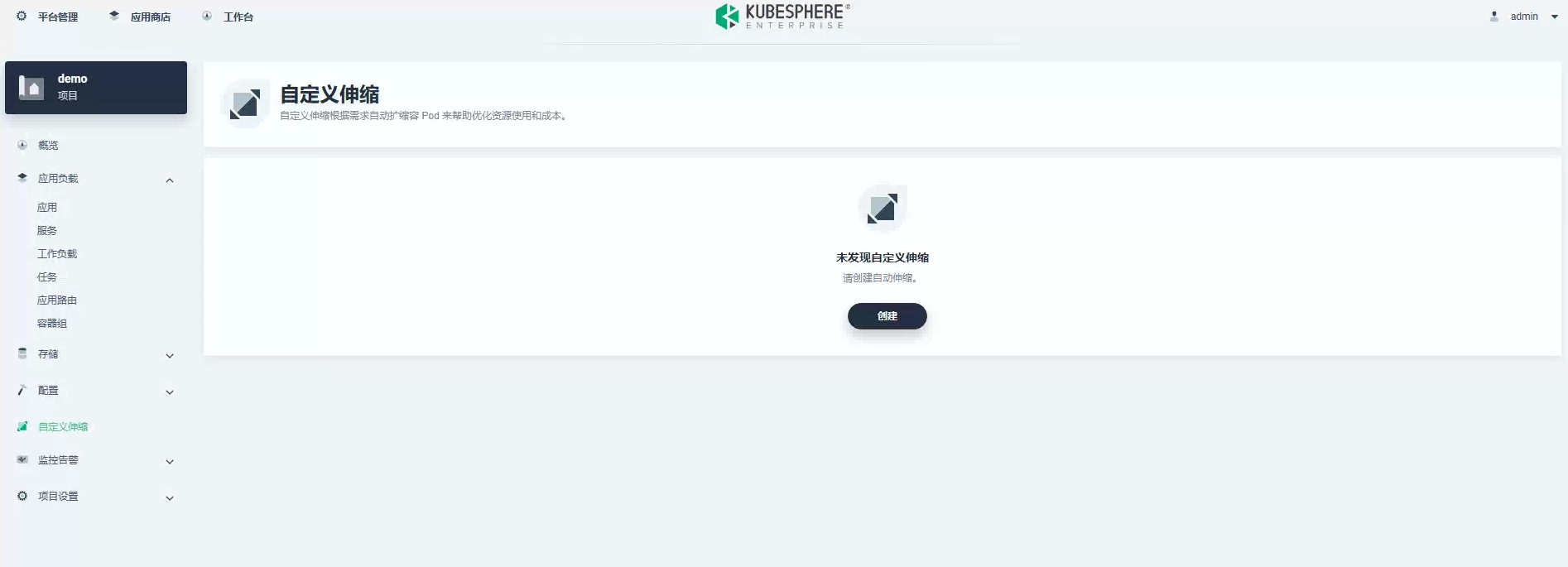
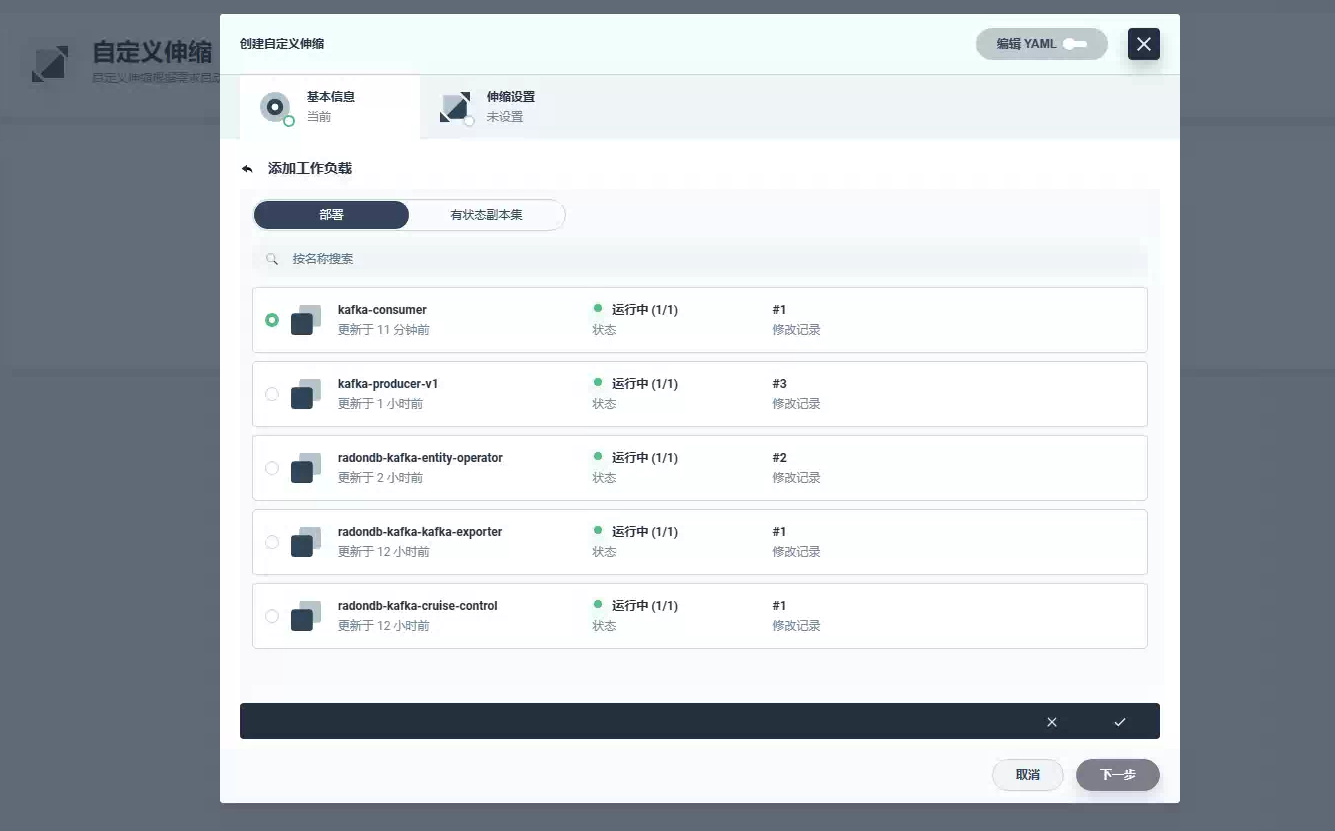
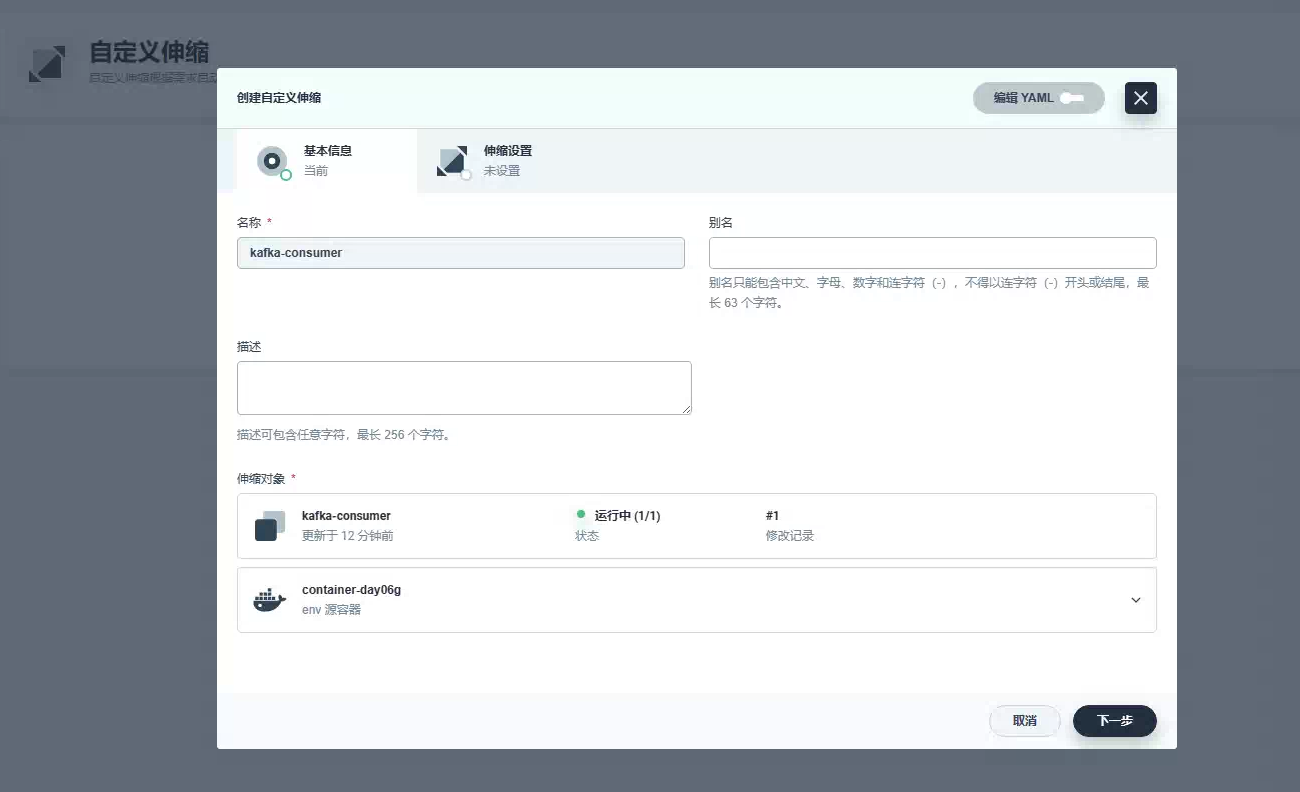

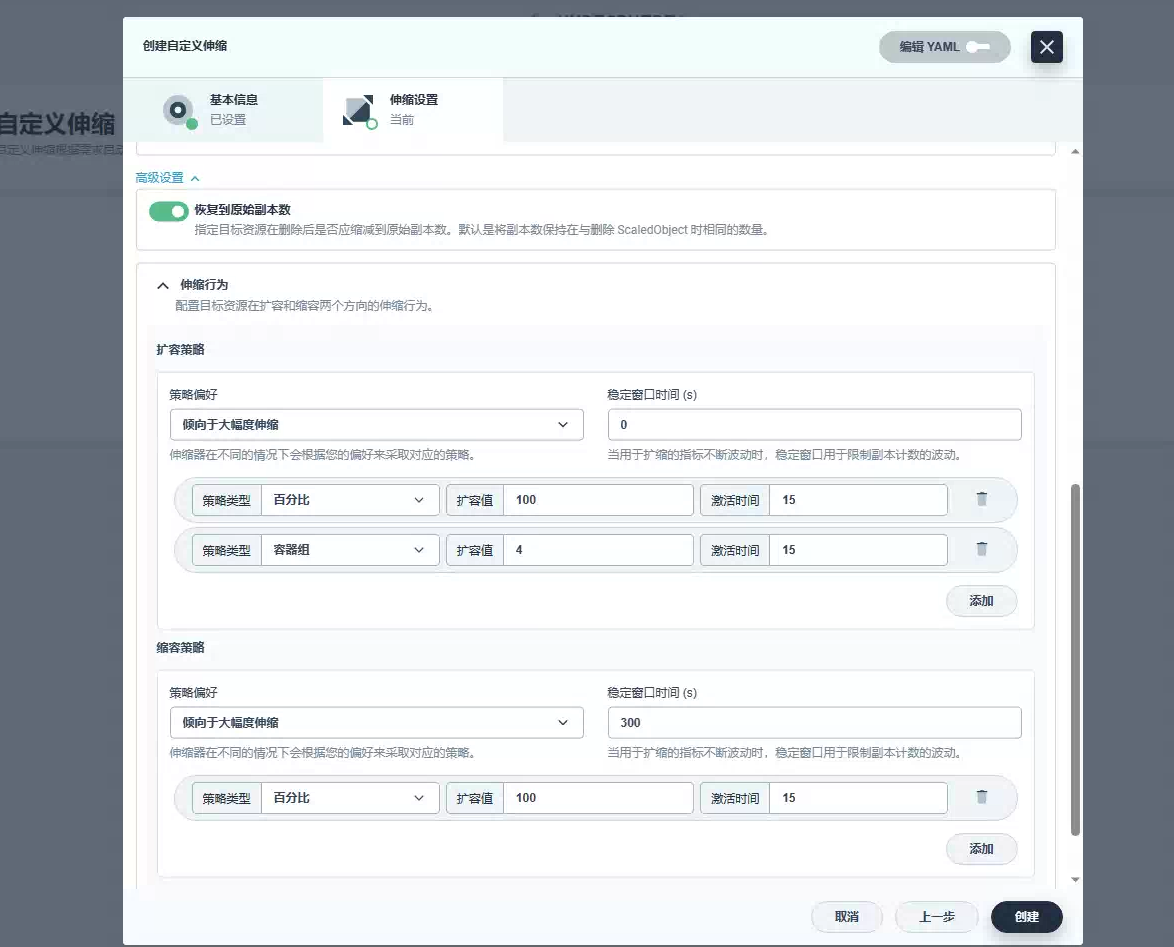
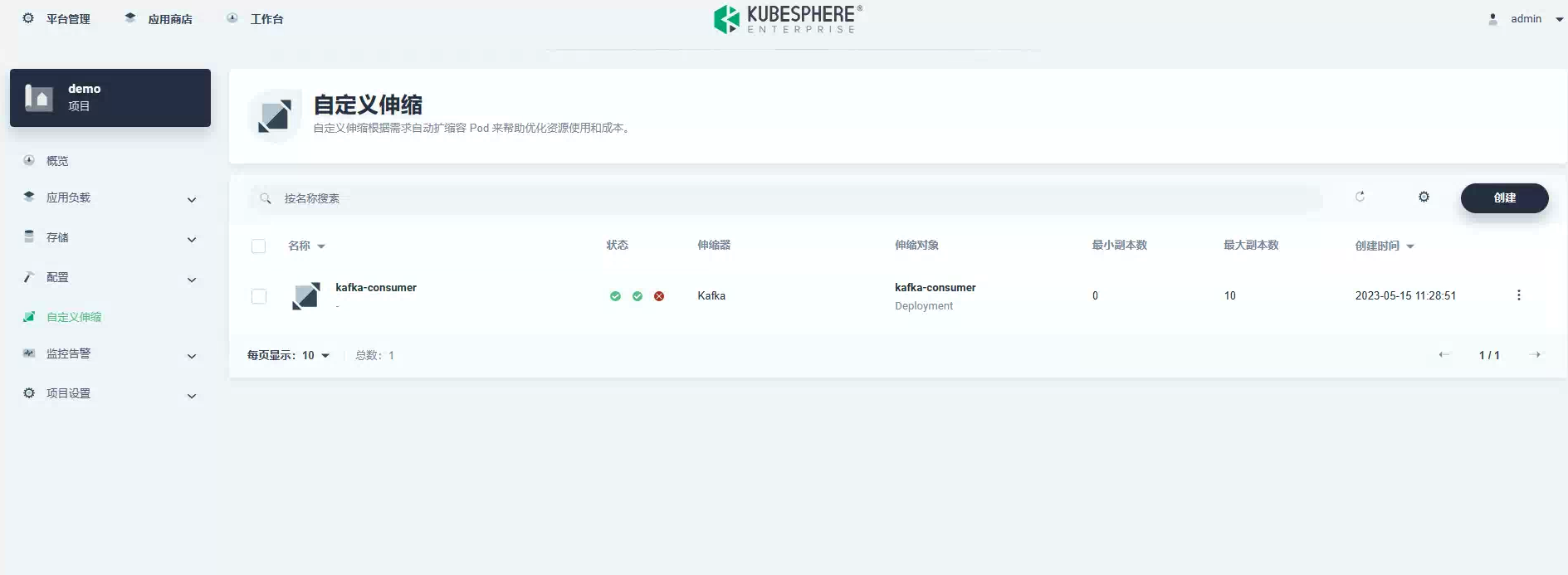
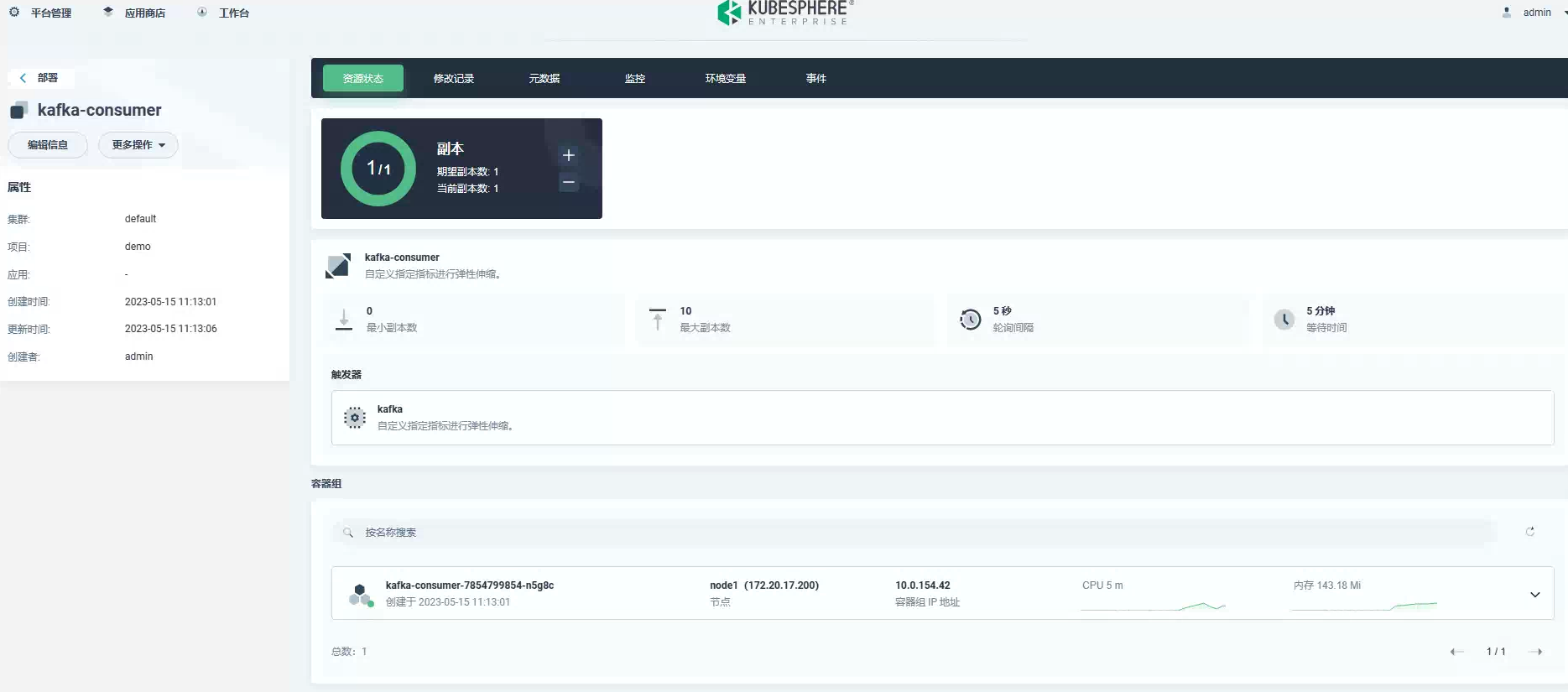
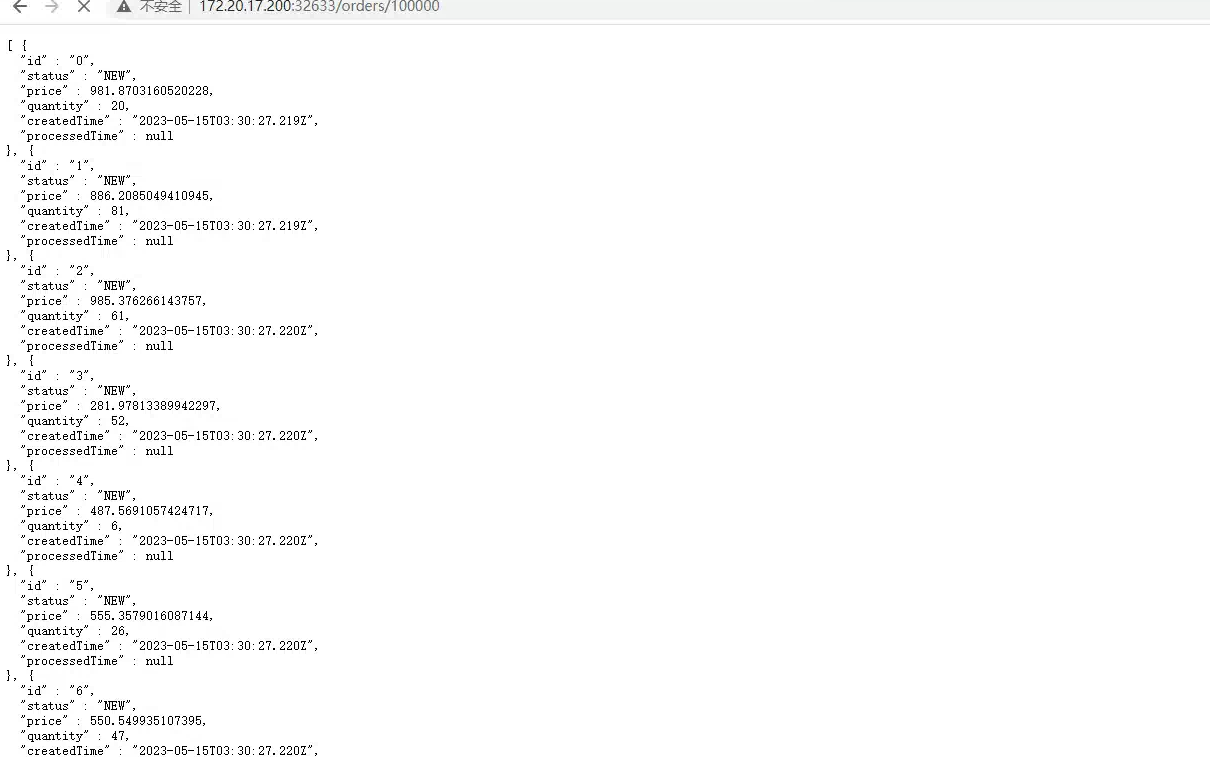
现在,让我们向队列提交大约 100,000 条订单消息,看看自动缩放的实际效果。你会看到随着队列中多余消息的增长,将会产生更多的 kafka-consumer pod。
NAMESPACE NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGEdemo keda-hpa-kafka-consumer Deployment/kafka-consumer 5/10 (avg) 1 10 1 2m35s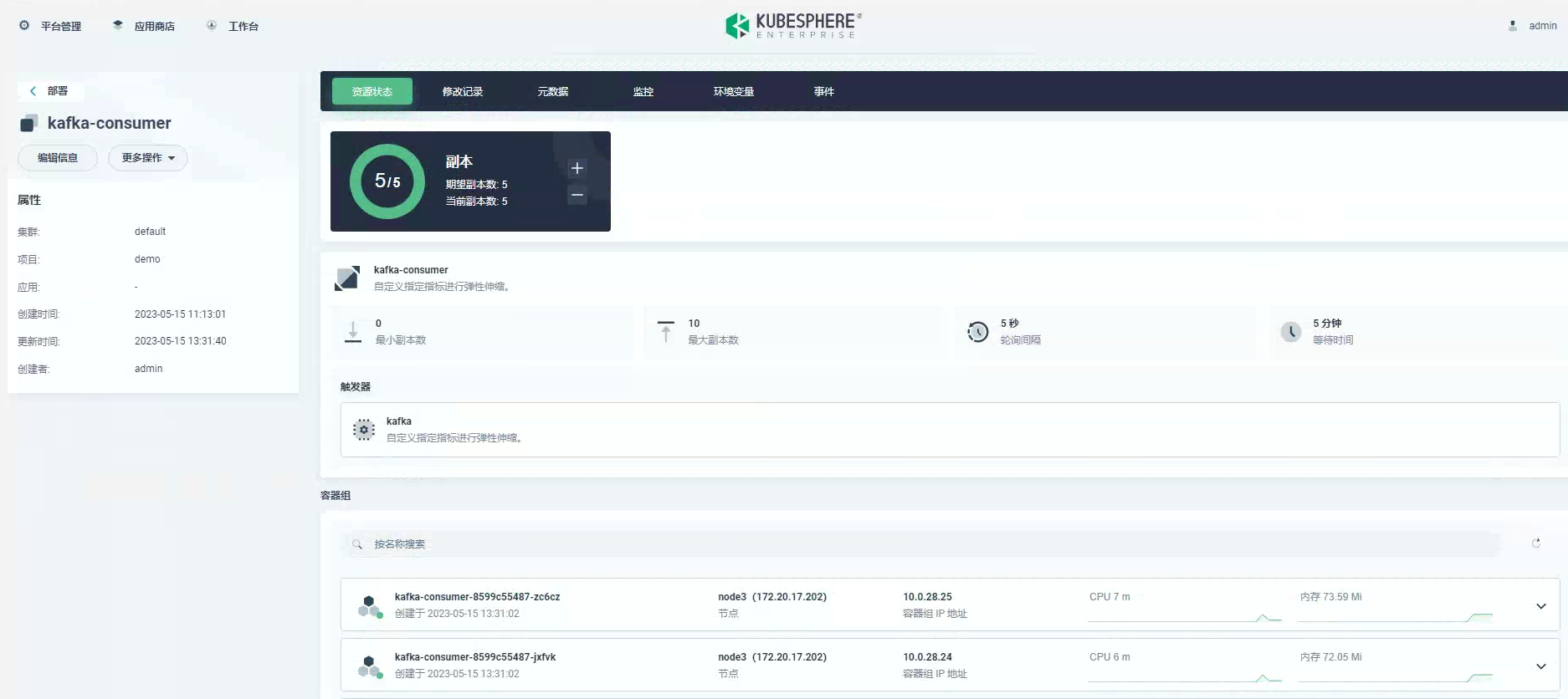
此处我们看到最大到 5 个副本,没有到 10 个副本,因为默认最大副本数不会超过 Kafka 主题分区数量,上面设置了分区为 5,可以激活 allowIdleConsumers: true 来禁用这个默认行为。
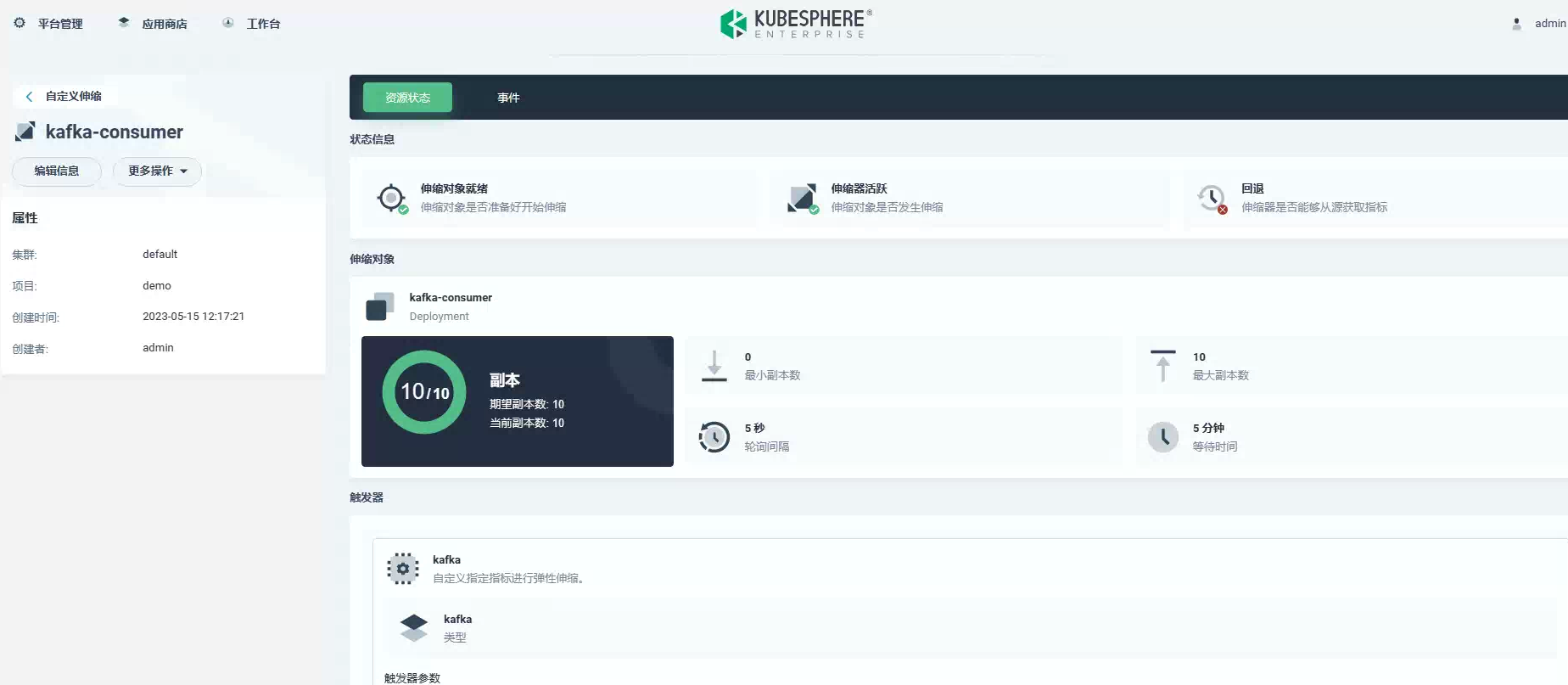
重新编辑自定义伸缩后,最大副本变化成 10:
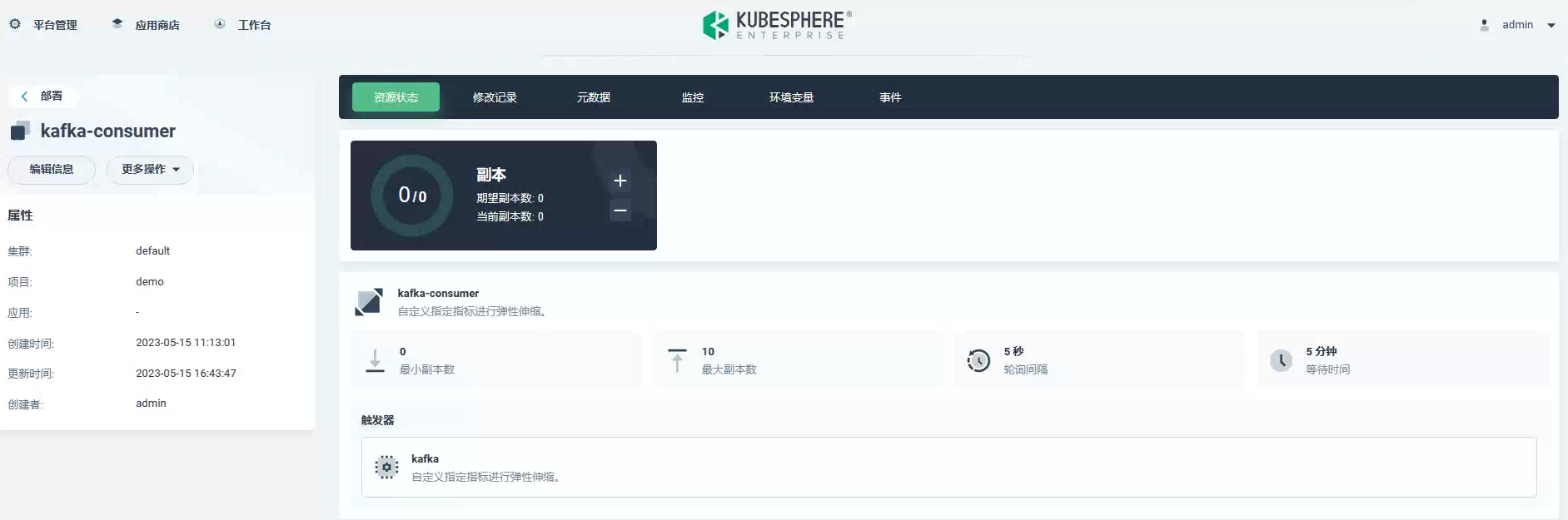
在无消息消费时,副本变化为 0:
结尾
到这里本篇就结束了,对此有需求或感兴趣的小伙伴可以操练起来了。
本文由博客一文多发平台 OpenWrite 发布!